
Введение
На сегодняшний день по всему миру насчитывается более 7000 языков, по большей части порядка 80% населения земли контактируют друг с другом по средству наиболее распространенных 80 языков. Что в свою очередь является препятствием социального и технического взаимодействия. Для поддержания контакта между носителями разных языков с давних пор было необходимо наличие посредника, обладающего знаниями о структурах и правилах языков обоих носителей. Но ничто не вечно, с приходом, развитием и распространением ЭВМ в нашей жизни многие ее элементы были автоматизированы и отданы на выполнение машинам. Компьютеры не хуже человека, а во многом и лучше его, справляются с множеством повседневных задач, а обработка естественного языка является относительно новым и перспективным направлением. Мировой рынок Natural Language Processing (NLP), по данным Mordor Intelligence, к 2026 году достигнет 42,04 миллиарда долларов США, при этом среднегодовой темп роста составит 21,5% [7]. Со времен Алана Тьюринга ученые по всему миру разрабатывают и совершенствуют алгоритмы машинного перевода, анализа текста, что в свою очередь влияет на увеличение сложности дальнейших исследований. Для того, чтобы понять, какие начальные знания необходимы для осуществления решения задач NLP следует выделить основные элементы и методы подготовки и анализа текста.
Основная часть
Столкнувшись со сложной задачей необходимо начинать ее решение с структуризации последовательности действий, направленных на достижение конечного результата. Создается конвейер данных под названием pipeline (пайплайн), содержащий в себе правила предобработки входной информации и условия построения модели [6]. Правила нормализации входных данных устанавливаются в тот момент, когда выбирается класс задачи, решаемой методом NLP. Первым шагом приведения данных считается их очистка (Data Cleaning) [5]. Из текста удаляются особые знаки, символы, пунктуация, тэги, и т.д., которые не используются, как признаки и ключевые элементы при выполнении конечного анализа [2]. Стоит подходить с осторожностью к очистке текста от специальных символов, например знаков валют, что в свою очередь может негативно сказаться на точности полученного результата работы модели, ведь, к примеру, в текстах, связанных с экономикой такие обозначения могут нести в себе существенные для анализа признаки. Далее следуют другие этапы предварительной обработки данных, такие мероприятия занимают продолжительную часть времени и включают в себя работу над теми элементами, которые затрудняют процесс получения знаний, например существует необходимость приводить формат представления времени к единому, общему для программы, виду, а также унификация текста путем выбора общего для символов регистра. К тому же, к процессу предварительной обработки данных (Preprocessing of Data) относят их нормализацию, это процесс приведения исходного набора к новому диапазону значений шкалирования, ведь большая разница в оценке атрибутов сказывается негативно на конечных результатах обучения модели, так как они, соответственно, оказывают математически разное влияние. Затем идет формирование «лексем» или «лексических элементов», путем выделения отдельно взятых слов из текста. Описанный процесс называется «токенизацией», он необходим для того, чтобы реализовывать наиболее распространенные архитектуры глубокого обучения в обработке естественного языка, например LSTM или RNN, проведя разбиение на отдельные слова в нескольких предложениях текста формируется словарь. На основе полученного словаря можно получать новые данные, необходимые для правильного функционирования конечного алгоритма анализа данных [4]. Следующим шагом в анализе текста является удаление стоп-слов. Стоп-слова – это слова, знаки, символы, которые самостоятельно не несут никакой смысловой нагрузки, но необходимые для нормального восприятия текста, его целостности, читабельности. В контексте анализа данных они вносят лишь шум, что может исказить последующий результат и сделать последующие действие менее эффективными.
Стоп-слова делятся на следующие категории: общие и зависимые. К категории общих слов можно отнести предлоги, суффиксы, причастия, междометия, цифры, частицы и т. п.
Зависимые стоп-слова зависят от поисковой фразы и в поисковом запросе учитываются только при наличии в искомом документе значимых ключевых слов.
Что в одном тексте может являться стоп-словами, то в другом тексте может давать определённый смысл. Например, фраза: “The movie was not good at all” после очистки может принять следующий вид: “movie good”, смысл которой в конечном итоге значительно отличается от изначального. Одним из следующих и важных шагов является лемматизация. Предобработка текста подразумевает приведение каждого токена в его начальную форму или лемму. Данный процесс упрощает анализ текста и уменьшает вычислительные нагрузки. Например, у нас в тексте встречаются слова: игрушки, игрушку, игрушек и т.д. Лемматизация уменьшает неоднозначность текста, позволяет уменьшить объём базы данных для анализа путём упрощения или приведения слов в начальную форму.
