
1. Декомпозиция проблемы транскрибирования
Музыкальное транскрибирование – это процесс конвертации акустического музыкального сигнала в некоторую форму музыкальной нотации [2, с. 2]. Сама форма музыкальной нотации может быть различной: фортепианная лента, обычные ноты, MIDI-файл являются типовыми формами представления результатов алгоритма транскрибирования. Проблема автоматического транскрибирования музыки, как и любая другая комплексная проблема, может быть декомпозирована на целый ряд подзадач, решение которых может быть осуществлено тем или иным способом. Некоторые из этих подзадач могут в свою очередь быть декомпозированы на еще более простые подзадачи. При этом каждая из подзадач любой подобной декомпозиции также может быть решена различными способами, что обуславливает огромное многообразие возможных подходов к проблеме музыкального транскрибирования. Типовой алгоритм автоматического музыкального транскрибирования как правило включает: оценку мультитонов (нахождение фундаментальных частот для высот, звучащих в каждый момент времени музыкальной дорожки), обнаружение начал/окончаний звучания нот, оценка громкости звучания нот, отслеживание нот (преобразование наборов фундаментальных частот для последовательных кадров в набор нотных событий, подобный таковому для формата MIDI), распознавание инструментов, распознавание музыкального размера и тактов, обнаружение ритма [8, с. 1]. В представленной работе мы ограничимся рассмотрением только части перечисленных подзадач, и рассмотрим с нашей точки зрения ключевые три компоненты проблемы практически любого алгоритма транскрибирования: оценка мультитонов, обнаружение начал нот, и отслеживание нот.
Вообще говоря, два основных подхода к проблеме автоматического музыкального транскрибирования, которые чаще всего рассматриваются в тематических статьях это неотрицательная матричная факторизация и нейронные сети [17, с. 1]. Первый подход как правило решает только проблему оценки мультитонов (при этом для решения остальных подзадач музыкального транскрибирования используются ad hoc решения), тогда как при принятии второго подхода декомпозиция задачи музыкального транскрибирования на подзадачи в рамках используемой имплементации является архитектурным решением, которое разработчик принимает из соображений удобства. Подобная «гибкость» нейросетевых подходов по сравнению с «жесткими» вычислительными алгоритмами это не единственное различие двух рассматриваемых подходов. Как правило, традиционные методы на основе обработки сигналов характеризуются большей простотой, скоростью работы, и способностью к генерализации, тогда как нейронные сети достигают большей производительности при условии тонкой настройки [17, с. 2]. В дальнейшем повествовании мы постараемся проиллюстрировать преимущества и недостатки обоих подходов на конкретных примерах.
2. Неотрицательная матричная факторизация (NMF)
Цель неотрицательной матричной факторизации – аппроксимация неотрицательной матрицы размерности
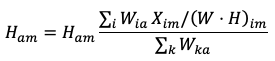 (1)
(1)
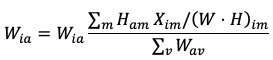 (2)
(2)
Преимуществами данного подхода является простота и быстрая сходимость. Также нетрудно заметить, что при условии неотрицательной инициализации матриц -дивергенции. Для действительных
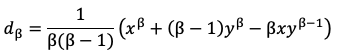 (3)
(3)
Формула 3 применима к сравнению двух действительных чисел, тогда как нам нужно оценить качество факторизации, т.е. сравнить исходную матрицу с произведением матриц ее разложения
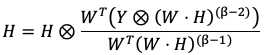 (4)
(4)
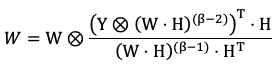 (5)
(5)
Здесь:
В некоторых вариациях вместо одновременного подбора матриц
Как уже упоминалось ранее, результаты непосредственно алгоритма неотрицательной матричной факторизации являются релевантным решением задачи оценки мульти-тонов, которая представляет собой ключевую составляющую практически любой системы транскрибирования. В сущности, матрица
Еще одним способом улучшить качество автоматического музыкального транскрибирования является использование информации о началах нотных событий. Это позволяет фиксировать результаты оценки мульти-тонов в рамках интервала между двумя последовательными началами нотных событий, что значительно сокращает пространство возможных решений задачи транскрибирования [14, с. 4]. Существует целый ряд подходов к обнаружению начал нотных событий, среди которых походы на основе: временных особенностей сигнала, особенностей амплитудного спектра сигнала, особенностей фазового спектра сигнала, и частотно-временного и масштабно-временного анализа [4, с. 3-5]. Наиболее простым и часто реализуемым (но в то же время достаточно эффективным) подходом является подход на основе особенностей амплитудного спектра сигнала, поэтому мы здесь кратко рассмотрим его. Как правило, фаза атаки ноты характеризуется значительным изменением спектрального шаблона сигнала, выражающимся в появлении в нем множества ранее не присутствовавших составляющих. Поэтому начало ноты можно достаточно точно зафиксировать по существенному росту спектральной разницы между двумя соседними кадрами спектрограммы сигнала. Спектральная разница между двумя соседними кадрами спектрограммы исходного сигнала вычисляется по следующей формуле [4, с. 4]:
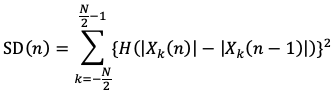 (6)
(6)
Здесь:
Подводя итог нашему рассмотрению неотрицательной матричной факторизации, перечислим основные ее недостатки: проблема подбора подходящего ранга факторизации
3. Нейронные сети
Последние десятилетия развития области обработки сигналов характеризуются все более обширным применением нейронных сетей для решения самых разных задач. Данная тенденция не обошла стороной и проблему музыкального транскрибирования, рассматриваемую в этой работе. В этом разделе представленной статьи мы не только рассмотрим некоторые известные решения проблемы транскрибирования на основе нейронных сетей, но и постараемся проследить тенденции, наблюдаемые в обсуждаемой предметной области.
