
Мониторинг данных в реальном времени включает постоянное отслеживание и анализ поступающих данных, что критически важно для быстрого реагирования на изменения в динамичной среде, такой как социальные сети или системы онлайн-транзакций. Это позволяет компаниям и организациям оперативно реагировать на изменения и выявлять значимые события, особенно важные для таких сфер, как кибербезопасность и электронная коммерция, где время отклика имеет первостепенное значение. Основная цель мониторинга в реальном времени — поддержание постоянного контроля над состоянием информационных систем, бизнес-процессов или социальных событий и принятие своевременных решений на основе актуальной информации, что особенно важно в эпоху больших данных и интернет-вещей.
Системы реального времени работают на основе ряда ключевых принципов. Во-первых, данные поступают в систему непрерывно и обрабатываются незамедлительно, что позволяет отслеживать все изменения в режиме реального времени. Во-вторых, обработка данных происходит с минимальной задержкой, что дает возможность предоставлять актуальную информацию практически моментально, что критично для приложений, работающих в высокоскоростных сетях и финансовых рынках. В-третьих, такие системы могут автоматически реагировать на определенные события или отклонения, генерируя предупреждения или выполняя предопределенные действия, что особенно полезно для автоматизации процессов и обеспечения кибербезопасности. Масштабируемость этих систем позволяет им справляться с увеличивающимися объемами данных и поддерживать множество одновременных потоков информации, что важно для социальных платформ и облачных сервисов. Наконец, системы должны быть надежными и устойчивыми к отказам, обеспечивая непрерывную работу даже в случае сбоев отдельных компонентов, что важно для поддержания высокого уровня доступности и устойчивости сервисов в условиях постоянного роста нагрузки и угроз.
Выбор конкретных инструментов и технологий для мониторинга и анализа данных в реальном времени зависит от специфики задач, требований к производительности и масштабируемости, а также от существующей инфраструктуры и предпочтений организации. На рисунке представлены оптимальные условия для выбора инструментов и технологий:
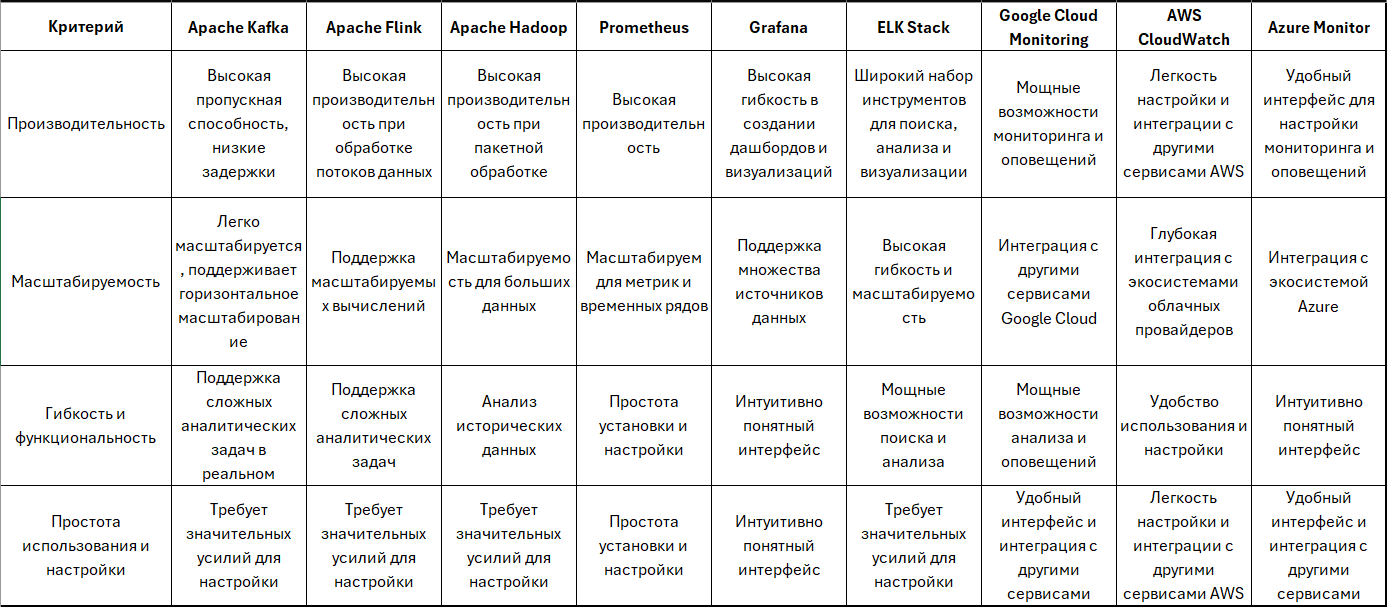
Рисунок 1. Оценка эффективности различных технологий и инструментов
В данном примере будет реализована упрощенная система мониторинга и анализа данных в реальном времени с использованием Python. Система будет собирать данные с датчиков, обрабатывать их и визуализировать результаты в реальном времени [30].
