
В условиях высокой конкуренции в розничной торговле компании стремятся оптимизировать маркетинговые кампании, минимизируя затраты и увеличивая их эффективность. SMS-рассылки остаются популярным каналом коммуникации с клиентами, однако массовая отправка сообщений может быть экономически неэффективной, особенно если она направлена на клиентов, которые не изменят своё поведение под воздействием рекламы.
Цель данной работы — разработать и сравнить модели uplift-моделирования для предсказания изменения вероятности покупки клиента при получении SMS-сообщения, а также определить наиболее эффективный подход для оптимизации маркетинговых кампаний.
Исследование основано на датасете из соревнования X5 Retail Hero Uplift Modeling Challenge. Датасет включает три основные таблицы:
- clients.csv: информация о клиентах (возраст, пол, даты отправки и использования оффера);
- purchases.csv: история покупок клиентов;
- uplift_train.csv: данные о принадлежности клиента к тестовой или контрольной группе и совершении покупки.
Общий объём данных позволяет проанализировать поведение более 60 000 клиентов, что делает выборку репрезентативной для задач ритейла.
На этапе предобработки были выполнены следующие шаги:
- Временные признаки (даты отправки и использования оффера) переведены в UNIX-время (секунды с 01.01.1970);
- Извлечены дополнительные признаки, такие как задержка между отправкой и использованием оффера (issue_redeem_delay);
- Проведена агрегация транзакционных данных: общее число покупок, количество уникальных товаров, суммы транзакций, начисленные и потраченные баллы лояльности.
После объединения признаков с целевой таблицей была сформирована итоговая выборка для uplift-моделирования. Для анализа были подготовлены две версии набора признаков:
- Первая таблица признаков: базовый набор, включающий возраст, пол, временные метки и задержку между отправкой и использованием оффера.
- Вторая таблица признаков: расширенный набор, дополненный агрегированными транзакционными данными (например, общее число транзакций, уникальные товары, суммы покупок и баллы лояльности).
Для построения моделей применялись следующие методы uplift-моделирования:
- ClassTransformation;
- TwoModels (с модификациями: TwoModels_ddr_control, TwoModels_ddr_treatment);
- Uplift Random Forest;
- SoloModel;
- ClassTransformationRegressor.
Для улучшения качества предсказаний использовался бэггинг (Bagging_Ensemble), объединяющий несколько базовых моделей.
Оценка моделей проводилась с использованием следующих метрик:
- Uplift@k_overall_val: прирост целевого действия (покупки) в верхней части списка (k=30%);
- Overfit: разница между uplift@k на обучающей и валидационной выборках;
- Weighted Average Uplift: средневзвешенный прирост на полной выборке.
Дополнительно применялись визуальные инструменты: кривые Uplift и Qini, позволяющие сравнить эффективность моделей с случайным таргетированием.
На первом этапе были протестированы различные модели на двух наборах признаков (базовом и расширенном). Результаты представлены в таблицах ниже.
Сравнение по метрике uplift@k_overall_val (%):
| Модель | Базовый набор | Расширенный набор | Δ (%) |
|---|---|---|---|
| ClassTransformation | 0.091 | 0.155 | +70.3 |
| TwoModels_ddr_control | 0.101 | 0.135 | +33.9 |
| TwoModels | 0.086 | 0.124 | +43.6 |
| Uplift_RF | 0.092 | 0.104 | +12.8 |
| SoloModel | 0.082 | 0.096 | +16.7 |
| TwoModels_ddr_treatment | 0.042 | 0.084 | +100.0 |
| ClassTransformationRegressor | 0.101 | 0.111 | +9.9 |
Сравнение по метрике overfit (%):
| Модель | Базовый набор | Расширенный набор | Δ (%) |
|---|---|---|---|
| ClassTransformation | 0.400 | 0.413 | +3.3 |
| TwoModels_ddr_control | 0.127 | 1.356 | +967.7 |
| TwoModels | 0.751 | 2.560 | +240.9 |
| Uplift_RF | 0.550 | 0.718 | +30.6 |
| SoloModel | 0.236 | 0.122 | -48.3 |
| TwoModels_ddr_treatment | 1.036 | 2.525 | +143.7 |
| ClassTransformationRegressor | 0.224 | 2.523 | +1026.3 |
Ключевые выводы:
- 6 из 7 моделей показали рост uplift@k_overall_val на расширенном наборе признаков (средний прирост — +39.5%).
- По метрике overfit базовый набор оказался лучше (средний рост overfit на расширенном наборе — +201.8%).
- SoloModel продемонстрировала улучшение по обеим метрикам: uplift@k вырос на +16.7%, а overfit снизился на -48.3%.
