
Введение
IPFS — контент-адресуемая сеть, где каждому фрагменту данных соответствует криптографический хеш (CID) [1], что позволяет проверять целостность. При доступе через HTTP-шлюзы проверка по умолчанию не выполняется: браузер доверяет ответу вида https://gateway/ipfs/{CID}, что создаёт риск подмены и слежения. Использование публичного шлюза без верификации — анти-паттерн, противоречащий принципу «не доверяй, а проверяй»; без сверки с CID преимущества контент-адресации теряются (например, подмена фронтенда dApp) [1][2][3].
Корневой CID выступает «якорем доверия»: зная его, пользователь локально хеширует полученные блоки и подтверждает соответствие, обеспечивая end-to-end целостность даже при промежуточных кешах и небезопасном транспорте. Ранее из-за отсутствия нативной поддержки IPFS в браузерах полагались на доверие к шлюзам; сейчас сообщество продвигает верифицируемую (trustless) выборку как стандарт [2][4][5], чтобы реализовать устойчивость, цензуроустойчивость и снижение роли доверия.
В статье разобраны: механика Merkle-DAG и частичной выборки; архитектуры шлюзов (поток выдачи, диапазоны, кеши, защита); интеграция с вебом/CDN (DNSLink, ETag по CID, trustless поверх HTTP); клиенты и ограничения; практики и минимальные SLO; открытые вопросы (приватность маршрутизации, частичные доказательства, метрики качества).
1. Механика верифицируемой выборки
1.1. Контент-адресация и Merkle-DAG
В основе IPFS лежит структура Merkle-DAG [1] – ориентированный ацикличный граф, в узлах которого хранятся блоки данных, а ссылки представляют хеши других блоков. Каждый файл при добавлении в IPFS разбивается на блоки (как правило, по 256 КБ или другой размер в пределах до 1 МБ), для каждого блока вычисляется хеш. Если файл состоит из нескольких блоков, формируется корневой блок-узел [1], содержащий ссылки (хеши) на эти блоки, зачастую древовидно (UnixFS v1 строит дерево с промежуточными узлами при больших файлах). В итоге на вершине получается CID корневого узла – уникальный идентификатор всего файла или директории. Эта схема означает, что каждый кусок данных доказуемо связан с корневым CID: зная хеш корня, можно проверить целостность всего поддерева. Пользователь, имея доверенный CID (например, полученный от автора контента), может загрузить набор блоков из любого источника и убедиться [1], что: (a) каждый блок соответствует своему хешу (то есть не поврежден), (b) хеши блоков правильно ссылаются друг на друга вплоть до корня, давая точно тот CID, который ожидался. Таким образом достигается trustless-выборка: данные могут быть получены с произвольного узла/IPFS-шлюза, но им не нужно доверять – корректность проверяется криптографически на стороне клиента.
