
ВВЕДЕНИЕ
Многомерные базы данных, известные как MOLAP (Multidimensional Online Analytical Processing), представляют собой специализированные системы для хранения и обработки данных, позволяющие осуществлять сложный анализ и предоставлять доступ к данным в многомерном формате. Главная цель MOLAP — повысить производительность, удобство и скорость анализа данных. В таких системах данные организованы в многомерные кубы, где каждое измерение соответствует атрибуту данных (таким как время, продукт или регион), а факты представляют собой числовые показатели, например, продажи или прибыль. Данная технология используется в разных направлениях, где требуется анализ больших наборов данных [5], предполагающих наличие сложных агрегатов, включая финансовую отрасль, маркетинг, управление запасами.
Очевидно, что процессы бизнес-анализа могут включать в себя размытые и нечеткие требования. Данные условия нельзя представить в виде строгого числового значения (множества), но можно выразить в виде лингвистических переменных, например «высокая прибыль», «малая выручка», «среднее количество». При этом, области определения нечетких множеств, выражающих лингвистические переменные, будут различаться для каждого процесса бизнес-анализа.
В данной статье рассказывается о разработке комплексного решения, позволяющего учитывать потребность анализа многомерных данных при помощи нечеткой логики и нечетких запросов.
ОСНОВНАЯ ЧАСТЬ
1. Методология и используемые технологии
Существует несколько подходов к определению нечетких лингвистических переменных. Один из них заключается в том, что лингвистическая переменная определяется как кортеж вида <a, X, A>, где a — представляет собой обозначение нечеткой переменной; X — это область определения, а A — функция, которая описывает возможные значения, которые может принимать эта переменная. Иными словами, лингвистическая переменная подразумевает наличие нечеткого множества, заданного с помощью функции принадлежности, которая определяет возможные значения для этой переменной.
Существуют типовые функции принадлежности, которые могут быть использованы для определения некоторых нечетких лингвистических переменных. Например, для выражения неопределенности вида «подобен объекту». «находится в диапазоне» подходят трапециевидные и треугольные функции принадлежности (Рис. 1).
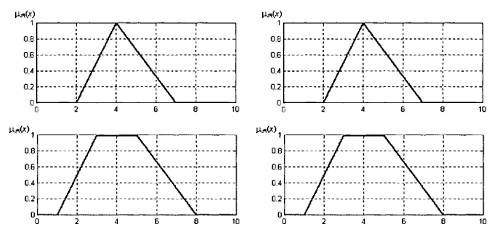
Рисунок 1. Графическое представление треугольной и трапециевидной функций принадлежности
Трапециевидная функция принадлежности в общем случае может быть записана в следующем аналитическом виде (1):
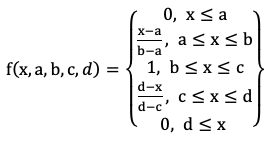 (1)
(1)
Комплексное программного обеспечение, позволяющего проводить бизнес-анализ многомерных данных с помощью нечеткой логики и нечетких запросов состоит из нескольких подзадач:
- Разработка DWH, которое будет являться источником, данным для многомерного куба;
- реализация ETL-процесса;
- реализация модуля, назначением которого является хранение нечетких лингвистических переменных и применение нечетких запросов к многомерному кубу данных, отправка результата клиентской части приложения;
- разработка многомерного куба данных;
- создание интерфейса, позволяющего бизнес-аналитику формировать нечеткие запросы к многомерному хранилищу.
2. Разработка многомерного хранилища и его источника информации
Структура Datawarehouse, являющаяся источником данных для MOLAP-куба реализована по методологии «Звезда». Данный вид построения хранилища данных предполагает наличие двух основных сущностей: таблица фактов и таблица измерений.
Таблица фактов предполагает наличие одной и более колонок дающих числовую характеристику определенному аспекту, например показывает сумму выручки за заказ клиента. Таблица измерения же расшифровывает остальные ключи, на которые ссылается таблица фактов, например какие товары приобрел клиент за заказ.
