
Анализ предметной области
В данном разделе представлен обзор понятия и принципов статического анализа и технологий, в котором наибольшее внимание уделено анализу потока данных и символьному выполнению.
Понятие статического анализа
Статический анализ кода — это процесс выявления ошибок и недочетов в исходном коде программы, производимый до ее выполнения, то есть без генерации объектного и исполняемого кодов. Статический анализ можно рассматривать как автоматизированный процесс обзора кода.
Главное преимущество статического анализ состоит в возможности существенного снижения стоимости устранения дефектов в программе. Чем раньше ошибка выявлена, тем меньше стоимость ее исправления. С ростом проекта увеличивается плотность ошибок. Однако, стоит понимать, что статические анализаторы также могут выдавать и ложные срабатывания. Достичь их отсутствия остается неразрешимой задачей, что подтверждается теоремой Райса [3].
Принципы работы статического анализа
Почти все статические анализаторы так или иначе построены по принципу компиляторов, то есть в их работе присутствуют этапы преобразования исходного кода — такие же, какие выполняет компилятор.
Можно выделить следующие шаги в работе статического анализатора:
1. Разбор текста
1.1.Лексический анализ: фаза компиляции, объединяющая последовательно идущие во входном потоке символов в слова, называемые лексемами исходного языка, и возвращающая последовательность токенов для всех лексем исходной грамматики [4];
1.2.Синтаксический анализ:
- фаза компиляции, группирующая токены, порождаемые на фазе лексического анализа, в синтаксические структуры [4];
1.3.Контекстный анализ;
2. Применение некоторых правил.
Синтаксический анализатор обнаруживает синтаксические ошибки, с учетом грамматики входного языка, и преобразовывает программу в структуру данных, называемую деревом разбора [5]. Такая структура, в свою очередь, поступает, в качестве входных данных, статическому анализатору и обрабатывается им.
Существует множество различных методов статического анализа. Их реализация может различаться в разных анализаторах. Однако в большинстве случаев статические анализаторы для различных языков программирования имеют один и тот же базовый набор алгоритмов, вне зависимости от конкретных задач. Например, они так или иначе взаимодействуют с деревом разбора.
Технологии, использующиеся для статического анализа кода
В данной разделе будут рассмотрены некоторые существующие технологии статического анализа, использующиеся в популярных инструментах.
Анализ потока данных
Одним из основных алгоритмов статического анализа является анализ потока данных. Такой анализ собирает информацию о данных в различных точках программы. Для анализа потока данных необходим граф потока управления или статическая форма одиночного присваивания. Они используется для определения тех частей программы, на которые могут распространяться данные.
Формулировка задачи анализа потока данных зависит от того, какую именно информацию нужно определить. Например, если необходимо определить, является ли выражение константой, а также значение этой константы, то решается задача распространения констант, если необходимо определить тип переменной – задача распространения типов, если необходимо понять, какие переменные могут указывать на определенную область памяти, то речь идет о задаче анализа синонимов и так далее.
Рассмотрим задачу распространения констант.
Распространение констант
Распространение констант – это оптимизация, уменьшающая избыточное вычисление, путем замены константных выражений и переменных на их значения. Распространение констант является прямой задачей потока данных.
Множество значений потока данных представляет собой решетку произведений, в которой имеется по одному компоненту для каждой переменной программы [4]. В решетку для единственности переменной входит следующее:
- Все константы подходящего для данной переменной типа;
- Значение, означающее не константу (англ. Not-a-Constant, NAC). Данное значение возникает, если переменной присвоено входное значение, либо если переменная может быть вычислена из другой переменной не являющейся константой, а также если на разных путях, приводящих к одной и той же точке программы, переменной могут присваиваться разные константы;
- Значение, означающее неопределенность (англ. Undefined, UNDEF) [4].
Значение потока данных в такой структуре представляет собой отображение каждой переменной программы на одно из значений в решетке констант.
Далее определяется множество F, которое состоит из передаточных функций, которые, в свою очередь, принимают отображения переменных на значения в решетке констант и возвращают другие отображения данного вида.
Пусть v инструкция блока, fv – ее передаточная функция, m и m' представляют значения потока данных, такие, что m'=fv(m). Опишем передаточную функцию fv в терминах отношений между m и m'.