1.2. Верификация на узлах и на шлюзах
Если пользователь запускает полноценный IPFS-нод (например, Kubo) локально, то при ipfs get CID или подобной команде узел автоматически хеширует полученные блоки и сверяет их с ожидаемыми значениями [2], гарантируя, что собранный файл соответствует исходному CID. При использовании же HTTP-шлюза ситуация сложнее: базовый режим работы шлюза – отдавать файл целиком по HTTP – не предполагает автоматической проверки в браузере. Браузер скачивает файл как обычный ресурс и не знает, каким должен быть хеш, чтобы сверить. В результате верификация становится опциональной: либо пользователь вручную проверит хеш (на практике почти никто этого не делает), либо остается «доверять» шлюзу. Именно эту проблему и решает режим trustless gateway. Спецификация Trustless Gateway определяет подмножество функциональности HTTP-шлюзов, при котором ответы формируются исключительно в верифицируемом виде. Иными словами, шлюз либо возвращает сырые блоки (content-type application/vnd.ipld.raw) – по одному блоку на запрос, строго по запрошенному CID, – либо стримит CAR-файл (content-type application/vnd.ipld.car) с набором блоков Merkle-DAG. В обоих случаях клиент способен локально проверить целостность полученных данных: в первом – просто вычислив хеш полученного блока и сравнив с запрошенным CID, во втором – провалидировав всю цепочку внутри CAR-файла до корневого CID запрошенного контента. Никакой десериализации UnixFS/IPLD на стороне шлюза не происходит – он не превращает DAG в обычный файл, а отдает именно контент-адресованные блоки. Это ключевой момент: шлюз в trustless-режиме выступает «тупым» ретранслятором данных IPFS, не интерпретируя их – за сборку файла из блоков и его отображение отвечает уже клиент. Например, запрашивая через trustless-шлюз CID директории или файла, можно получить поток CAR, включающий метаданные UnixFS и сами содержимые блоки, а браузер/приложение с помощью IPFS-библиотеки восстановит из этого структуру (список файлов или байтовый контент файла). В результате достигается конечная цель: даже используя обычный HTTP/HTTPS, клиент не доверяет серверу-шлюзу, а верифицирует полученные данные локально по Merkle-DAG. Схематично такой процесс показан на рис. 1: шлюз лишь извлекает контент-адресованные блоки, а пользователь сверяет их с корневым CID самостоятельно.
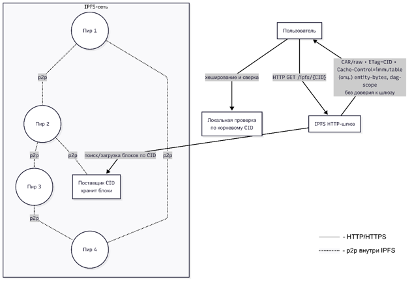
Рисунок 1. Trustless-доставка через IPFS-шлюз
Пользователь делает HTTP-запрос по контент-адресу (CID) и получает от шлюза «сырые» блоки Merkle-DAG, которые затем проверяются локально вычислением хеша и сверкой с корневым CID. Это устраняет необходимость доверять шлюзу, так как целостность данных гарантируется алгоритмически на стороне клиента.
1.3. Частичная выборка и доказуемость кусков
Одно из ключевых преимуществ контент-адресации — запрос части файла с сохранением верификации. В отличие от обычного HTTP Range [3], trustless-шлюз использует параметр entity-bytes при запросе CAR: GET /ipfs/<CID>?format=car&entity-bytes=1024:2047 вернёт минимальный набор блоков и необходимые промежуточные узлы, достаточные, чтобы (a) собрать указанный диапазон и (b) проверить его целостность по Merkle-ссылкам до корневого CID. По сути, это проверяемый Range-запрос: тянем не весь файл, а только нужный фрагмент, сохраняя гарантию корректности.
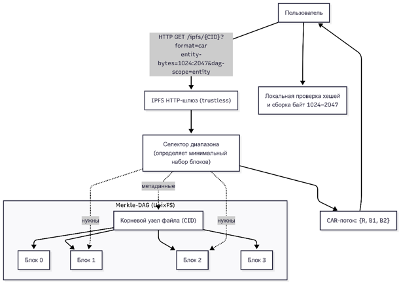
Рисунок 2. Возвращаются только попавшие в диапазон блоки и корневые метаданные
Entity-bytes поддерживает синтаксис как у HTTP Range (начала/концы, отрицательные смещения, «*» для конца). Если диапазон выходит за пределы, шлюз отдаёт доступную часть или 400 при некорректности; ETag при частичной выдаче меняется (включает признак диапазона) — это обеспечивает уникальность кэша для разных фрагментов [6]. Тем самым trustless-механизм покрывает не только полные выдачи по CID, но и произвольные подвыборки — критично для больших медиа и ленивой загрузки.
«Доказуемость кусков» означает, что любой фрагмент сопровождается криптографическим контекстом: зная корневой CID, клиент запрашивает у шлюза набор доказательств (блоков) и локально проверяет включение фрагмента в Merkle-DAG. Шлюз — лишь провайдер доказательств, а не источник истины; любая подмена обнаруживается на стороне клиента (принцип Don’t trust — verify) [1].