Для отображения информации о продажах торгового предприятия, рассматриваемого в данной статье, была реализована следующая структура таблиц в ХД (Рис. 2), а для пополнения хранилища данных из некоторой транзакционной БД, реализовано регламентное задание на языке C#.
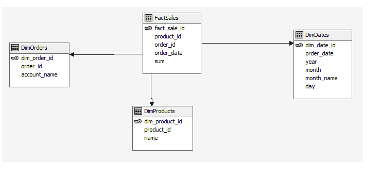
Рисунок 2. Структура таблиц в хранилище данных
Таким образом, проектируемый куб продаж будет содержать три измерения «Дата», «Заказ» и «Продукт» (Рис. 3) и две меры (Рис. 4). При этом, измерение «Дата» должно содержать пользовательскую иерархию вида «Год – месяц - день» для более удобной навигации по многомерному хранилищу.
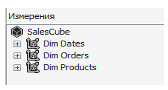
Рисунок 3. Измерения куба продаж
Рисунок 4. Меры куба продаж
3. Разработка модуля хранения нечетких лингвистических переменных и применения нечетких запросов
Рассмотрим хранение нечетких лингвистических переменных, создаваемых пользователями через клиентскую часть программного обеспечения на примере определения вида <a, X, A>, то есть одиночного нечеткого терм-множества. Для вычисления степени принадлежности значений мер тому или иному нечеткому множеству [4] необходимы следующие параметры: название нечеткой лингвистической переменной, минимальный порог соответствия функции принадлежности, идентификатор разреза куба (для которого создавалась переменная), название меры (для которой будет применяться вычисления значения функции принадлежности), массив точек на плоскости (используемый для кастомизации функции принадлежности). Таким образом, для хранения одиночных нечетких лингвистических переменных вида <a, X, A> необходимы две таблицы (Рис. 5), первая из которых предназначена для хранения основной информации, вторая же – для хранения точек, которые «настраивают» функцию принадлежности. Стоит отменить, что саму формулу функции принадлежности в базе данных хранить не стоит, достаточно записать ее идентификатор, так как вычисление значений степеней принадлежности будет совершать серверная часть приложения.
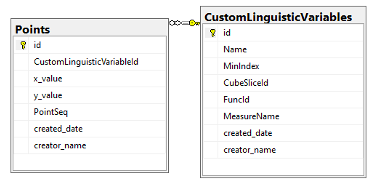
Рисунок 5. Структура хранилища нечетких лингвистических переменных
Применение нечеткой логики к многомерным хранилищам представляет собой сложную задачу для языка MDX, который используется для доступа к данным [1]. Инструкции этого языка позволяют выполнять только узкоспециализированные задачи, такие как навигация по многомерному кубу и получение данных в определенных разрезах. Для решения этой проблемы можно использовать трехзвенную архитектуру приложения, состоящую из компонентов (MOLAP – Server – Client). В таком случае, сервер может применять сложную логику, которую нельзя выразить на языке MDX, к данным, получаемым из многомерного куба. Клиентская часть приложения будет получать только ту информацию, которая была обработана и проверена на сервере. При этом скорость обработки и получения данных будет сопоставима со скоростью выполнения «нативных» MDX-запросов.
Таким образом, при построчной обработке информации (с возможностью распараллеливания логических операций), которая включает в себя вычисление значений функций принадлежности и последующую фильтрацию серверной частью, будет достигнута высокая производительность.
Обычно, для построчной обработки данных, получаемых серверной частью от базы данных, в стеке технологий .NET используется некоторый объект, реализующий интерфейс IDataReader, именно в этот момент и можно применить нечеткий запрос, отправляемый пользователем.