Начать рассмотрение проблемы транскрибирования с помощью нейронных сетей, пожалуй, стоит с проблемы выбора представления входных данных. В их роли как правило используются представления исходного сигнала в виде спектрограмм, получаемые с помощью оконного преобразования Фурье [7, с. 1] или преобразования константы-Q [20, с. 9]. Также проблемой является проблема выбора конкретного представления исходного сигнала: использовать оконное преобразование Фурье с логарифмической шкалой или преобразование константы-Q, преобразовывать значения элементов спектрограммы в логарифмическую величину или не преобразовывать, относительно какого значения осуществлять это преобразование и т.д. Эмпирически установлено, что тип спектрограммы является вторым по относительной важности гиперпараметром моделей музыкального транскрибирования сразу после шага обучения модели [13, с. 4]. При этом самыми эффективными видами спектрограмм в этом исследовании оказались два типа спектрограмм: спектрограммы с линейно отстоящими отсчетами частотной оси без логарифмической преобразования амплитудных значений, и спектрограммы с логарифмически отстоящими отсчетами частотной оси с логарифмическим преобразованием амплитудных значений. Несмотря на это, как мы уже упоминали ранее, преобразование константы-Q является достаточно популярным выбором представления спектрограммы исходного сигнала.
Второй важной проблемой, касающейся применения нейронных сетей к проблеме музыкального транскрибирования, является проблема выбора архитектуры нейронной сети. Принципиальный архитектурный выбор заключается в выборе используемых функциональных слоев нейросети: использовать только полносвязные слои (класс таких моделей называют DNN), использовать только сверточные слои (класс таких моделей называют AllConv), или использовать смешанный подход, где сверточные слои следуют первыми после входного слоя, а после них следуют полносвязные слои (класс таких моделей называют ConvNet) [13, с. 5]. В целом, все три выбора обеспечивают хорошие результаты транскрибирования, при этом небольшим преимуществом среди этих трех классов обладает класс моделей, состоящих исключительно из сверточных слоев. Однако, архитектуры нейронных сетей для музыкального транскрибирования все же не исчерпываются перечисленными выше тремя классами. Возможность улучшить результаты транскрибирования с помощью адаптации архитектуры под потребности предметной области обуславливают использование более специфических и сложных архитектур нейронных сетей для транскрибирования. Глубокие нейронные сети хороши для обработки стационарных данных (например, изображений), но не приспособлены к обработке последовательных данных [20, с. 3]. Рекуррентные нейронные сети являются естественным расширением глубоких нейронных сетей, спроектированным специально для обработки последовательных данных. Поэтому, архитектура на основе рекуррентных нейронных сетей является одним из вариантов, который следует рассматривать при проектировании нейронной сети для решения задачи музыкального транскрибирования. Сами рекуррентные слои, применяемые в системах музыкального транскрибирования, могут быть различными, но как правило — это либо двунаправленные LSTM слои [7, с. 1] [11, c. 2], либо GRU слои [16, с. 4]. Дополнительным направлением исследований, которое открывают рекуррентные нейронные сети является направление моделей музыкального языка. Такие модели включают в себя информацию о временной структуре музыки, которая не включена в классические архитектуры систем транскрибирования. Например, большинство алгоритмов постобработки принимают в качестве гипотезы представление о том, что появление различных высот звуковой дорожки происходит независимо, тогда как встречающиеся одновременно высоты как правило скоррелированы (в силу наличия у музыки определенной гармонической структуры) [20, с. 4].