2. Архитектуры шлюзов
2.1. Потоковая выдача блоков
Эффективная передача множества блоков в trustless-шлюзе достигается CAR-потоком: последовательная выдача корневых CID и «сырых» блоков DAG (как всего дерева, так и части через dag-scope) [5]. Шлюз может стримить CAR по мере получения данных из IPFS-сети, что снижает TTFB и позволяет клиенту параллельно начинать верификацию/обработку.
Порядок блоков в CAR должен быть детерминированным (для кэшей) [6], хотя спецификация допускает разные варианты. У стриминга есть нюанс: если в конце обнаружится отсутствие блока/ошибка пути, HTTP-статус уже отправлен (200 OK), поэтому реализация либо помечает неполноту в CAR, либо аккуратно формирует ответ. В итоге шлюз действует как прозрачный туннель (без интерпретации контента), упрощая логику и повышая безопасность.
2.2. Запросы с указанием диапазона DAG
Параметр dag-scope задаёт глубину выгрузки в CAR: block — только запрошенный объект (без дочерних); entity — минимальный набор блоков для реконструкции сущности (файл/директория); all — весь поддерев рекурсивно [2]. По умолчанию — all. Пример: ...&dag-scope=entity вернёт файл целиком или список директории без вложенных; для директории all отдаст её полностью. Для файлов entity ≡ all; различие важно именно для директорий. Шлюз помечает ETag префиксом с выбранным dag-scope, чтобы варианты не смешивались в кэше. Итого, dag-scope позволяет запрашивать минимально достаточный объём данных и экономить трафик/нагрузку.
2.3. Кэширование и pre-warm
Публичные IPFS-шлюзы обычно выступают и кэшами: получив данные по CID [1], они сохраняют их в blockstore/файловом кэше и при повторных запросах выдают сразу, без поиска пиров. Это критично для быстродействия: по измерениям Cloudflare кэшированный контент отдаётся ~за 116 мс, тогда как «свежий» требует заметно больше времени на обнаружение и загрузку. Trustless-режим полностью совместим с HTTP-кэшированием: шлюз возвращает ETag и Cache-Control. Для неизменяемых /ipfs/{CID} уместно Cache-Control: public, max-age=29030400, immutable; ETag обычно равен CID (или CID с префиксом dag-scope). Клиент с If-None-Match избегает повторной загрузки и получает 304 Not Modified, если CID не изменился.
Для ускорения применяют pre-warming: заранее прогревают кэш ожидаемым популярным контентом (например, ключевые файлы dApp — HTML/JS), а также могут автоматически подтягивать смежные куски (например, при частых entity-bytes). Но агрессивный prefetch стоит дозировать, чтобы не расходовать ресурсы впустую и не качать объёмы, которые пользователи так и не запросят.
2.4. Защита от злоупотреблений
Открытый шлюз уязвим для злоупотреблений [5]: DDoS, запросы к случайным (несуществующим) CID, огромные диапазоны entity-bytes. Нужны лимиты: на одновременные запросы и трафик с IP, на размер CAR и максимальный размер выдачи; валидация параметров (dag-scope, entity-bytes) и отклонение «нарезки» сотнями перекрывающихся диапазонов. Контент-рутинг следует ограничивать таймаутами: если за заданное время данные не найдены, возвращать ошибку (например, 524), чтобы не держать слоты и не искать несуществующий контент.
Также важны меры против сайд-каналов по метаданным: по последовательности частичных запросов можно косвенно понять интерес пользователя. HTTPS защищает от внешнего перехвата, но не скрывает паттерны от самого шлюза; техник микширования/«шумных» запросов пока нет. Практический минимум — минимизировать раскрытие информации: не передавать явные имена файлов (CID их не содержит) и использовать субдоменный режим, чтобы скрыть, какой сайт запрашивает контент.