Листинг 1 – Применение нечеткого запроса многомерных данных модулем серверной части
public static List<T> ToList<T>(this IDataReader dr, CustomLinguisticVariable variable, FuzzyFunctionData funcData)
where T : class, IMolapItem
{
var list = new List<T>();
while (dr.Read())
{
var obj = Activator.CreateInstance<T>();
var filterResult = true;
double? result = null;
foreach (var prop in obj!.GetType().GetProperties())
{
var columnDescription = GetPropertyDescription(obj, prop.Name);
if (columnDescription == ExcludedProperty)
continue;
if (columnDescription == variable.MeasureName)
{
var columnOrdinal = dr.GetOrdinal(columnDescription!);
var value = dr[columnOrdinal];
result = funcData.MemberShipFunction(variable!.Points!.OrderBy(item => item.PointSeq).Select(item => item.XValue).ToArray(), Convert.ToDouble(value));
if (result < variable.MinIndex)
{
filterResult = false;
break;
}
}
if (ExistsDataReaderColumn(dr, columnDescription!))
CopyColumnValueToProperty(dr, obj, prop);
}
if (!filterResult)
continue;
if (result is not null)
obj.FuzzyResults =
obj.FuzzyResults.Append(new (variable.Name,(double)result));
list.Add(obj);
}
return list;
}
4. Разработка интерфейса бизнес-аналитика
Выбор технологий и способа реализации интерфейса зависит от следующих факторов, предъявляемых крупными торговыми предприятиями:
- Обеспечение информационной безопасности (авторизация, права пользователей, шифрование трафика);
- легкость развертывания ПО;
- регулярная и бесперебойная доставки обновлений;
- отсутствие границ в кастомизации программного комплекса под нужды бизнеса.
В данном случае, выбор был сделан в пользу реализации интерфейса в виде защищенного веб-ресурса. В первую очередь, была реализована система аутентификации и авторизации по методологии Cookie-based (Рис. 6). Данные учетных записей пользователей хранятся в отдельной БД, а пароли, в виде значений хэш-функций.
Рисунок 6. Интерфейс регистрации и авторизации
После прохождения процесса авторизации, пользователю портала отображается один из разрезов куба продаж, который визуализирует значения агрегатов количества продаж и выручки в разрезе времени (по месяцам) за 2023 г.
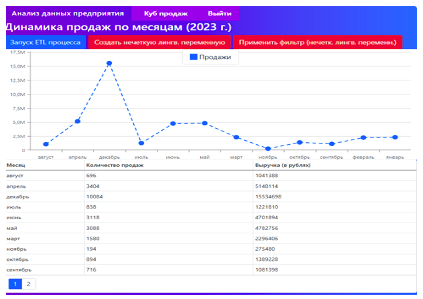
Рисунок 7. Разрез куба продаж, отображаемый на веб-ресурсе
В верхней части веб-интерфейса бизнес-аналитику предоставлена функциональность для создания нечетких запросов к многомерному кубу данных. Рассмотрим процесс создания нечеткого запроса вида «ВЫВОД [Месяцев 2023 года] ГДЕ [Количество продаж] = Среднее». Для формирования запроса такого вида бизнес-аналитику подойдет определение одиночной нечеткой лингвистической переменной (Рис. 8), выраженной с помощью трапециевидной функции принадлежности. Допустим, что бизнес-аналитик считает, что среднее количество продаж за месяц определяется следующими заключениями по мере «количество»: 300 – не среднее (соответствие 0%), 400-600 – точно среднее (соответствие 100%), 800 – не среднее (соответствие 0 %). «Настроенная» функция принадлежности и основные характеристики нечеткой лингвистической переменной «Среднее количество продаж» с помощью веб-интерфейса представлены на (Рис. 9).
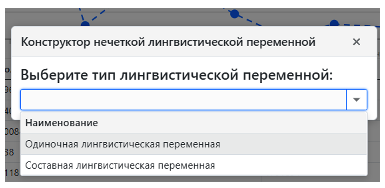
Рисунок 8. Выбор типа нечеткой лингвистической переменной
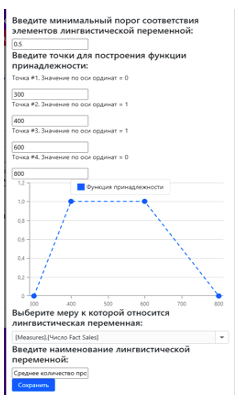
Рисунок 9. Основные характеристики нечеткой лингвистической переменной «Среднее количество»
После сохранения нечеткой лингвистической переменной в модуль, предназначенный для хранения нечетких терм-множеств и применения нечетких запросов, информация в базе данных выглядит следующим образом (Рис. 10).
