
Введение
Стремительное развитие информационных технологий привело к тому, что сейчас практически все сферы нашей жизни так или иначе связанны с ними. Это приводит к необходимости в создании и размещении высокопроизводительных серверов, которые способны были бы обработать необходимый объем данных и при этом обладали достаточной отказоустойчивостью для обеспечения бесперебойной работы всех завязанных на них приложений. Для обеспечения удовлетворительного уровня отказоустойчивости используют множество различных методов:
- Отсутствие единой точки отказа
- Проектирование с учетом отказов
- Постепенная деградация
- Быстрый отказ
- Разделение ресурсов
Но все эти методы направлены на сохранение работы сервера в случае уже произошедшей ошибки, но не на обнаружение их причины, что является более перспективным и надежным способом обеспечения отказоустойчивости [7]. Раньше обеспечить ранее обнаружение ошибок можно было только с привлечением специалиста, хорошо разбирающегося в созданной инфраструктуре, который вручную провел бы анализ инфраструктуры. Естественно, такой способ довольно дорогой и не даёт 100% гарантии, поэтому с возникновением и активным развитием нейронных сетей многие компании стали задумываться над способом их применения в мониторинге серверов [6].
Методы машинного обучения
Одним из таких способов стало использование методов машинного обучения для обнаружения аномалий в работе оборудование на ранних этапах. Принцип работы этого метода, как ясно из названия, состоит в обнаружении аномалий (значений), которые не соответствуют установленному шаблону нормального поведения [3]. Поиск аномалий происходит по двум направлениям:
1. Обнаружение выбросов – отклонений в исходных данных (рис. 1).
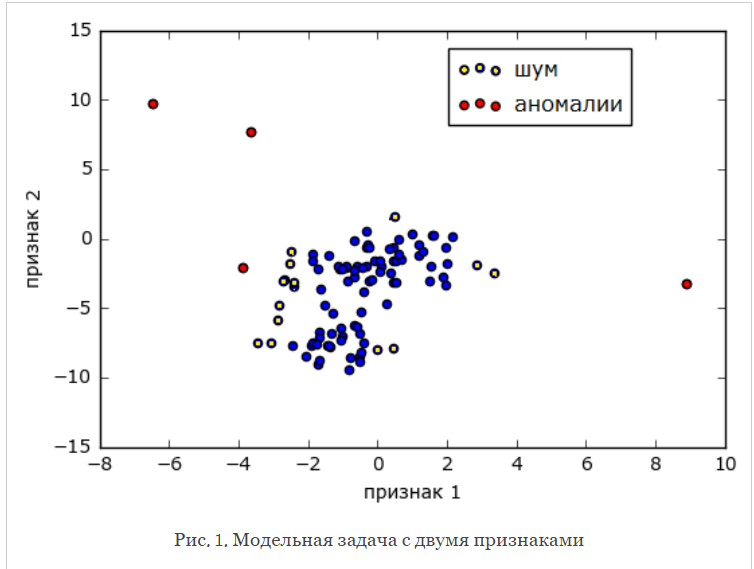
Рис. 1 – обнаружение выбросов в данных
2. Обнаружение новизны – отклонения в добавленных позже данных (рис.2)
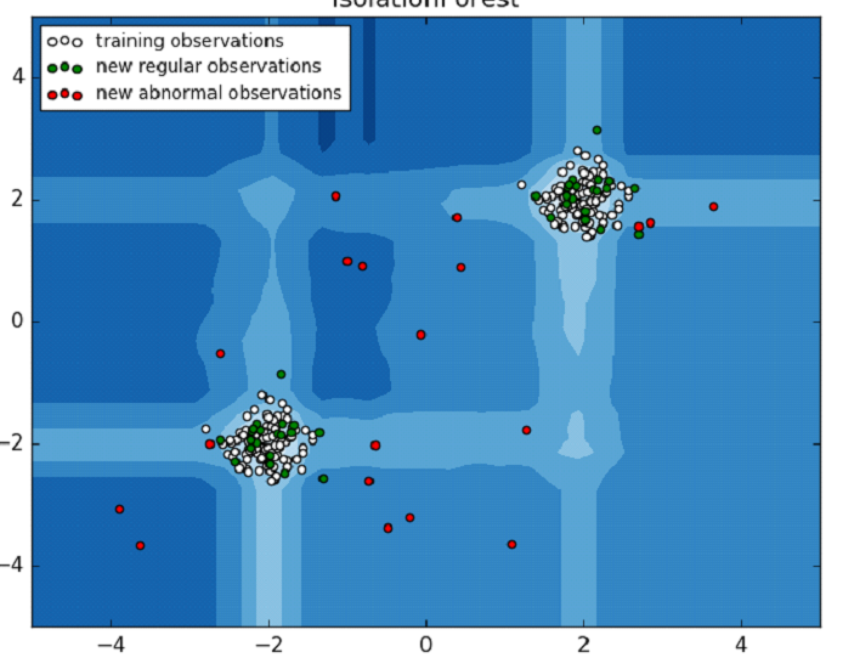
Рис. 2 – обнаружение новизны в данных
А наиболее частыми причинами возникновения аномалий являются: ошибки в данных, скрытые закономерности в наборе данных, шум.
