
В настоящее время социальные сети являются не только средой для организации общения различных лиц, но и эффективным средством сбора и обработки различных источников информации или для проведения контент-анализа. В условиях развития интеллектуальных технологий, экспертных систем актуальность получили автоматизированные системы классификации комментариев в социальных сетях, работа которых основана на семантическом анализе [2, c.104].
Алгоритм работы автоматизированной системы классификации комментариев в социальных сетях отражен на рисунке 1.
Рисунок 1 – Алгоритм работы автоматизированной системы классификации комментариев в социальных сетях
Рассмотрим приведенный алгоритм работы автоматизированной системы классификации комментариев в социальных сетях более детально. На первоначальном этапе автоматизированная система получает комментарии с определенного сообщества социальной сети. Для этого автоматизированная система получает доступ к ресурсу, производит считывание ее HTML-кода, а затем отделяет комментарии.
На втором этапе автоматизированной системой производится фильтрация текстов комментариев по наполнению страницы. При фильтрации в комментариях системой выделяются «стоп-слова», представленные предлогами, союзами, а затем проводится стемминг. Процесс стемминга предусматривает использование морфологических правил и отброс из отфильтрованных комментариев аффиксов (суффиксов, окончаний).
Классификация комментариев с построением классов на основе проведения семантического анализа в автоматизированной системе классификации комментариев осуществляется методами латентно-семантического анализа (ЛСА) и TF-IDF.
Метод ЛСА для обработки данных формирует матрицу термов-на-документы, для каждого их которых устанавливаются частота использования в каждом комментарии. Данный метод предусматривает сингулярное разложение полученной матрицы с последующим отражением структуры семантики, которая должна соответствовать исходной матрице.
Для оценки приоритета слова в комментарии автоматизированная система классификации комментариев использует метод статической обработки TF-IDF. Мера TF (Term Frequency) применяется для отражения соотношения между количеством вхождений определенного слова и общего количества слов в комментарии. При этом производится оценка приоритета каждого слова в определенном комментарии. Мера IDF (Inverse Document Frequency) применяется для оценки инверсии частоты, с которой слово встречается в определенной группе комментариев с последующим назначением ему уникального идентификатора.
На следующем этапе производится классификация комментариев с распределением их по классам с выделением однородных групп с применением метода косинусного сходства FOREL (Format Element). Метод FOREL реализуется автоматизированной системой классификации комментариев для выделения групп максимально близких по признакам объектов, которые затем будут группироваться в кластеры.
В целом, классификатор можно представить в виде матрицы, отражающей число документов и значений косинусного сходства для двух векторов. Документы имеют общие признаки, если косинусное сходство не ниже КМКС (коэффициент минимальной косинусной схожести). После этого автоматизированной системой производится сортировка документов в порядке убывания с последующим размещением близким по признакам документов в новый кластер. Процесс сортировки завершается, когда в исходном кластере не остается ни одного документа.
На основании выполненного анализа алгоритма работы автоматизированной системы классификации комментариев в социальных сетях разработаем ее структурную схему и приведем ее на рисунке 2.
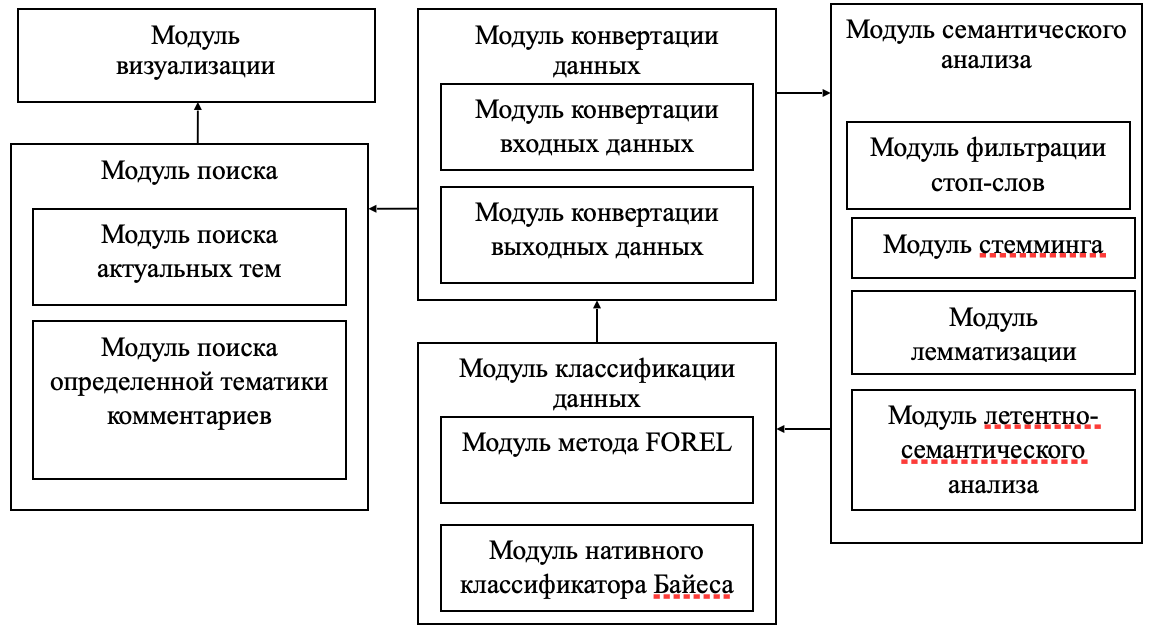
Рисунок 2 – Структура автоматизированной системы классификации комментариев в социальных сетях
Для хранения данных необходимо разработать реляционную базу данных [1, c.48]. Для разработки реляционной базы данных была создана ER-диаграмма, вид которой приведен на рисунке 3.
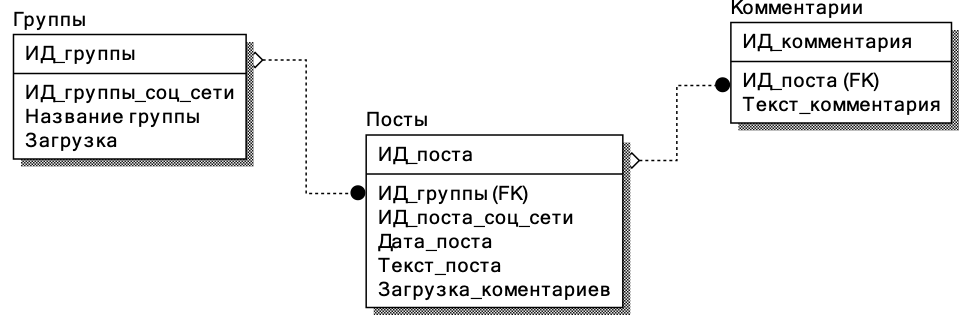
Рисунок 3 - ER-диаграмма базы данных
Таким образом, в реляционную базу данных для работы автоматизированной системы классификации комментариев в социальных сетях будут входить таблицы «Группы», «Посты» и «Комментарии».
Список литературы
- Фидря Е. С. Принципы автоматизированной системы извлечения и классификации комментариев в социальных сетях на основе трехфакторной коммуникационной модели // Вестник Балтийского федерального университета им. И. Канта. – 2021. – №12. – С.48-55.
- Шиянов Г. О. Автоматизированная система классификации комментариев в социальных сетях // Вестник научных конференций. – 2019. – №5-3(45) – С.104-108.



