
Движение сырья, товаров и запчастей лежит в основе любой производственной системы. После революции в области вычислительной техники и информационных технологий стало понятно, что такое физическое движение может быть оптимально эффективным только тогда, когда оно точно контролируется механизмом обработки информации, Таким образом, инновационная комбинация аппаратного и программного обеспечения привела «старые отрасли» в эру интеллектуального производства.
Инновационные идеи в области искусственного интеллекта и машинного обучения должны повысить эффективность деятельности крупных предприятий, сократить издержки по срочному ремонту оборудования, а также повысить точность выполнения задач, так как на ИИ не влияет «человеческий фактор».
Все задачи, решаемые с помощью Machine Learning, относятся к одной из следующих категорий.
1) Задача регрессии – прогноз на основе выборки объектов с различными признаками. На выходе должно получиться вещественное число.
2)Задача классификации – получение категориального ответа на основе набора признаков (например, ответ «да» или «нет».
3)Задача кластеризации – распределение данных на группы, отнесение к той или иной категории.
4)Задача уменьшения размерности – сведение большого числа признаков к меньшему (обычно 2–3) для удобства их последующей визуализации.
Основная масса задач, решаемых при помощи методов машинного обучения, относится к двум разным видам: обучение с учителем (supervised learning) либо без него (unsupervised learning). «Учитель» в терминах машинного обучения – это вмешательство человека в процесс обработки информации. В обоих видах обучения машине предоставляются исходные данные, которые ей предстоит проанализировать и найти закономерности. Различие лишь в том, что при обучении с учителем есть ряд гипотез, которые необходимо опровергнуть или подтвердить.
Выделяют несколько алгоритмов моделей машинного обучения: дерево принятия решений, наивная байесовская классификация, логистическая регрессия, метод ансамблей, алгоритмы кластеризации, сингулярное разложение и другие.
Исходя из информации, представленной выше, можно отнести рассматриваемую задачу акустического мониторинга производственных процессов к задачам кластеризации, модель обучается без учителя, с помощью алгоритмов кластеризации.
Аудиоанализ — область, включающая автоматическое распознавание речи (ASR), цифровую обработку сигналов, а также классификацию, тегирование и генерацию музыки — представляет собой развивающийся поддомен приложений глубокого обучения.
Для создания модели используется Google Collaborаtory - облачный сервис на основе Jupyter Notebook. Google Colab предоставляет всё необходимое для машинного обучения прямо в браузере, даёт бесплатный доступ к невероятно быстрым GPU и TPU.
В Google Collab есть специальная библиотека librosa для анализа музыки и аудио. Для обработки аудиофайлов используют их спектрограммы, которые формируются путем оконного преобразования Фурье. Например, так выглядит спектрограмма пневматической дрели после обработки указанной библиотекой (рис.1):
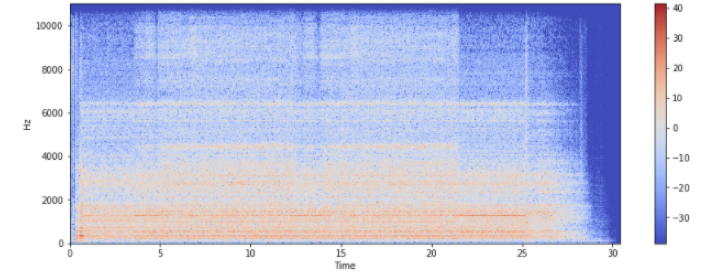
Рисунок 1. Спектрограмма звука пневматической дрели
Каждый аудиосигнал состоит из множества признаков. Рассмотрим признаки, которые относятся к поставленной задаче. Спектральные (частотные) признаки получаются путем конвертации временного сигнала в частотную область с помощью преобразования Фурье. К ним относятся частота основного тона, частотные компоненты, спектральный центроид, спектральный поток, спектральная плотность, спектральный спад и др [1].
Спектральный центроид указывает, на какой частоте сосредоточена энергия спектра или, другими словами, указывает, где расположен «центр масс» для звука. Рассчитывается по формуле 1:
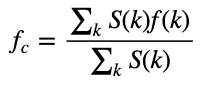 (1)
(1)
где S(k) — спектральная величина элемента разрешения k;
f(k) — частота элемента k.
