
Основным способом добычи нефти и газа является строительство глубоких скважин на месторождениях углеводородов. Оптимальной конструкции этих инженерных сооружений не существует, и под каждые конкретные условия геологического разреза разрабатывается индивидуальный проект. Основной целью нефтегазодобывающих компаний при этом является извлечение максимально возможного объема продукта, что прямо пропорционально окупаемости вложений.
Наиболее эффективным, а также сложным как технологически, так и организационно, является бурение горизонтального ствола в интервале продуктивного пласта для увеличения площади дренирования, и дебита, как следствие.
В условиях Западной Сибири, ключевой территории для отрасли, где сосредоточены уникальные по своему количеству и составу углеводороды, в непосредственной близости от нефтегазоносного объекта располагаются водоносные горизонты [1]. В упрощённой схеме проводки пространственное расположение горизонтального ствола должно быть оптимально удалено от кровли и подошвы пласта. Чтобы прояснить, какие требования к точности действий предъявляются, вот некоторые цифры: бригада непрерывно в течение нескольких дней бурит скважину оборудованием массой свыше 100 тонн, при этом инструмент может располагаться на глубине до 6 километров, непосредственный визуальный обзор отсутствует, а положение ствола должно до метра соответствовать проектным расчётам (в редких случаях, когда позволяет мощность пласта, погрешность может быть +–5 метров). Любая ошибка приведёт к дорогостоящим операциям по её устранению или потере скважины в целом.
И ожидается, что доля строительства горизонтальных скважин будет только увеличиваться [2].
Обеспечить необходимую точность при проводке ствола, мониторинг процессов в режиме реального времени, снизить влияние человеческого фактора и соблюсти требуемый уровень отказоустойчивости позволяют информационные системы. Основные этапы разработки математического алгоритма восстановления геометрии геологических пластов на базе моделей машинного обучения представлены далее.
В качестве исходных данных для обучения моделей используется минимальный объем информации, полученный с 2 опорных скважин (вертикальной и горизонтальной): данные каротажа при вертикальном бурении, геометрии горизонтального ствола (график 1), естественной радиоактивности пород (график 2) и глубины кровлей и подошв.
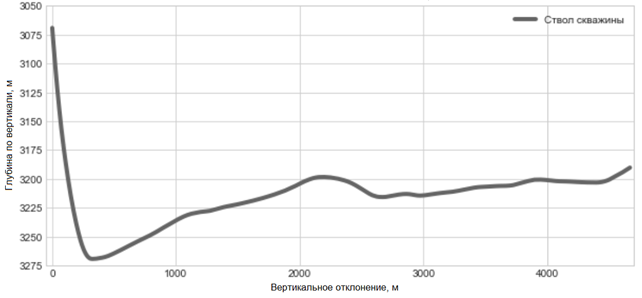
График 1. Схема горизонтального ствола
# Данные каротажа при вертикальном бурении
VertWellLog = pd.read_excel('VertWell/VertWellLog.xlsx')
# Глубины кровлей и подошв пластов
VertWellTops = pd.read_excel('VertWell/VertWellTops.xlsx')
VertWellTops.rename(columns={'Depth': 'Top'}, inplace=True)
VertWellTops['Bottom'] = [VertWellTops['Top'][value] \
for value in \
range(1, len(VertWellTops['Top']))] + [0.0]
VertWellTops = VertWellTops[:(len(VertWellTops) - 1)]
# h - мощность пласта
VertWellTops['h'] = [VertWellTops['Bottom'][i] - VertWellTops['Top'][i] \
for i in range(len(VertWellTops))]
# Данные о геометрии горизонтального ствола и естественной радиоактивности
hz_well_geometry_logs = pd.read_excel('HorizWell/hz_well_geometry_logs.xlsx')
Такой ограниченный датасет не приводит к снижению точности результатов работы системы и позволяет нефтегазовым компаниям оперативно приступать к строительству сложных объектов.
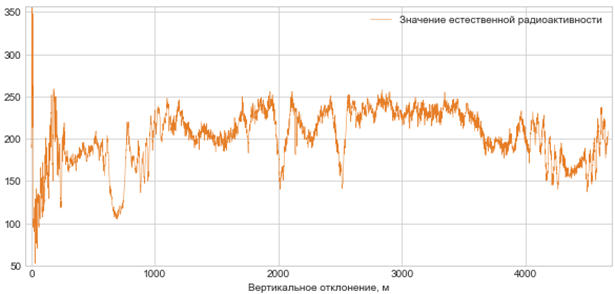
График 2. Данные о естественной радиоактивности пород
На этапе исследования были выбраны следующие алгоритмы из библиотеки scikit-learn:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import LinearSVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
По каждому из которых обучена модель для пластов:
# Определим группы пластов для обучения моделей
datasets = [['above_Cleveland_Shale', 'Cleveland_Shale', 'TA'],
['Cleveland_Shale', 'TA', 'TZ'],
['TA', 'TZ', 'TB'],
['TZ', 'TB', 'Three_Lick_Bed'],
['TB', 'Three_Lick_Bed', 'Bottom_hrz']]
По результатам произведено сравнение базовых моделей и исключены неперспективные.