Теперь немного сместим фокус внимания с непосредственно архитектуры нейросети на сами обрабатываемые нейросетью данные. Если архитектура нейросети рассчитана под обработку спектрограмм, как правило она выражается функцией типа
Наконец, третьей проблемой, связанной с адаптацией нейронных сетей к решению проблемы музыкального транскрибирования является проблема обучения. Обучение эффективной системы транскрибирования требует обширной выборки выровненных по времени датасетов из исполнений музыки и нотаций для этих исполнений. Один из самых популярных датасетов такого рода, MAESTRO (что расшифровывается как «MIDI and Audio Edited for Synchronous Tracks and Organization») содержит более недели выровненных по времени аудио и MIDI треков, собранных за 9 лет международного конкурса исполнений на электронном фортепиано [17, c. 3]. Существует множество других датасетов, однако они, как правило, уступают MAESTRO либо по качеству, либо по объему. Еще одним популярным датасетом является MAPS (что расшифровывается как «The MIDI aligned piano sounds»), содержащий всего 65 часов фортепианной музыки, и вдобавок, включающий не только живые исполнения, но и изолированные ноты и случайные аккорды [5, c. 14]. Крупнейший музыкальный датасет фортепиано, GiantMIDI-Piano содержит 1 237 часов музыки из 10 855 треков, сочиненных 2 786 композиторами [17, c. 4]. К сожалению, с датасетами для других музыкальных инструментов ситуация обстоит значительно хуже, что вынуждает исследователей либо использовать техники аугментации данных, либо разрабатывать автоматизированные алгоритмы получения датасетов для требующегося инструмента. Типовые техники аугментации обучающих выборок включают временное сжатие дорожки и сдвиг дорожки по высоте [17, c. 4]. Применение данных техник позволяет значительно улучшить получаемые результаты при недостаточном объеме обучающего датасета. Теперь скажем несколько слов о конфигурации систем транскрибирования. Одной из типовых конфигураций систем транскрибирования является минимизация двоичной кросс-энтропии с помощью оптимизатора (алгоритма минимизации функции стоимости) Adam. При этом двоичная кросс-энтропия записывается в следующем виде [6, c. 3]:
![]() (7)
(7)
Здесь
Заключение
В представленной статье подробно рассмотрены два наиболее актуальных на данный момент подхода к музыкальному транскрибированию: неотрицательная матричная факторизация и нейронные сети.
В первом разделе статьи мы кратко рассматриваем формулировку проблемы музыкального транскрибирования, основные подзадачи музыкального транскрибирования и особенности двух ключевых подходов к проблеме транскрибирования, обсуждаемых в данной статье.
В разделе статьи про неотрицательную матричную факторизацию мы подробно рассмотрели постановку проблемы неотрицательной матричной факторизации, типовые решения данной проблемы, а также указали на существенные недостатки рассматриваемого подхода, обуславливающие большой исследовательский интерес к другим техникам транскрибирования. Сделан особый акцент на проблеме обнаружения начал нот, интеграция решения которой в виде отдельного блока алгоритма на основе неотрицательной матричной факторизации может существенно улучшить получаемые результаты.
В разделе статьи про нейронные сети как решение проблемы музыкального транскрибирования мы рассмотрели проблему выбора входного представления данных нейросети, проблему используемой архитектуры нейронных сетей, уделив пристальное внимание перспективному направлению декомпозиции архитектуры нейросети на функциональные блоки, а также проблему обучения нейросети. В статье подробно рассмотрены несколько существующих датасетов, которые можно применить для обучения моделей музыкального транскрибирования, а также наиболее популярная в предметной области функция стоимости – двоичная кросс-энтропия.
