
Введение
В современном мире задачи бинарной классификации имеют широкий спектр применения: от анализа поведения клиентов в банках и прогнозирования отказов оборудования до диагностики заболеваний. Для решения таких задач существует множество методов машинного обучения, которые отличаются не только принципами работы, но и качеством прогнозов, интерпретируемостью и вычислительными затратами.
Среди этих методов особое место занимают логистическая регрессия и дерево решений.
Логистическая регрессия
Логистическая регрессия — это метод машинного обучения, который используется для решения задач бинарной классификации, где целевая переменная может принимать только два значения: например, «1» — клиент покинул банк, и «0» — остался.
Чтобы понять, как работает логистическая регрессия, вспомним линейную регрессию. В линейной регрессии зависимость между признаками и целевой переменной описывается уравнением:
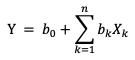 (1)
(1)
Здесь Y — линейная комбинация признаков, Xk - признаки (например, возраст, доход и т.д.), а b0 и bk - параметры модели (веса), которые определяются в процессе обучения.
Однако если целевая переменная — это класс (например, «1» — клиент ушёл, «0» — остался), линейная регрессия не подходит. Она может предсказывать значения Y, выходящие за пределы диапазона [0, 1]. Логистическая регрессия решает эту проблему с помощью логистической функции (сигмоиды):
![]() (2)
(2)
Логистическая функция берёт любое значение Y (которое может быть любым числом, даже отрицательным) и преобразует его в вероятность, которая всегда находится в диапазоне [0, 1].
После вычисления вероятности модель принимает решение на основе границы. Например, при пороговом значении 0.5:

Логистическая регрессия также помогает понять, какие именно признаки влияют на предсказание и в какой степени. Коэффициенты b0, b1,…, bn, которые модель оценивает в процессе обучения, отражают вес каждого признака в формировании результата. Чем больше абсолютное значение коэффициента, тем сильнее данный признак влияет на вероятность принадлежности объекта к определённому классу.
Таким образом, логистическая регрессия — это не только способ использования линейной комбинации признаков для получения корректных вероятностей, но и мощный инструмент для интерпретации данных, что делает её особенно полезной в задачах классификации.
Деревья решений
Также для задач бинарной классификации используются деревья решений. Дерево решений включает в себя решающие узлы, представляющие из себя разнообразные признаки, проверяемые условия, делящие выборку на две части согласно некоторому пороговому значению, и листовые узлы, являющиеся конечными прогнозами.
Для эффективности работы дерева решений требуется для разделяющих узлов выбрать наиболее информативные признаки, лучше всего отличающие один класс от другого, и показателем качества такой классификации служит мера загрязненности узла – загрязненность Джини, иллюстрирующая разнообразие в распределении вероятностей классов в данном узле, то есть вероятность неверной маркировки образца, и рассчитывающаяся по формуле:
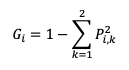 (3)
(3)
где Pi,k – доля k-го класса среди обучающих образцов в i-ом узле.
Для определения наилучшего разделения объектов отсортированные по возрастанию пороговые значения каждого уникального признака, представляющие собой среднее взвешенное между соседними значениями, делятся на два поднабора: меньшее и равное текущему пороговому значению узла переходит в левый поднабор, а большее переходит в правый, после чего для полученных поднаборов рассчитываются загрязнённости Джини и значение функции потерь по формуле:
 (4)
(4)
Порог, которому соответствует наименьшее значение функции потерь, и является наилучшим разделением.
Данный процесс повторяется для каждого узла дерева, а процесс классификации представляет собой спуск по дереву с использованием условий в каждом узле до достижения листового узла, выдающего окончательное значение класса.
Особенности и различия логистической регрессии и дерева решений
Одним из главных преимуществ логистической регрессии является ее простота и эффективность при работе с линейными зависимостями для больших наборов данных, не содержащих сильно коррелирующих признаков и не требующих кропотливой и трудозатратной подготовки. Однако логистическая регрессия чувствительна к мультиколлинеарности и масштабированию признаков, в этом случае требуется некоторая предварительная обработка данных перед обучением модели. Также логистическая регрессия может быть менее точной в случае нелинейных зависимостей, для которых целесообразнее будет использовать дерево решений, являющиеся более гибким инструментом для таких задач и не требующее предварительной обработки данных – нормализации или масштабирования признаков.
Можно выделить несколько ключевых различий между описанными методами. Использование логистический регрессии показывает хорошие результаты в задачах с линейной зависимостью, а также дает возможность легко интерпретировать результаты, так как позволяет оценить влияние каждого признака на результат с помощью коэффициентов. Дерево решений в свою очередь лучше работает со сложными данными и нагляднее демонстрирует процесс принятия решений, однако при увеличении глубины дерева интерпретация становится менее удобной.
Таким образом выбор метода для решения зависит от спецификации конкретной задачи. Логистическая регрессия предпочтительна при линейной зависимости между признаками и целевой переменной, а также если важна однозначная интерпретируемость модели. Дерево решений следует использовать в задачах с нелинейными зависимостями, но не нужно забывать, что оно потребует дополнительных усилий для предотвращения переобучения и сохранения высокой точности и корректности работы при изменении данных.
Список литературы
- Грас Д. Data Science. Наука о данных с нуля / Д. Грас. — М.: О’REILLY, 2018. — 228-252 с.
- Серрано Л. Грокаем машинное обучение / Л. Серрано — М.: О’REILLY, 2020. — 176-190 с.
- Гарнер К. Введение в машинное обучение с Python / К. Гарнер. — М.: ДМК Пресс, 2017. — 83-97 с.