Для реализации данного метода необходимо точное знание части речи, которые в зависимости от контекста может меняться. Для его определения необходимо извлечь тэг “part-of-speech” для слова в этом конкретном контексте.
В анализе и обработке текста также широко распространён метод деления текста на N-граммы. N-грамма представляет собою комбинацию из N-слов, использующихся вместе. В процессе анализа N-грамм текста можно получить более подробную информацию о самом тексте или о наборе документов. Классическим примером является сравнительный анализ двух статей разных авторов на предмет наличия плагиата, путём разбиения текста на небольшие последовательности и их сравнения, в результате которого можно сделать вывод об степени сходства документов. В процессе сравнения статей одного и того же автора можно сделать вывод о синтаксической структуре текста, какие обороты и идиомы он чаще всего использует. Также можно использовать данный метод разбиения на последовательности для поиска и коррекции ошибок в тексте.
После предобработки текста необходимо предоставить компьютеру данные в виде чисел – этим и занимается векторизация.
Одним из самых часто используемых методов является TF-IDF, описывающий важность слов в контексте одного документа. Часто используется при расчёте меры близости документов при кластеризации. С помощью данного метода можно выявлять стоп-слова в исходном документе, так как междометия и предлоги получат низкий коэффициент TF-IDF из-за их высокой частотности, а важные контекстуальные слова получат высокий вес. Одним из преимуществ данного метода является простота вычисления.
TF – это частотность слова, формула описана ниже
IDF – это обратная частотность слова, используется для определения важности термина в документе
Существует огромное количество направлений, в которых можно применить обработку: разработка чат-ботов, определение настроений текстовых документов, машинный перевод, выявление спама, авто дополнения текста и другие [3]. Для их реализации необходима предобработка входного документа для более корректных результатов.
В качестве примера можно рассмотреть сентиментальный анализ текстовых комментариев в сообществе “Типичный Воронеж” в соц. сети “Вконтакте”. Для анализа документов были выполнены следующие шаги: парсинг текста, предобработка текста (очистка от специальных символов, эмодзи), лемматизация всех токенов документа и векторизация. После валидации данных идёт этап создания алгоритма, который эти данные и обрабатывает. Пример такого алгоритма представлен ниже, на рисунках 1 -3.
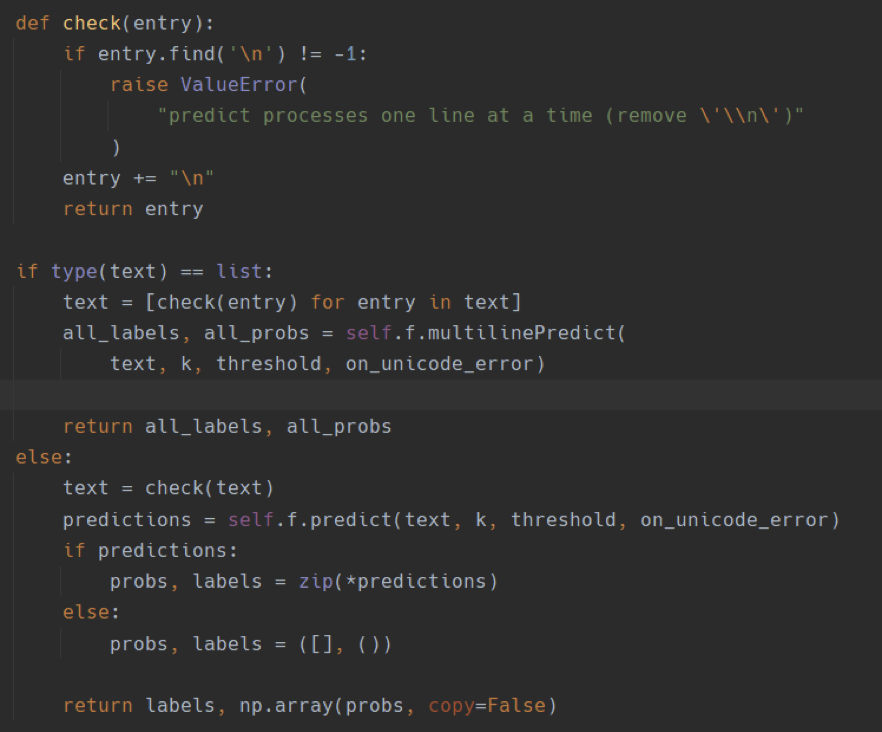
Рисунок 1 – пример алгоритма.