3. Интеграция с вебом и CDN
3.1. DNSLink и кастомные домены
Одно дело — получить данные по CID, другое — встроить процесс в привычный веб. Пользователи не оперируют CID напрямую, контент обычно привязан к доменам. Для этого есть DNSLink: TXT-запись в DNS, указывающая на CID/IPNS (например, _dnslink.blog.example.com TXT "dnslink=/ipfs/<CID>"), благодаря чему по blog.example.com открывается сайт из IPFS. Шлюзы поддерживают DNSLink, что даёт прозрачные для пользователя URL.
Недостаток: DNSLink фактически привязывает домен к выбранному шлюзу (если использовать форму example.com), что ведёт к централизации и риску недоступности при сбое/блокировке [7]. Рекомендуется иметь резервные варианты (свой шлюз/альтернативы) и публиковать сам CID для обходных сценариев.
3.2. Изоляция origins: subdomain gateways
Ключевой нюанс — политика единого происхождения (Same-origin). В path-режиме (например, ipfs.io/ipfs/<CID>) разные сайты имеют один origin, что опасно: скрипт одного IPFS-сайта может получить доступ к данным другого [3].
Решение — субдоменный шлюз с CID в хосте: https://<CID>.ipfs.dweb.link или http://<CID>.ipfs.localhost:8080. Каждый контент получает свой origin; это рекомендовано для production, изолирует cookies/localStorage и полностью совместимо с trustless (можно запрашивать CAR через Accept: application/vnd.ipld.car). Аналогично работают субдомены для IPNS/DNSLink. Итог: интеграция IPFS с вебом должна следовать модели безопасности браузера, а subdomain-gateways — ключевой инструмент.
3.3. HTTP-заголовки кэширования (ETag, Cache-Control)
Как отмечалось ранее, правильная установка HTTP-заголовков – основа эффективности trustless-доставки. Выстроим кратко «шпаргалку» важных заголовков и их роль [6]:
Таблица 1.
HTTP-заголовки
|
Заголовок HTTP |
Назначение в контексте trustless-доставки |
|
Accept / format |
Клиентский запрос верифицируемого формата. С помощью заголовка Accept: application/vnd.ipld.car или параметра URL ?format=car запрашивается CAR-поток, либо Accept: application/vnd.ipld.raw / ?format=raw – сырой одиночный блок. Это сигнал шлюзу отключить преобразование данных и выдать контент-адресованные блоки. |
|
Content-Type |
Тип ответа, указывающий на формат содержимого. Trustless-шлюз возвращает либо application/vnd.ipld.raw (для одиночного блока), либо application/vnd.ipld.car; version=1 (для CAR-файла с версией). Дополнительно, Content-Disposition всегда ставится в attachment, чтобы браузеры не пытались отобразить бинарный поток, а отдавали его пользовательскому приложению (например, IPFS-компоненту на странице). |
|
ETag |
Уникальный идентификатор кеша для данного контента. В случае IPFS целесообразно использовать CID в качестве ETag, возможно с префиксом, указывающим режим (например, W/"CID-entity" или подобное). |
|
Cache-Control |
Политика кеширования. Для неизменяемых /ipfs/ ресурсов желательно указывать public, max-age=<большое время>, immutable, чтобы браузеры и промежуточные узлы могли долго хранить ответ. (Например, immutable сигнализирует, что содержимое никогда не изменится, т.к. CID уникален). |
|
X-Ipfs-Roots |
Специфичный для IPFS заголовок, содержащий список корневых CID, относящихся к ответу. Например, при запросе DNSLink сайта он перечисляет CID корня IPNS и итоговый контент-CID. Это помогает при каскадном кешировании: CDN или прокси может различать контент по уникальным root-CID. Также клиентские приложения могут использовать этот список для доп. проверки или логирования. |
|
If-None-Match (запрос) |
Условный запрос от клиента с указанием ранее полученного ETag. В сочетании с ETag от CID позволяет реализовать проверку свежести: шлюз сравнит ETag и, если контент по CID не изменился, вернет 304 Not Modified без тела. |
В совокупности эти заголовки позволяют встроить trustless-доставку в стандартные механизмы веб-кеширования и контент-дистрибуции. Шлюзу важно корректно проставлять их, особенно ETag и Cache-Control, а прокси и CDN – уважать их.