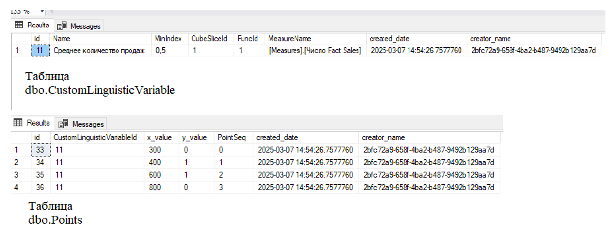
Рисунок 10. Отображение хранения информации о нечеткой лингвистической переменной «Среднее количество продаж» в БД
Следующим шагом, является создание нечеткого запроса по заранее сформированным нечетким лингвистическим переменным. Выберем созданную переменную в окне «Применить фильтр по нечетким лингвистическим переменным» (Рис. 11).
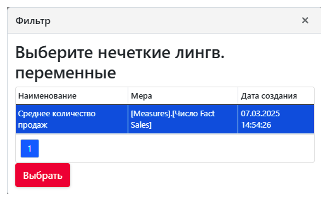
Рисунок 11. Выбор созданной нечеткой лингвистической переменных для фильтрации MOLAP-данных
Результатом применения фильтра будет являться одна строка из MDX-выборки (Рис. 12), степень соответствия меры «Количество» которой удовлетворяет условиям нечеткого запроса.
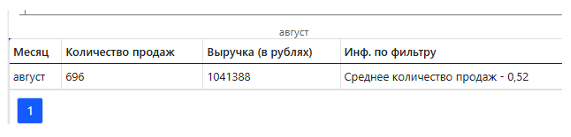
Рисунок 12. Результат выполнения нечеткого запроса
ЗАКЛЮЧЕНИЕ
Таким образом, MOLAP-системы представляют собой мощные инструменты для анализа многомерных данных, которые помогают пользователям эффективно обрабатывать и интерпретировать большие объемы информации. Их структура, основанная на многомерных кубах, позволяет анализировать данные с различных точек зрения, что полезно во многих областях бизнеса. С учетом того, что процессы бизнес-анализа часто сопровождаются нечеткими требованиями, использование лингвистических переменных становится важным для адекватного отражения реалий, таких как неопределенности и субъективные оценки. Таким образом, интеграция нечеткой логики в MOLAP-системы может значительно расширить возможности анализа, позволяя более точно учитывать и обрабатывать сложные бизнес-метрики, что, в свою очередь, повысит качество принимаемых решений и оптимизацию бизнес-процессов.
Список литературы
- Федоров, Алексей; Елманова, Наталья Введение в OLAP-технологии Microsoft; М.: Диалог-МИФИ. - Москва, 2011. - 268 c.
- Lam, H. & Chung, Sai-Ho & Lee, C. & Ho, G.T.s & Yip, T.K.T. (2009). Development of an OLAP Based Fuzzy Logic System for Supporting Put Away Decision. International Journal of Engineering Business Management. 1. 1. 10.5772/6779
- Veryha, Yauheni. (2002). Implementation of Fuzzy Classification Query Language in Relational Databases Using Stored Procedures. 195-202
- Лисицына Л.С., Основы теории нечетких множеств– СПб: Университет ИТМО, 2020. – 74 с.
- Эргашев Аслон Акрамович, Садикова Фируза Сафаровна СПОСОБЫ И МЕТОДЫ АНАЛИЗА МНОГОМЕРНОГО БАЗЫ ДАННЫХ // Universum: технические науки. 2021. №12-1 (93). URL: https://cyberleninka.ru/article/n/sposoby-i-metody-analiza-mnogomernogo-bazy-dannyh