Компоненты системы:
1. Сбор данных: Использование Apache Kafka для передачи данных.
2. Обработка данных: Обработка данных с использованием Apache Flink.
3. Анализ данных: Применение модели машинного обучения для детектирования аномалий.
4. Визуализация данных: Визуализация данных с использованием Plotly и Dash.
Шаг 1: Установка необходимых библиотек:
pip install kafka-python pandas scikit-learn dash plotly
Шаг 2: Программа для генерации данных и отправки в Kafka:
from kafka import KafkaProducer
import json
import time
import random
producer = KafkaProducer(bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
def generate_data():
sensor_id = random.randint(1, 10)
value = random.uniform(10.0, 100.0)
data = {'sensor_id': sensor_id, 'value': value, 'timestamp': time.time()}
return data
if __name__ == '__main__':
while True:
data = generate_data()
producer.send('sensor_data', data)
print(f"Sent: {data}")
time.sleep(1)
Шаг 3: Программа для обработки данных и детектирования аномалий:
from kafka import KafkaConsumer
import json
import numpy as np
from sklearn.ensemble import IsolationForest
consumer = KafkaConsumer('sensor_data',
bootstrap_servers='localhost:9092',
value_deserializer=lambda v: json.loads(v.decode('utf-8')))
# Обучение модели для детектирования аномалий
training_data = np.random.uniform(10.0, 100.0, (100, 1))
model = IsolationForest(contamination=0.1)
model.fit(training_data)
def detect_anomalies(value):
prediction = model.predict([[value]])
return prediction[0] == -1
if __name__ == '__main__':
for message in consumer:
data = message.value
sensor_id = data['sensor_id']
value = data['value']
is_anomaly = detect_anomalies(value)
print(f"Sensor ID: {sensor_id}, Value: {value}, Anomaly: {is_anomaly}")
Шаг 4: Программа для визуализации данных с использованием Dash
import dash
from dash import dcc, html
from dash.dependencies import Input, Output
import plotly.graph_objs as go
from kafka import KafkaConsumer
import json
import threading
# Глобальные переменные для хранения данных
data_points = [ ]
# Функция для получения данных из Kafka
def fetch_data():
consumer = KafkaConsumer('sensor_data',
bootstrap_servers='localhost:9092',
value_deserializer=lambda v: json.loads(v.decode('utf-8')))
for message in consumer:
data = message.value
data_points.append(data)
if len(data_points) > 100:
data_points.pop(0)
# Запуск функции получения данных в отдельном потоке
threading.Thread(target=fetch_data, daemon=True).start()
# Инициализация Dash-приложения
app = dash.Dash(__name__)
app.layout = html.Div(children=[
html.H1(children='Real-time Data Visualization'),
dcc.Graph(id='live-update-graph'),
dcc.Interval(
id='interval-component',
interval=1*1000, # Обновление каждые 1 секунду
n_intervals=0
)
])
@app.callback(Output('live-update-graph', 'figure'),
[Input('interval-component', 'n_intervals')])
def update_graph_live(n):
data = [
go.Scatter(
x=[dp['timestamp'] for dp in data_points],
y=[dp['value'] for dp in data_points],
mode='lines+markers'
)
]
return {
'data': data,
'layout': go.Layout(
xaxis=dict(title='Time'),
yaxis=dict(title='Value'),
title='Sensor Data'
)
}
if __name__ == '__main__':
app.run_server(debug=True)
Запуск системы.
1. Запускаем Kafka и создаем топик `sensor_data`:
bin/kafka-topics.sh --create --topic sensor_data --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
2. Запускаем генератор данных:
python data_generator.py
3. Запускаем обработчик данных и детектирования аномалий:
python data_processor.py
4. Запускаем визуализацию данных:
python data_visualization.py
Далее открываем веб-браузер и переходим по адресу `http://127.0.0.1:8050/`, чтобы увидеть график с данными датчиков в реальном времени. На рисунке 2 представлена визуализация кода.