3.4. Trustless поверх HTTP и CDN
HTTPS пока необходимо: браузеры не умеют p2p напрямую. В trustless-подходе HTTP/HTTPS — лишь транспорт; поверх него можно ставить CDN (Cloudflare/CloudFront) перед публичным или собственным шлюзом [5][6], кешируя CAR/raw по URL. Так как контент идентифицируется CID и неизменяем, кеширование безопасно. Важно настроить заголовки: отключить трансформации у CDN, учитывать Accept/Range (или ключ кэша равен полный URL), сохранять ETag; X-Ipfs-Roots при желании помогает формировать ключи.
На клиенте можно использовать Service Worker: перехватывать запросы к шлюзу, тянуть блоки через Helia/verifiedFetch с локальной верификацией, кешировать в IndexedDB и параллельно запрашивать один и тот же CID с нескольких шлюзов, выбирая самый быстрый.
Как итог, «trustless поверх HTTP» сочетает скорость и инфраструктуру HTTP/CDN с целостностью и децентрализацией IPFS. Пользователь получает привычный веб, но проверяет данные локально; для dApp это критично. Полного избавления от доверия нет (остаётся браузер/источник CID/криптопримитивы), но роль посредников сведена к минимуму.
4. Клиенты и ограничения
4.1. Браузерные клиенты (WASM/IndexedDB)
Запустить полноценный IPFS-нод в браузере нельзя: среда не даёт слушать порты, свободно устанавливать P2P-соединения и держать большие объёмы данных. Поэтому используют лёгкие JS/TS-имплементации, прежде всего Helia (эволюция js-ipfs), работающую в браузере (JS/WASM) и дающую API для контент-адресного хранения и верифицируемой выборки [2][4]. Транспорты два: (a) Bitswap по WebRTC/WebTransport — попытка подключения к пирам напрямую; (b) Trustless Gateway по HTTPS — запрос CAR/raw у шлюза с последующей локальной проверкой. Из-за ограничений браузеров (лимиты соединений, отсутствие TCP/UDP в libp2p, требования TLS и т.п.) прямой P2P затруднён; помогают delegated routing и новые API (WebTransport, WebRTC Direct), но их поддержка ещё ограничена. На практике чаще полагаются на trustless-шлюзы; удобный слой — @helia/verified-fetch: fetch(CID) получает CAR/raw через шлюз и возвращает Response с гарантией целостности (ошибка при несовпадении хеша).
Ограничения браузерного trustless-клиента:
- CPU-накладные расходы: хеширование множества блоков (SHA-256/DAG-PB) может нагружать слабые устройства; ускоряет WASM [2][5].
- Хранение: кэш ограничен (IndexedDB/память, квоты), вкладки живут недолго → это в основном клиент «для чтения», не для длительной раздачи.
- Сеть и CORS: нужны корректные CORS на своём шлюзе; публичные обычно выставляют Access-Control-Allow-Origin: *.
- Интеграция с UI: без локального узла нет прозрачной обработки ipfs://; либо спецбраузер (Brave), либо логика внутри приложения (обработка ссылок).
4.2. Мобильные и серверные клиенты
На мобильных (iOS/Android) действуют браузероподобные ограничения: sandbox мешает полноценному p2p (особенно на iOS) [2][4][5]. Варианты: встроить лёгкий IPFS-нод в нативное приложение (реальнее на Android) и получать верификацию как на десктопе; либо в web-view/PWA — жить с ограничениями браузера. Допустим и серверный прокси: приложение запрашивает свой сервер-нод, который проверяет контент, — добавляет доверие к своему серверу, но может быть приемлемо.
