
Системы обработки текстовых данных (СПТД) занимают важное место в области обработки естественного языка (NLP, от англ. Natural Language Processing), и их применимость охватывает такие сферы, как поиск информации, автоматический перевод, анализ настроений, чат-боты, обработка медицинских и юридических текстов. Для оценки качества работы этих систем важны как теоретические, так и практические методы и инструменты, которые позволяют точно и эффективно оценить их производительность, точность и надежность. Оценка качества СПТД является необходимым этапом для понимания того, насколько эффективно они решают поставленные задачи и соответствуют ожиданиям пользователей.
Целью данной статьи является обзор инструментов и методов, используемых для оценки качества работы СПТД, а также определение ключевых показателей, которые следует учитывать при проведении оценки.
Для понимания методов оценки качества СПТД важно сначала выделить основные типы задач, которые решаются с помощью этих систем. Наиболее часто встречаются следующие категории задач:
- Классификация текста — процесс определения категории, к которой относится данный текст. Пример: классификация новостных статей по тематикам.
- Извлечение информации — выделение структурированных данных из неструктурированного текста. Пример: извлечение имен людей и мест из документов.
- Анализ настроений — определение эмоциональной окраски текста (положительный, отрицательный, нейтральный).
- Перевод текста — автоматический перевод текста с одного языка на другой.
- Ответ на вопросы — создание системы, способной отвечать на вопросы на основе текстов, обычно с использованием методов поиска по корпусу данных.
- Обработка текста для создания аннотаций или суммаризаций — автоматическое выделение основных идей из текста.
Каждая из этих задач требует разных подходов к оценке качества работы системы, поскольку показатели качества зависят от специфики задачи.
Выделяют несколько метрик для оценки качества систем обработки текстовых данных:
Точность (Precision) и полнота (Recall)
Точность и полнота являются одними из самых популярных метрик для оценки эффективности системы в задачах классификации и извлечения информации.
- Точность (Precision) измеряет долю правильно классифицированных объектов среди всех объектов, отнесенных системой к определенному классу. Для задачи классификации это может быть доля правильно классифицированных позитивных примеров:
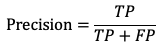
где
TP — количество истинно положительных;
FP — количество ложноположительных примеров.
- Полнота (Recall) показывает, какую долю всех объектов, которые должны быть отнесены к определенному классу, система на самом деле отнесла к этому классу:
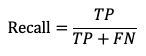
где
FN — количество ложноположительных примеров.
В идеале система должна стремиться к высокой точности и полноте, однако часто между ними существует компромисс. Для этого существует метрика F1-меры, которая является гармоническим средним точности и полноты:

PR-кривая (Precision-Recall curve) и ROC-кривая (Receiver Operating Characteristic curve) используются для оценки систем, работающих с вероятностными оценками. PR-кривая строится для задач, где важна классификация по уровням вероятности, а ROC-кривая используется для задач бинарной классификации.
Метрики средняя абсолютная ошибка (MAE) и среднеквадратичная ошибка (RMSE) применяются в задачах, где необходимо предсказать числовое значение, например, в задаче прогнозирования. Средняя абсолютная ошибка (MAE) измеряет среднее отклонение предсказанных значений от истинных значений:
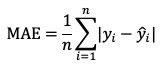
где  — истинные значения,
— истинные значения,  — предсказанные значения, n — количество элементов.
— предсказанные значения, n — количество элементов.
Среднеквадратичная ошибка (RMSE) является более чувствительной к крупным ошибкам:
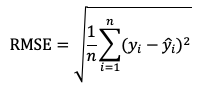
Для оценки качества машинного перевода одной из самых популярных метрик является BLEU. Эта метрика измеряет, насколько предсказанный перевод совпадает с эталонным переводом. BLEU вычисляется как средняя гармоническая точность n-грамм (от 1- до 4-грамм).
Для оценки качества суммаризации текста часто используется метрика ROUGE, которая оценивает, насколько хорошо сгенерированные аннотации или резюме совпадают с эталонными. ROUGE включает в себя различные метрики, такие как точность, полнота и F1-меру для n-грамм, а также метрики для оценки длины и последовательности текста.
Существует несколько популярных инструментов и библиотек, которые позволяют автоматизировать процесс оценки качества работы СПТД:
- Scikit-learn — это одна из самых популярных библиотек Python для машинного обучения, которая включает в себя функции для вычисления метрик точности, полноты, F1-меры, ROC-кривой и других. Эта библиотека поддерживает работу с большими наборами данных и предоставляет удобный интерфейс для вычисления различных метрик.
- NLTK (Natural Language Toolkit) — библиотека для обработки естественного языка, которая предоставляет инструменты для работы с текстами, а также для вычисления метрик, таких как точность, полнота и F1-меры.
- TensorFlow и PyTorch — библиотеки для глубокого обучения, которые включают в себя различные способы оценки моделей, в том числе для задач обработки текста.
- Hugging Face Transformers — библиотека для работы с моделями трансформеров, такими как BERT, GPT и другими, также предоставляет встроенные инструменты для оценки качества работы моделей на текстах.
- SacreBLEU — специализированный инструмент для вычисления BLEU-метрики в задачах машинного перевода.
- ROUGE-Scores — инструмент для оценки качества суммаризации текста с использованием метрики ROUGE.
Оценка качества работы систем обработки текстовых данных является сложным и многогранным процессом, который требует учета множества факторов. В зависимости от типа задачи (классификация, извлечение информации, машинный перевод и др.) используются различные метрики, такие как точность, полнота, F1-меры, BLEU, ROUGE и другие. Каждый инструмент и метод оценки имеет свои преимущества и ограничения, и для получения максимально точной картины качества работы системы важно использовать комплексный подход, включающий несколько метрик.
Современные инструменты и библиотеки, такие как Scikit-learn, NLTK, Hugging Face и другие, значительно упрощают процесс оценки и позволяют исследователям и разработчикам более эффективно измерять производительность своих моделей, что способствует улучшению качества обработки текстовых данных и разработке более точных и эффективных систем.
Список литературы
- Бёрд, С. Обработка естественного языка с использованием Python [Текст]: O'Reilly Media, 2009. – Режим доступа: https://www.nltk.org/book/, свободный
- Васвани, А. Attention is All You Need [Текст]: Advances in Neural Information Processing Systems, 2017. № 30. С. 5998-6008. – Режим доступа: https://papers.nips.cc/paper/7181-attention-is-all-you-need, свободный
- Лин, Ц.-Ю. ROUGE: Пакет для автоматической оценки рефератов [Текст]: Text Summarization Branches Out: Proceedings of the ACL-04 Workshop, 2004. С. 74-81. – Режим доступа: https://aclanthology.org/W04-1013/, свободный
- Папинени, К. BLEU: Метод автоматической оценки качества машинного перевода [Текст]: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 2002. № 40. С. 311-318. – Режим доступа: https://aclanthology.org/P02-1040/, свободный
- Педрегоса, Ф. Scikit-learn: Машинное обучение на Python [Текст]: Journal of Machine Learning Research, 2011. № 12. С. 2825-2830. – Режим доступа: https://www.jmlr.org/papers/volume12/pedregosa11a/pedregosa11a.pdf, свободный