Для дальнейшего повышения качества была применена техника бэггинга (Bagging_Ensemble), объединяющая несколько базовых моделей. Итоговые результаты представлены ниже:
| Модель | uplift@k_overall_val | uplift@k_overall_train | overfit |
|---|---|---|---|
| Bagging_Ensemble | 0.160987 | 0.406561 | 1.525 |
| ClassTransformation | 0.155259 | 0.219429 | 0.413 |
| TwoModels_ddr_control | 0.135333 | 0.318856 | 1.356 |
| TwoModels | 0.124791 | 0.444303 | 2.560 |
| SoloModel | 0.096060 | 0.107826 | 0.122 |
Анализ результатов бэггинга:
- Bagging_Ensemble достигла наивысшего значения uplift@k_overall_val (0.160987), что на +3.7% выше предыдущего лидера (ClassTransformation).
- Метрика overfit составила 1.525, что выше, чем у SoloModel (0.122), но ниже, чем у TwoModels (2.560).
- Средневзвешенный прирост (weighted_average_uplift) на полной выборке составил 0.0322.
Кривые Uplift и Qini демонстрируют эффективность моделей по сравнению со случайным таргетированием. На графиках видно, что Bagging_Ensemble обеспечивает наибольший прирост числа инкрементальных покупок при увеличении числа таргетированных клиентов.
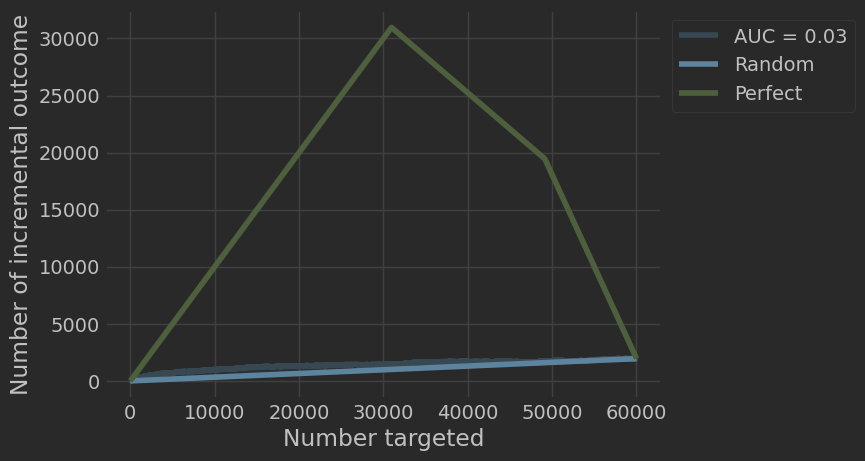
Uplift curve
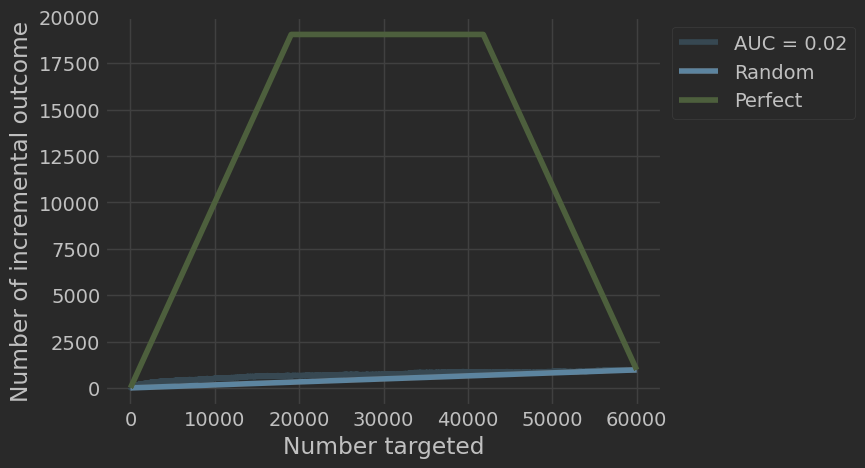
Qini curve
Сравнительный анализ моделей uplift-моделирования показал, что использование различных подходов позволяет эффективно оптимизировать SMS-кампании в ритейле, направляя воздействия на клиентов, наиболее склонных к изменению поведения. Наилучший результат (uplift@k = 0.160987) был достигнут с помощью ансамбля Bagging_Ensemble, что подчеркивает преимущества комбинирования моделей. Однако модели, такие как SoloModel и ClassTransformation, показали лучшее поведение с точки зрения переобучения, что делает их предпочтительными в задачах, где важна стабильность.
Список литературы
- Uplift modeling: как предсказать влияние на пользователя, если воздействие еще не произошло [Электронный ресурс] // Хабр. — URL: https://habr.com/ru/companies/ru_mts/articles/485980/ (дата обращения: 10.02.2025)
- Uplift modeling: предсказываем вероятность покупки [Электронный ресурс] // Хабр. — URL: https://habr.com/ru/companies/ru_mts/articles/485976/ (дата обращения: 10.02.2025)
- Uplift-моделирование: как мы научились предсказывать реакции пользователей на скидки [Электронный ресурс] // Хабр. — URL: https://habr.com/ru/companies/ru_mts/articles/538934/ (дата обращения: 10.02.2025)