Серверы в лучшем положении: запускают полноценный нод (или лёгкий клиент типа go-car) и берут данные напрямую из IPFS, без HTTP-шлюзов. При обращении к публичным шлюзам (для ускорения, HTTP/3/CDN) стоит использовать trustless-режим и импортировать CAR с проверкой корневого CID.
4.3. Узкие места и обход их
Узкие места и как их сгладить:
- Задержки при множестве ресурсов: параллельная загрузка/проверка, мультисорсинг — опрашивать несколько шлюзов и/или свой узел и брать самый быстрый.
- Пропускная способность: потоковое хеширование по мере поступления данных, распараллеливание проверки в Web Workers [1][2][4].
- Память: сразу освобождать проверенные блоки; при случайном доступе кэшировать лишь необходимую часть.
- Сборка из множества блоков: по возможности читать напрямую из CAR; для медиа — плеер, понимающий IPFS-блоки.
- Обновления: при IPNS/ENS/DNSLink — короткий TTL (~60 с) и логика обновления на стороне приложения/Service Worker [7].
Таким образом, верифицируемая доставка в браузере реалистична (Helia, delegated routing, WebTransport), но требует больше инженерии; для массовых кейсов практичнее связка trustless-шлюзы и лёгкие клиенты. Подход Brave с локальным узлом удобен энтузиастам, но не масштабируется на большинство пользователей.
4.4. Практики и анти-паттерны
Внедряя trustless-доставку, соблюдайте практики, сохраняющие проверяемость, и избегайте анти-паттернов.
Что ломает проверяемость:
- Отсутствие верификации: прямые ссылки вида https://<gateway>/ipfs/CID без проверки на клиенте — антипаттерн. Используйте Verified Fetch/клиентскую проверку; минимум — надёжный публичный шлюз и subdomain-URL [1].
- Преобразование на шлюзе: только non-recursive режим; не рендерить директории/не вставлять скрипты (любой немеркл-детерминированный шаг недопустим).
- Трансформации в CDN/прокси: запретить сжатие/перекодирование для CAR/raw (Cache-Control: no-transform) [1][6].
- Неверный формат: всегда запрашивать verifiable (Accept: application/vnd.ipld.car или raw). Разумно блокировать неверифицируемые ответы (400/редирект) [1][4].
- IPNS/DNS: проверять подписи IPNS; для DNSLink по возможности использовать DNSSEC [7].
- Внешние зависимости: критичные файлы включать в IPFS-бандл; внешние запросы — криптографически аутентифицировать/проверять хеш.
Приватность и метаданные:
- Не отправлять токены/куки на публичные шлюзы; обращаться без авторизации. Использовать субдоменный режим, при необходимости чередовать шлюзы/источники; для повышенной приватности — Tor/VPN (с учётом скорости) [8].
- Понимать, что паттерны частичных запросов могут выдавать интерес пользователя — готовых «шумящих» защит пока нет.
- Для чувствительных данных применять шифрование контента (публиковать зашифрованный CID, ключи — только авторизованным): шлюз выдаёт зашифрованные блоки, клиент после проверки хешей расшифровывает локально — совместимо с trustless-доставкой.
4.5. Минимальные SLO для шлюза
Минимальные SLO для trustless-шлюза таковы: доступность не ниже 99,9% (резервирование, мониторинг, оперативные оповещения); производительность на уровне CDN — быстрые кэш-хиты и быстрый контент-рутинг, мгновенная ошибка для неподдерживаемых CID, постоянный контроль и оптимизация TTFB и общей длительности для сценариев hit/miss/редкий; безопасность — недопустимы «неправильные» ответы и смешение блоков, предотвращаются HTTP Response Splitting и XSS, в ответах задаются Content-Disposition: attachment и X-Content-Type-Options: nosniff; пропускная способность и масштабируемость обеспечиваются лимитами per-IP, горизонтальным масштабированием за балансировщиком и геораспределёнными узлами; необходима ясная документация и поддержка с описанием режимов (обычный/trustless), лимитов и контактов. Ключевой анти-паттерн эксплуатации — монополизация одним шлюзом: приложениям следует предусматривать fallback на несколько gateway, пользователям — знать альтернативы; trustless-режим облегчает переключение.