Так как нейронные сети находятся только в начале своего развития, то идеальный метод поиска аномалий еще не был установлен и сейчас используется множество различных вариантов, различающихся как принципом работы, так и сложностью реализации [5].
Самый простой из них это – метод опорных векторов с одним классом. Это алгоритм, основанный на методе обучения с учителем, и может использоваться для задач классификации, регрессии и обнаружения выбросов. Принцип работы метода заключается в нахождении уравнения разделяющей гиперплоскости: w1x1+w2x2+…+wnxn+a0 = 0 в пространстве Rn. Разделить же гиперплоскость должна два класса неким оптимальным образом. Поэтому построить её можно разными способами, но для всех методов опорных векторов веса алгоритмов обучения настраивают таким образом, чтобы объекты классов лежали как можно дальше от разделяющей гиперплоскости. Другими словами, такие объекты называют опорными векторами, откуда и пошло название метода (рис.3)

Рис. 3 – метод опорных векторов
К преимуществам этого метода можно отнести то, что он эффективен для больших размеров данных и когда количество измерений превышает количество исходных данных. Также он довольно универсальный и не требует больших объемов памяти. К недостаткам можно отнести то, что метод не предоставляет напрямую оценки вероятности, поэтому для её расчета необходимо использовать затратную пятикратную перекрёстную проверку [8].
При этом описанный ранее алгоритм подходит при обучении на «нормальных» данных и последующего поиска неизвестных аномалий, но бывают ситуации, когда возможные варианты аномалий уже известны или их можно легко отделить от основных данных. В таком случае гораздо эффективнее использовать метод изолирующего леса. Этот алгоритм основан на методе обучения без учителя, который обнаруживает и изолирует аномалии, обнаруженные в заданном наборе данных. Принцип действия метода заключается в случайном разделении данных между минимальным и максимальным значением, этот процесс повторяется по всему дереву пока не будет достигнуты все возможные разбиения. Таким образом любые аномалии будут отделены на раннем этапе, что и позволяет легко их обнаружить и отделить от остальных данных (рис 4).
Рис. 4 – принцип действия случайного леса
К преимуществам данного метода можно отнести высокую скорость вычислений, достигаемую за счёт обнаружения аномалий на ранних этапах, а также легкую масштабируемость [11].
Ещё одним популярным и довольно простым в использовании является метод «k ближайших соседей». Его суть заключается в работе алгоритма, который по определенным признакам рассчитывает расстояние между уже размеченными и ещё не известными данными. Для корректной работы также необходимо провести первичное обучение алгоритма на определенных расстояниях.
Преимуществом данного метода является его простота реализации и возможность его применения в большинстве задач классификации и регрессии. Но из-за того, что алгоритм основан на принципах «ленивого обучения» он является довольно трудоемким и ресурсозатратным. Также метод довольно плохо справляется с классификаций данных, у которых размерность слишком большего размера [12].
Хоть активное изучение и использования методов машинного обучения началось относительно недавно, но уже сейчас на рынке существует готовые приложения по поиску аномалий в данных для различных сфер жизни. Самые популярные их них это [1]:
- Numenta – приложение способное обнаруживать аномалии в поведении человека, курсе и объеме акций, а так же в работе различных приложений.
- Avora – хранилище данных, которое способно анализировать данные по компании на основе загруженных в него данных
- Splunk Enterprise – приложение для помощи аналитикам в поиске угроз и рисков у компании.