Библиотека librosa предоставляет возможность вычислять спектральный центроид для каждого фрейма в сигнале с помощью функции librosa.feature.spectral_centroid (рис. 2):
audio_data = '/content/drive/My Drive/machine/norm/01113.mp3'
x , sr = librosa.load(audio_data)
import sklearn
spectral_centroids = librosa.feature.spectral_centroid(x, sr=sr)[0]
spectral_centroids.shape
(775,)
# Вычисление временной переменной для визуализации
plt.figure(figsize=(20, 10))
frames = range(len(spectral_centroids))
t = librosa.frames_to_time(frames)
# Нормализация спектрального центроида для визуализации
def normalize(x, axis=0):
return sklearn.preprocessing.minmax_scale(x, axis=axis)
# Построение спектрального центроида вместе с формой волны
librosa.display.waveplot(x, sr=sr, alpha=0.4)
plt.plot(t, normalize(spectral_centroids), color='b')
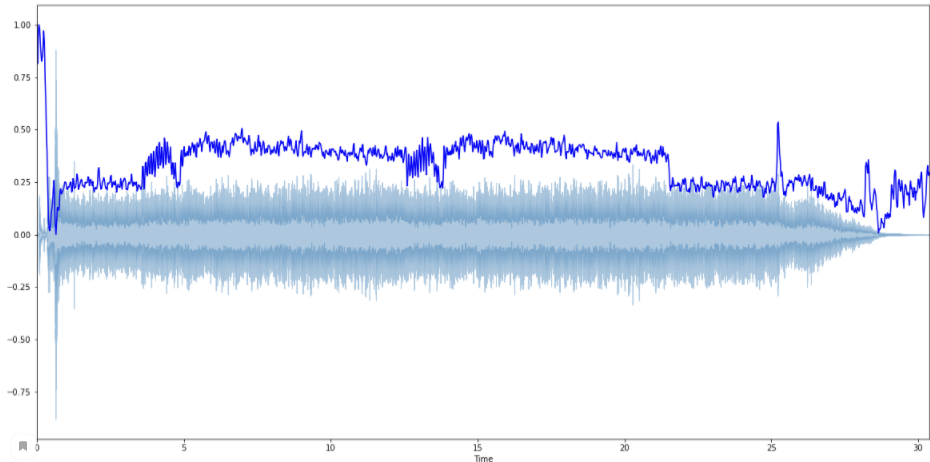
Рисунок 2. Признак спектрального центроида
.spectral_centroid возвращает массив со столбцами, равными количеству фреймов, представленных в семпле.
Скорость пересечения нуля - скорость изменения знака вдоль сигнала, то есть скорость, с которой сигнал изменяется с положительного на отрицательный или обратно. Вычисляется по формуле 2:
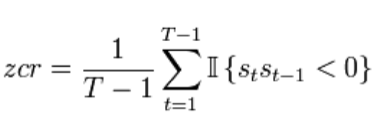 (2)
(2)
где St — сигнал длины t,
II{X} — функция-индикатор (=1 if X true, else =0).
Теперь визуализируем этот процесс и рассмотрим вычисление скорости пересечения нуля (рис. 3).
x, sr = librosa.load('/content/drive/My Drive/machine/norm/01113.mp3')
# Построение графика сигнала:
plt.figure(figsize=(14, 5))
librosa.display.waveplot(x, sr=sr)
# Увеличение масштаба:
n0 = 9000
n1 = 9100
plt.figure(figsize=(14, 5))
plt.plot(x[n0:n1])
plt.grid()
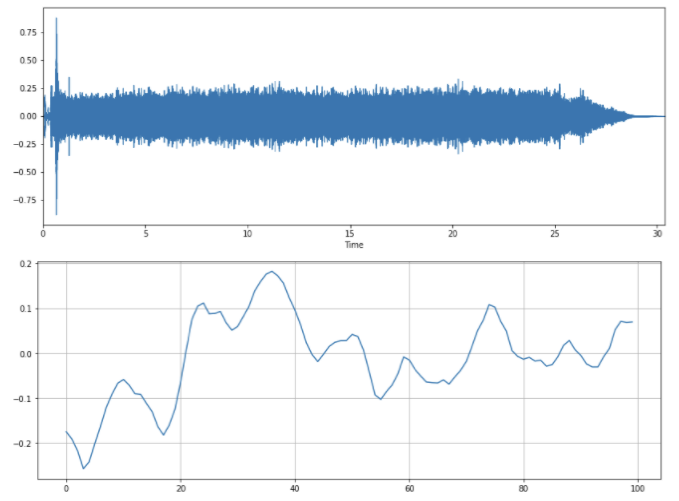
Рисунок 3. Признак скорости пересечения нуля
С помощью Librosa отобразим количество пересечений нуля на втором графике (рис. 4):

Рисунок 4. Количество пересечений нуля
Построим графики изменения значений точности и потерь на обучающем наборе данных (рис. 5).