5. Открытые вопросы
Несмотря на значительный прогресс в реализации trustless-доставки, остаются открытые вопросы и области для улучшений:
5.1. Приватность маршрутизации и запросов
Как обсуждалось, сейчас шлюз видит, какой CID запрашивает пользователь, и знает его IP-адрес. Хотелось бы добиться более приватного способа получения контента. Возможное направление – обфускация запросов (например, через специальные микс-сети для IPFS или интеграция с анонимными транспортами) [4][5]. Существуют исследования по использованию Tor для IPFS, но они не широко применены. Также, в самой IPFS-сети поисковые запросы по DHT видны узлам – это тоже проблема (пиры могут логировать, кто что искал). Открытым остается вопрос: можно ли получить контент-адресные данные, не раскрывая свой интерес никому конкретно? Вероятно, потребуются протоколы подобные анонимным запросам или dHT с шифрованием запросов. Пока же, практический совет – использовать комбинацию разных источников (разных шлюзов, пиров) и, при необходимости, VPN/Tor.
5.2. Частичные proofs и оптимизация DAG-передачи
Сейчас trustless-доставка опирается на передачу реальных блоков данных. Но возможно развитие концепции в сторону криптографических доказательств без передачи данных. Например, могла бы быть возможность убедиться, что удаленный узел имеет определенные данные, попросив у него лишь Merkle-доказательство без всего содержимого (полезно для огромных файлов, когда важна лишь проверка наличия). Частично это решает протокол Filecoin с Proof-of-Spacetime, но применительно к on-demand retrieval пока нет стандартного решения [8]. Еще один аспект – легкость клиентских доказательств: можно ли дать очень «тонкому» клиенту (IoT, смарт-контракт) возможность верифицировать кусочек без хранения всего DAG? Потенциально, да, если разработать формат компактных меркл-путей. Это направление для будущих исследований.
5.3. Стандартные метрики качества доставки
В вебе давно существуют метрики вроде Largest Contentful Paint (LCP), Time to Interactive и т.д. Для IPFS-доставки стоит определить аналогичные показатели: например, Time To Verify (TTV) – время до полной криптографической проверки ресурса; Content Availability – доля запросов, завершившихся успехом за X секунд; Redundancy Score – сколько альтернативных источников было доступно для данного CID [4][5]. Если сформировать такие метрики, это позволит сравнивать разные шлюзы и подходы, выявлять узкие места и прогресс. Пока же каждый провайдер меряет свое (как Cloudflare запустил Gateway Monitor). Стандартизация метрик помогла бы стимулировать улучшения и прозрачность. Например, публичные шлюзы могли бы публиковать свой SLА – среднее время отдачи популярного контента, процент кеш-хитов, и т.п.
5.4. Дальнейшее развитие IPFS-протокола
Trustless-доставка – лишь часть большого паззла. Впереди вопросы индексирования контента (чтобы находить CID, по ключевым словам), распределенной репликации (чтобы контент всегда где-то был доступен), стимулы для хранения (Filecoin и подобные уже работают над этим) [1][2]. Все эти направления тесно связаны: например, когда появятся децентрализованные индексеры, trustless-клиент сможет сразу узнавать, на каких шлюзах/пирах есть нужный контент и параллельно скачивать. Или, если контент зашифрован, может потребоваться интегрировать это с trustless-верификацией. Но в рамках данной статьи мы не углубляемся в темы индексирования и репликации, фокусируясь на механизмах доставки и проверки. Тем не менее, очевидно, что trustless-подход закладывает фундамент для этих будущих улучшений: он обеспечивает, чтобы любой дальнейший уровень (поисковый, хранилищный) не вносил недоверенных компонентов.