Пусть инструкция v – присваивание переменной x, то для всех переменных w ≠ x выполняется соотношение m'(w) = m(w), где m'(x) определяется следующим образом:
- Если в правой части инструкции v находится константа c, то m'(x=c);
- Если в правой части инструкции v находится многочлен, к примеру, a+b, то
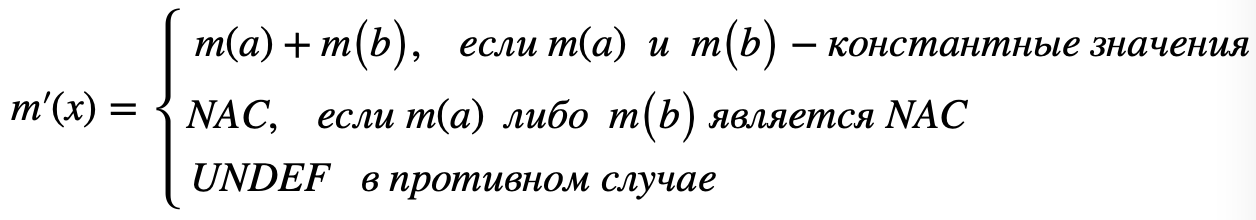 ;
;
- Если в правой части выражения находится не многочлен, то m(x)=NAC [4].
Рассмотрим пример, взятый из книги А. В. Ахо «Компиляторы: принципы, технологии и инструментарий»
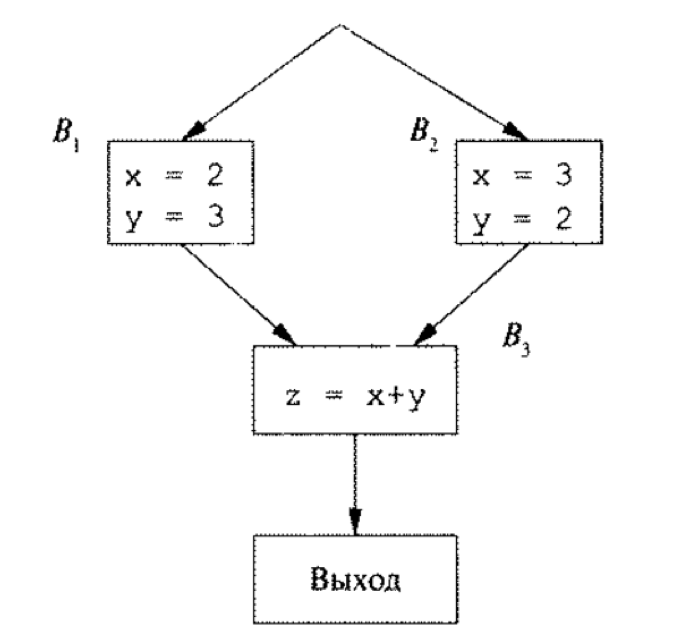
Рисунок 1.1 – Пример, взятый из книги А. В. Ахо «Компиляторы: принципы, технологии и инструментарий»[4]
Аннотирование методов
Вместо того, чтобы рекурсивно проверять корректность работы каждого метода, можно задать аннотации для методов языка, то есть какие-то характеристики и ограничения на входные параметры, которые помогут в поиске ошибок. Можно составлять аннотации, самостоятельно анализируя тело функции. Так приходится делать, когда нельзя получить доступ к телу функции или тело функции описано в модуле, который собирается динамически и так далее. Для популярных библиотек создатели статических анализаторов составляют ручные аннотации методов.
Сопоставление с шаблоном
Анализатор, проверяя код, находит заданные заранее ошибочные шаблоны. В простейшем варианте этот поиск похож на поиск ошибок с помощью регулярных выражений, однако всё обстоит несколько сложнее. Для поиска ошибок используется обход и анализ дерева разбора.
Список литературы
- Колосов А.П., Рыжков Е.А. Применение статистического анализа при разработке программ // Известия Тульского государственного университета. Серия: Технические науки. 2008. №3 С.185–190
- Макконелл, С. Совершенный код / С. Макконелл – Санкт-Петербург: БХВ-Петербург, 2017. – 896 с.
- Rice, H.G. Classes of Recursively Enumerable Sets and Their Decision Problems // Transactions of the American Mathematical Society: journal. – 1953. – March (vol. 74, no. 2). – P. 358–366
- Ахо А. Компиляторы: Принципы, технологии и инструментарий / А. Ахо, Р. Сети, Д. Ульман; пер. И.В. Красикова. – 2-е изд. – М.: Вильямс, – 2008. – 1184 с.
- Рейуорд-Смит В.Дж. Теория формальных языков. Вводный курс / В.Дж. Рейуорд-Смит; ред. И.Г. Шестакова; пер. Б.А. Кузьмина. – М.: Радио и связь, – 1988. – 128 с.
- Чень Ч., Ли Р. Математическая логика и автоматическое доказательство теорем -/ Ч. Чень, Р. Ли; ред. С.Ю. Маслов; пер. Г.В. Давыдов – М: Наука, – 1983. – 358 с.
- Дистель Р. Теория графов / Р. Дистель; пер. О.В. Бородин – Новосибирск: Институт математики, – 2002. – 336 с.