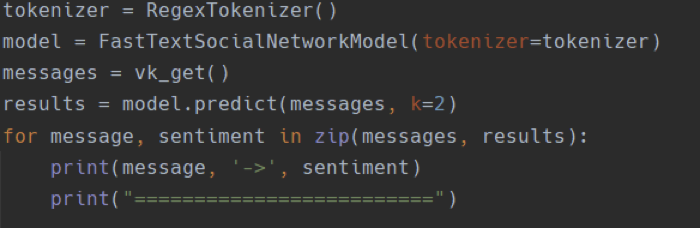
Рисунок 2 – пример алгоритма.
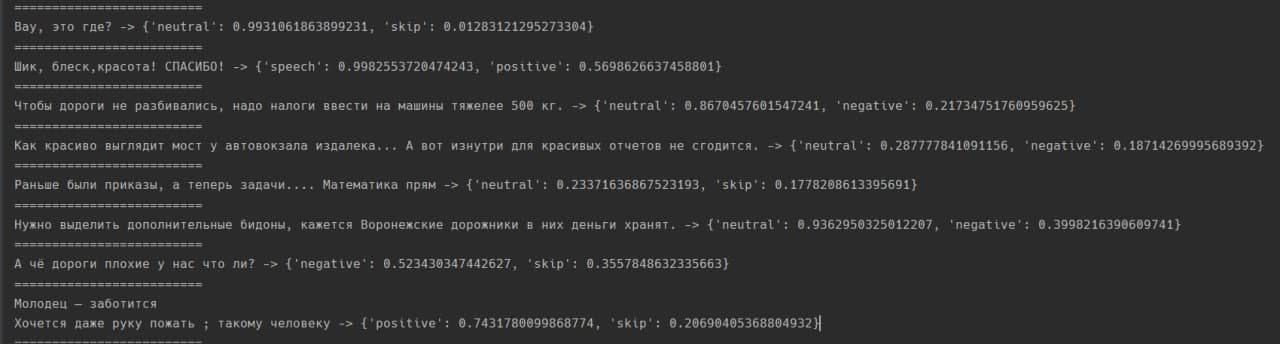
Рисунок 3 – результат работы алгоритма определения тональности текста.
Вывод: в наши дни обработка естественного языка является сложной и перспективной задачей в области информационных систем. Создание конвейера данных структурирует функционирование модели, а очистка данных и процесс предварительной обработки позволяют с особой точностью получить искомый результат. Стоит помнить о признаках, выбранных на стадии создания пайплайна, они во многом влияют на конечный результат. Только благодаря обоснованному выбору методов Data Cleaning и Preprocessing of Data, дальнейшему проектированию алгоритма с применением, к примеру, машинного обучения возможно получать хорошую точность результата работы методов обработки естественного языка.
Список литературы
- Комаров П. В., Сокольников В. В., Ветохин В. В. Проблематика обучения нейросети для распознавания дефектов деталей на аддитивном производстве //Перспективные научные разработки. – 2019. – С. 30-35.
- Цитульский А. М., Иванников А. В., Рогов И. С. NLP-обработка естественных языков //StudNet. – 2020. – Т. 3. – №. 6. – С. 467-475.
- Сарбасова А. Н. Исследование методов сентимент-анализа русскоязычных текстов //Молодой ученый. – 2015. – №. 8. – С. 143-146.
- Посевкин Р. В., Бессмертный И. А. Применение сентимент-анализа текстов для оценки общественного мнения //Научно-технический вестник информационных технологий, механики и оптики. – 2015. – Т. 15. – №. 1.
- Плавное введение в Natural Language Processing (NLP) / DataStart.URL:https://datastart.ru/blog/read/plavnoe-vvedenie-v-natural-language-processing-nlp (дата обращения 26.12.2021г).
- Р.Максутов Правильный NLP: как работают и что умеют системы обработки естественного языка / Tproger.URL: https://tproger.ru/articles/natural-language-processing/ (дата обращения: 26.12.2021г)
- Тенденции NLP в 2021 году / Smiddle.URL: https://smiddle.com/ru/news/86-tendentsii-nlp-2021 (дата обращения: 26.12.2021г)