Заключение
Развитие trustless-доставки в IPFS ознаменовало важный шаг на пути к по-настоящему децентрализованному вебу. Мы показали, как контент-адресация и Merkle-DAG превращают HTTP-шлюз из потенциально уязвимого посредника в прозрачный канал передачи блоков, которому не нужно доверять, а локальная проверка по CID даёт пользователю уверенность, что он получил именно опубликованный контент [1][2]. Это особенно критично для dApp, финансовых платформ и распределённых архивов, где целостность данных напрямую связана с безопасностью и достоверностью.
Trustless-подход потребовал изменений в архитектуре шлюзов (поддержка raw-блоков и CAR, потоковая раздача, частичные запросы) и тонкой настройки HTTP-интеграции (корректные заголовки кэширования, субдоменные решения для безопасности) [3][6]. Важное преимущество в том, что эти улучшения накладываются поверх существующей веб-инфраструктуры: пользователь по-прежнему открывает привычный URL, а «под капотом» происходит проверка по хешам.
Практический опыт уже подтверждён: библиотеки Helia и Verified Fetch, интеграции в браузерах (Brave, IPFS Companion) и массовое включение trustless-режима на публичных шлюзах показывают востребованность подхода [4][5]. Остаются проблемные места — производительность на слабых устройствах и неполная анонимность запросов, — но они выглядят разрешимыми за счёт оптимизаций ПО и развития сетевых протоколов и криптопримитивов.
Важно помнить, что trustless-доставка — не цель сама по себе, а средство повышения надёжности и децентрализации: обеспечив целостность каждого фрагмента, сообщество может сосредоточиться на доступности и удобстве (индексация, стимулирование хранения, лучшая совместимость с браузерами). В итоге trustless-шлюзы и проверяемая выборка смещают парадигму «от доверия к проверке», возвращая контроль над данными пользователям и минимизируя роль посредников; уже сегодня это повышает устойчивость приложений и задаёт основу для будущих систем распределённой сети данных.
Список литературы
- Benet J. IPFS — Content Addressed, Versioned, P2P File System. arXiv, 2014. DOI: 10.48550/arXiv.1407.3561
- Trautwein D., Raman A., Tyson G., Castro I., Scott W., Schubotz M., Gipp B., Psaras Y. Design and Evaluation of IPFS: A Storage Layer for the Decentralized Web. ACM SIGCOMM ’22 / arXiv, 2022. DOI: 10.1145/3544216.3544232; arXiv:2208.05877
- Fielding R., Nottingham M., Reschke J. (eds.) RFC 9110: HTTP Semantics. IETF STD 97, 2022. DOI: 10.17487/RFC9110
- Shi R., Cheng R., Han B., Cheng Y., Chen S. A Closer Look into IPFS: Accessibility, Content, and Performance. Proceedings of the ACM on Measurement and Analysis of Computing Systems (POMACS / SIGMETRICS), 8(2), 2024. DOI: 10.1145/3656015
- Wei Y., Trautwein D., Psaras Y., Castro I., Scott W., Raman A., Tyson G. The Eternal Tussle: Exploring the Role of Centralization in IPFS. USENIX NSDI ’24, 2024. (Proc. 21st USENIX NSDI)
- Fielding R., Nottingham M., Reschke J. (eds.) RFC 9111: HTTP Caching. IETF, 2022. DOI: 10.17487/RFC9111
- Fotiou N., Siris V. A., Polyzos G. C. Enabling self-verifiable mutable content items in IPFS using Decentralized Identifiers. IFIP Networking 2021 Workshop DI2F / arXiv, 2021. DOI: 10.48550/arXiv.2105.08395
- Benet J., et al. Filecoin: A Decentralized Storage Network. Whitepaper / Protocol Labs, 2017. (Proof-of-Replication, Proof-of-Spacetime)