Не смотря на малое количество действительно работающих и полезных приложения на основе технологий машинного обучения, те немногие примеры показывают, что это направление является невероятно перспективным и с каждым годом оно будет только сильнее развиваться. Это также привело к увеличению количества различных научных статей, связанных с машинным обучением. Самые популярные из них:
- Линдигрин А.Н. Анализ специфики и проблематики процессов поиска аномалий в сетевых данных [2]
- Патрик Шнайдер Обнаружение аномалий и сложная обработка событий в потоках данных Интернета [10]
- Бутакова М.А., Гуда А.Н., Чернов А.В. Обнаружение аномалий в информационных потоках и экспериментальные исследования на моделях машинного обучения [9]
- Верескун В.Д., Бутакова М.А., Гуда А.Н., Чернов А.В. Информационно-энтропийные подходы к обнаружению аномалий функционирования в распределенных информационных системах [4]
Заключение
Рассмотрев несколько самых популярных методов машинного обучения, можно смело сказать, что они являются мощным инструментом для обнаружения аномалий. Благодаря этому можно значительно автоматизировать и оптимизировать процессы их поиск, что в свою очередь повысит надежность и отказоустойчивость оборудования, для которого они будут применятся. Но не стоит забывать, что у каждого метода есть свои преимущества и недостатки, из-за которых для каждой задачи стоит подбирать именно тот метод, который будет наиболее эффективным именно в ней. Например, кластеризация позволяет анализировать данные и выявлять группы схожих объектов или событий, которые могут быть аномальными. Деревья решений помогают принимать решения на основе заданных условий и могут обнаруживать аномалии путем анализа последовательности событий.
Однако, методы машинного обучения могут иметь ограничения при обнаружении некоторых видов аномалий. Например, они могут не обнаружить аномалии, которые не имеют явных признаков или проявляются в редких случаях. Также, для эффективного использования методов машинного обучения необходимо иметь достаточное количество данных и уметь правильно их подготовить.
Также не стоит забывать, что сейчас ещё слишком рано полностью полагаться на возможности нейронных сетей и основной контроль и проверку получаемых данных всё ещё должен проводить специалист разбирающейся в конфигурации и особенностях работы конкретного оборудования.
Список литературы
- Top 10 anomaly detection software [Электронный ресурс] https://www.predictiveanalyticstoday.com/top-anomaly-detection-software/, свободный. – Загл. с экрана
- Анализ специфики и проблематики процессов поиска аномалий в сетевых данных [Электронный ресурс] https://cyberleninka.ru/article/n/analiz-spetsifiki-i-problematiki-protsessov-poiska-anomaliy-v-setevyh-dannyh, свободный. – Загл. с экрана
- Детекция аномалий с помощью методов глубокого обучения [Электронный ресурс] https://habr.com/ru/articles/530574/, свободный. – Загл. с экрана
- Информационно-энтропийные подходы к обнаружению аномалий функционирования в распределенных информационных системах [Электронный ресурс] https://elibrary.ru/item.asp?id=37209359, свободный. – Загл. с экрана
- Ищем аномалии и предсказываем сбои с помощью нейросетей [Электронный ресурс] https://habr.com/ru/companies/krista/articles/478392/, свободный. – Загл. с экрана
- Как использовать машинное обучение для обнаружения аномалий и условного мониторинга [Электронный ресурс] https://dzen.ru/a/X9zS04rkhn2tM4J7, свободный. – Загл. с экрана
- Машинное обучение в IT-мониторинге [Электронный ресурс] https://habr.com/ru/companies/netcracker/articles/442620/, свободный. – Загл. с экрана
- Метод опорных векторов [Электронный ресурс] https://scikit-learn.ru/1-4-support-vector-machines/, свободный. – Загл. с экрана
- Обнаружение аномалий [Электронный ресурс] https://www.sciencedirect.com/topics/engineering/anomaly-detection, свободный. – Загл. с экрана
- Обнаружение аномалий в информационных потоках и экспериментальные исследования на моделях машинного обучения [Электронный ресурс] https://elibrary.ru/item.asp?id=43040822, свободный. – Загл. с экрана
- Предсказания от математиков. Разбираем основные методы обнаружения аномалий [Электронный ресурс] https://habr.com/ru/companies/lanit/articles/447190/, свободный. – Загл. с экрана
- Разработка модели обнаружения сетевых аномалий трафика в беспроводных распределенных самоорганизующихся сетях [Электронный ресурс] https://ntv.ifmo.ru/file/article/21350.pdf, свободный. – Загл. с экрана