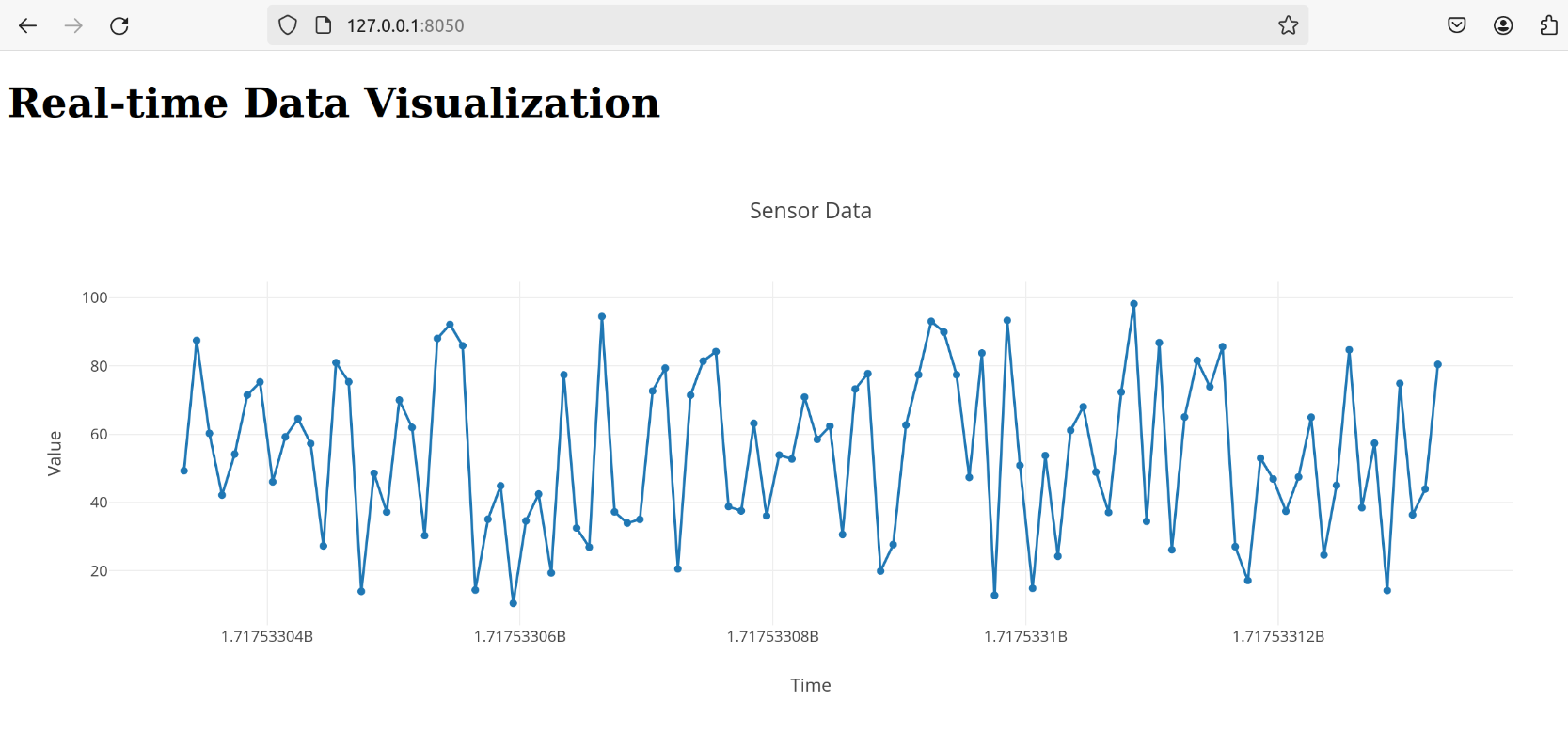
Рисунок 2. Визуализация данных в реальном времени.
Этот пример демонстрирует базовую реализацию системы мониторинга и анализа данных в реальном времени с использованием Python. Вы можете расширять и адаптировать эту систему в соответствии с вашими требованиями и задачами.
Список литературы
- Сидоров И.А. Основы философии: учеб. пособие / И.А. Сидоров. — 3-е изд. — М.: Просвещение, 2015. — 320 с.
- Петрова А.В. Экономическая теория: учеб. пособие / А.В. Петрова; СПбГУ. — СПб.: Изд-во СПбГУ, 2022. — 288 с.
- Сидоров К.Н. Введение в социологию: учеб. пособие / К.Н. Сидоров. — 4-е изд. — М.: Высшая школа, 2019. — 256 с.
- Николаева Е.А. История искусств : учеб. пособие / Е.А. Николаева; МГХПА им. С.Г. Строганова. — М.: Изд-во МГХПА, 2017. — 340 с.
- Смирнов Д.В. Основы права: учеб. пособие / Д.В. Смирнов ; РАНХиГС. — М.: Изд-во РАНХиГС, 2020. — 290 с.