Список литературы
- Automatic music transcription using Non-negative matrix factorization // The Australian Acoustical Society URL: https://www.acoustics.asn.au/conference_proceedings/ICA2010/cdrom-ICA2010/papers/p507.pdf (дата обращения: 14.04.2026)
- Automatic Music Transcription: Challenges and Future Directions / Benetos E. [и др.] // Journal of Intelligent Information Systems. - 2013. - № 3. - С. 407-434
- Benetos E., Dixon S. Multiple-instrument polyphonic music transcription using a temporally constrained shift-invariant model // The Journal of the Acoustical Society of America. - 2013. - № 3. - С. 1727–1741
- A Tutorial on Onset Detection in Music Signals / Bello J. [и др.] // IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING. - 2005. - № 5. - С. 1035-1046
- Bhattarai B., Lee J. A Comprehensive Review on Music Transcription // Applied Sciences. - Basel: MDPI AG, 2023. - С. 11882-11901
- DEEP SALIENCE REPRESENTATIONS FOR F0 ESTIMATION IN POLYPHONIC MUSIC / Bittner R. [и др.] // Proceedings of the 18th International Society for Music Information Retrieval Conference, ISMIR 2017. - Suzhou: ISMIR, 2017. - С. 63-70
- Bock S., Schedl M. POLYPHONIC PIANO NOTE TRANSCRIPTION WITH RECURRENT NEURAL NETWORKS // 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). - Kyoto: IEEE, 2012. - С. 121-124
- Cogliati A., Duan Z., Wohlberg B. Piano music transcription with fast convolutional sparse coding // 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP). - Boston: IEEE, 2015. - С. 1-6
- Costantini G., Todisco M., Saggio G. Automatic music transcription based on non-negative matrix factorization // ICS'10: Proceedings of the 14th WSEAS international conference on Systems: part of the 14th WSEAS CSCC multiconference - Volume I. - Stevens Point: World Scientific and Engineering Academy and Society, 2010. - С. 288-291
- Dessein A., Cont A., Lemaitre G. REAL-TIME POLYPHONIC MUSIC TRANSCRIPTION WITH NON-NEGATIVE MATRIX FACTORIZATION AND BETA-DIVERGENCE // Proceedings of the 11th International Society for Music Information Retrieval Conference, ISMIR 2010. - Utrecht: ISMIR, 2010. - С. 489-494
- ONSETS AND FRAMES: DUAL-OBJECTIVE PIANO TRANSCRIPTION / Hawthorne C. [и др.] // Proceedings of the 19th International Society for Music Information Retrieval Conference, ISMIR 2018. - Paris: ISMIR, 2018. - С. 50-57
- Kelz R., Bock S., Widmer G. DEEP POLYPHONIC ADSR PIANO NOTE TRANSCRIPTION // ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). - Brighton: IEEE, 2019. - С. 246-250
- ON THE POTENTIAL OF SIMPLE FRAMEWISE APPROACHES TO PIANO TRANSCRIPTION / Kelz R. [и др.] // Proceedings of the 17th International Society for Music Information Retrieval Conference, ISMIR 2016. - New York City: ISMIR, 2016. - С. 475-481
- Khlif A., Sethu V. AN ITERATIVE MULTI RANGE NON-NEGATIVE MATRIX FACTORIZATION ALGORITHM FOR POLYPHONIC MUSIC TRANSCRIPTION // Proceedings of the 16th International Society for Music Information Retrieval Conference, ISMIR 2015. - Malaga: ISMIR, 2015. - С. 330-336
- Polyphonic Piano Music Transcription System Exploiting Mutual Correlations of Different Musical Note States / Kim T. [и др.] // IEEE Access. - 2024. - № 12. - С. 93689-93700
- High-Resolution Piano Transcription With Pedals by Regressing Onset and Offset Times / Kong Q. [и др.] // IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING. - Paris: IEEE, 2018. - С. 3707-3717
- MACHINE LEARNING TECHNIQUES IN AUTOMATIC MUSIC TRANSCRIPTION: A SYSTEMATIC SURVEY // arXiv.org e-Print archive URL: https://arxiv.org/pdf/2406.15249 (дата обращения: 14.04.2026)
- Niedermayer B. NON-NEGATIVE MATRIX DIVISION FOR THE AUTOMATIC TRANSCRIPTION OF POLYPHONIC MUSIC // Proceedings of the 9th International Conference on Music Information Retrieval, ISMIR 2008. - Philadelphia: ISMIR, 2008. - С. 544-549
- SEMI-SUPERVISED CONVOLUTIVE NMF FOR AUTOMATIC PIANO TRANSCRIPTION // arXiv.org e-Print archive URL: https://arxiv.org/pdf/2202.04989 (дата обращения: 14.04.2026)
- Sigtia S., Benetos E., Dixon S. An End-to-End Neural Network for Polyphonic Piano Music Transcription // IEEE/ACM Transactions on Audio, Speech, and Language Processing. - 2016. - № 5. - С. 927-939
- Smaragdis P., Brown J. Non-negative matrix factorization for polyphonic music transcription // 2003 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics. - New Paltz: IEEE, 2003. - С. 177-180