На втором этапе в целях увеличения точности регрессионных моделей применён GridSearchCV с заданными параметрами для тонкой настройки моделей. Получены оптимальные значения.
from sklearn.model_selection import GridSearchCV
opt_hyperparameters = {} # для записи оптимальных гиперпараметров
Полученный словарь имеет вид (представлен один ключ):
r_opt_hyperparameters = {
'Cleveland_Shale': {
'SVR': {'R^2': 0.20776241327293254,
'MAE': 11.076387030381216,
'MSE': 171.89376978613865,
'best_params_': {'C': 1.0,
'kernel': 'rbf'}}},
…
# Теперь с учётом полученных оптимальных гиперпараметров и эстиматоров
# обучим классификационные модели `model1`-`model5` для групп пластов
right_model = {}
n = 1
for group, model in opt_hyperparameters.items():
layers = group.split(' + ')
for model_name, metrics_and_params in model.items():
model_id = f'model{n}'
right_model[model_id] = {model_name: metrics_and_params['best_params_']}
right_model[model_id]['layers'] = [*layers]
n += 1
np.random.seed(42)
# Для каждой группы пластов подготовим таблицу
model1_frame = pd.DataFrame(columns=VertWellLog2.columns)
model2_frame = pd.DataFrame(columns=VertWellLog2.columns)
model3_frame = pd.DataFrame(columns=VertWellLog2.columns)
model4_frame = pd.DataFrame(columns=VertWellLog2.columns)
model5_frame = pd.DataFrame(columns=VertWellLog2.columns)
Далее полученные модели сохраняются для дальнейшего инференса.
for model in right_model:
pickle.dump(model, open(f"{model}.pkl", "wb"))
Ещё одной из задач, которую предстояло решить – это правильная обработка данных кривой естественной радиоактивности пород в неоднородном разрезе. Был применён метод батчинга, когда значение глубины и текущие координаты забоя относились к конкретному пласту только после получения нескольких значений при работе моделей с высокой степенью уверенности по нескольким последним запросам. Это позволило «сгладить» графики восстановленных геометрий геологических пластов (графики 3, 4).
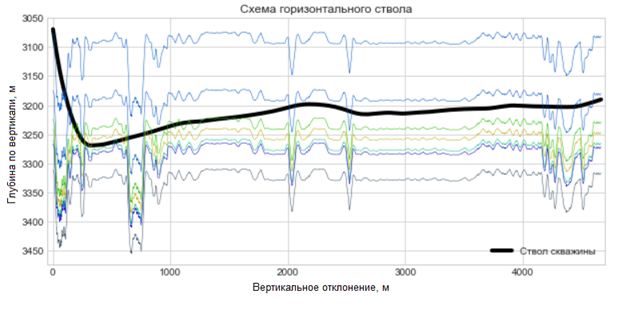
График 3. Геологический разрез с восстановленной геометрией пластов (до сглаживания)
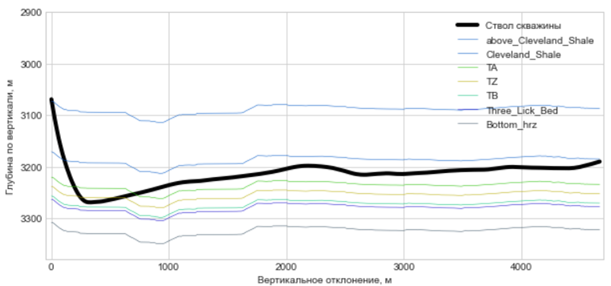
График 4. Геологический разрез с восстановленной геометрией пластов (после сглаживания)
Модуль по ETL, анализу данных и подготовке моделей упакован в докер контейнер [3]. В качестве средства оркестрации контейнерами предлагается к применению kubernetes [4].
Достигнутая точность MVP ~ 94 % усреднённая по пластам позволяет судить о перспективности разработки. В настоящее время проводятся работы по оптимизации сервиса, как системы реального времени при режимах работы на средних и высоких нагрузках, и подготовке экономического обоснования ОПИ.
Список литературы
- Нефтегазоносная провинция, бассейн [Электронный ресурс] – URL: https://neftegaz.ru/tech-library/ngk/147608-neftegazonosnaya-provintsiya/ (дата обращения 09.08.2021).
- Кульчицкий В.В., Закиров А.Я., Овчинников В.П. и др. Состояние и перспективы горизонтального бурения в России [Электронный ресурс]: Специализированный журнал «Бурение & нефть», 2020. – URL: https://burneft.ru/archive/issues/2020-10/11 (дата обращения 09.08.2021).
- Docker: Empowering App Development for Developers [Электронный ресурс] – URL: https://www.docker.com/ (дата обращения 09.08.2021).
- Kubernetes [Электронный ресурс] – URL: https://kubernetes.io/ru/ (дата обращения 09.08.2021).