acc = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(EPOCHS)
plt.figure(figsize=(20, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Точность на обучении')
plt.legend(loc='lower right')
plt.title('Точность на обучающем наборе')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Потери на обучении')
plt.legend(loc='upper right')
plt.title('Потери на обучающем наборе')
plt.show()
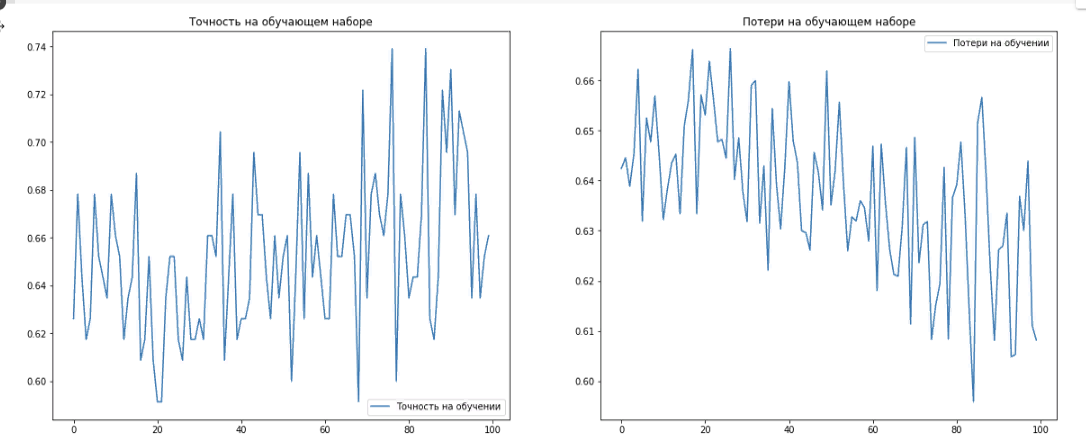
Рисунок 5. График обучения модели
Что интересно здесь, так это то, что результаты на обучающем наборе данных можно охарактеризовать как относительно положительными: точность растет, потери падают.
Чтобы запустить процесс машинного обучения, необходимо загрузить в компьютер некоторое количество исходных данных, на которых алгоритм будет учиться обрабатывать запросы. После процесса обучения, программа уже сама должна распознавать изображения, которые имеют признаки поломки, некорректной работы оборудования. Важно отметить, что процесс обучения продолжается и после выданных прогнозов, чем больше данных будет проанализировано программой, тем более точно она распознает нужные изображения.
В Python существует модуль под названием split-folders, с помощью которого можно быстро разделить датасет на тренировочную и тестовую выборки. 80% данных будет использоваться для обучения и 20% для тестирования [1].
В параметре ratio перечислено, какой процент исходных данных будет содержаться в папках «train» и «test» соответственно. Все переданные в ratio значения должны находиться в промежутке [0,1]. Соответственно, нужные нам 80% будут переданы в ratio, как 0.8, 20% — как 0.2.
Приведенный выше код возвращает две директории для обучающего и тестового набора в родительскую (рис. 6):
Рисунок 6. Разделение данных на тренировочный и валидационный наборы
Следующим шагом является создание структуры нейронной сети. Для входного слоя нам нужно 64 узла, чтобы покрыть 64 пикселей изображения. Выходной слой будет занимать 3 узла. Также потребуется скрытый слой в нашей сети. Обычно, количество узлов в скрытых слоях не менее и не больше количества узлов во входном и выходном слоях.
Созданная модель состоит из 3 блоков свёртки после каждого из которых следует блок со слоем активации.
Перед последним полносвязным слоем мы так же применяем исключение со значением вероятности 0.5. Это означает, что 50% значений, поступающих на вход этому слою, будут сброшены до 0. Это позволит избежать переобучения.
Используя метод summary() можно увидеть структуру модели по уровням, изображенную на рисунке 7.

Рисунок 7. Структура обучаемой модели
После обработки входных данных (преобразование в картинку, аугментация) можно создавать свёрточную сеть с помощью стохастического градиентного спуска (SGD). Затем подгоняем модель со 100 эпохами, и определяем оценку работы модели. На данном этапе точность работы созданной модели составляет 62%.
Результат обучения представлен на рисунке 8.
Рисунок 8. Результат обучения модели
Для повышения точности модели необходимо увеличить количество входных данных и эпох обучения [3].
Резюмируя вышесказанное: в ходе работы была разработана модель машинного обучения с помощью сервиса Google Collab. Созданная модель должна анализировать звуки работы промышленного оборудования с целью мониторинга состояния объектов, при котором оно не может выполнять предназначенные функции и поддерживать заданный уровень производительности. Проведено тестирование работы модели с последующей оценкой точности (полученное значение – 62%).
С увеличением объемов производства растет количество затрат на контроль этого производства. В этот момент можно вводить в бизнес машинное обучение. Системы, основанные на глубоком обучении могут отслеживать характер потребления ресурсов в зависимости от сотен параметров технологического процесса и параметров конструкции продукта и могут динамически рекомендовать лучшие практики для оптимального использования.
Список литературы
- James Montantes. An Overview of Deep Learning Applications in Manufacturing | Exxact/ James Montantes, 2019. — URL: https://www.exxactcorp.com/blog/Deep-Learning/deep-learning-for-manufacturing-overview-applications
- Документация по librosa 0.8.1 / URL: https://librosa.org/doc/main/generated/ librosa.feature.chroma_stft.html
- Комаров, П. В. Cравнительный анализ и выбор оптимальной архитектуры нейросети для предсказания и детекции плохо различимых объектов / П. В. Комаров, В. В. Сокольников, В. В. Ветохин // Перспективные научные разработки: Труды Всероссийской научно-технической конференции, Воронеж, 20 июня 2019 года. – Воронеж: ООО "НАУЧНОЕ ИЗДАТЕЛЬСТВО ГУСЕВЫХ", 2019. – С. 36-41.



