
Социальная поддержка чаще всего видит человека через основание выплаты: малоимущая семья, инвалидность, одинокое проживание, наличие детей, повторное обращение. Для учета этого достаточно. Для управления — мало. В реестре рядом стоят низкий доход, иждивенцы, выплаты и частые обращения, а специалисту приходится держать в голове десятки сочетаний. Кластеризация нужна именно здесь: она собирает похожие административные профили в группы, с которыми можно работать.
Федеральный закон № 178-ФЗ закрепляет правовые и организационные основы государственной социальной помощи, а ЕГИССО формирует информационную среду, где сведения о мерах социальной защиты, получателях, документах, статистике и аналитике становятся частью единого контура [1; 3]. Закон № 152-ФЗ требует осторожного обращения с персональными данными, поэтому в исследовательской модели используются обезличенные записи [2]. В анализ идут не фамилия и адрес, а технический идентификатор, возраст, доход, состав семьи, выплаты, обращения, район и расчетный индекс уязвимости.
Цель статьи состоит в разработке подхода к кластеризации получателей мер социальной поддержки на основе административных признаков и индекса социальной уязвимости. Такая постановка отличается от обычной отчетности по льготным категориям. Отчет показывает, сколько граждан получили ту или иную меру. Кластеризация показывает, какие типы получателей образуются внутри массива: кто приходит часто, кто почти полностью зависит от выплат, у кого основная проблема связана с семейной нагрузкой, а у кого высокий индекс складывается из нескольких умеренных факторов сразу.
Алгоритм k-средних выбран из-за понятной логики и пригодности для больших табличных массивов. Дж. Маккуин описал k-means как процедуру разбиения многомерной совокупности на k групп [4]. В современных библиотеках этот алгоритм используется для минимизации внутрикластерной суммы квадратов; документация scikit-learn отдельно указывает на необходимость заранее заданного числа кластеров [5]. Для социальной поддержки это удобно: муниципальный массив может содержать тысячи записей, а метод работает без ручной разметки каждого случая.
Единицей кластеризации выступает обезличенная запись получателя. В признаковое пространство включаются возраст, среднедушевой доход, размер семьи, иждивенцы, занятость, инвалидность, выплаты, обращения, давность последнего обращения, районный коэффициент и индекс социальной уязвимости. Индекс не заменяет исходные признаки, а добавляет сжатую оценку общей напряженности. Только индекс обедняет модель; только отдельные признаки размывают общий уровень уязвимости.
Перед кластеризацией данные очищаются и стандартизируются. Без этого алгоритм начнет группировать шкалы измерения, а не получателей. Доход выражается в рублях, возраст - в годах, обращения - в штуках, индекс - в баллах. Поэтому числовые переменные приводятся к сопоставимому виду, а категориальные признаки кодируются так, чтобы они не создавали ложный порядок.
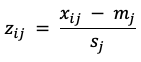 (1)
(1)
где:
После стандартизации формируется матрица признаков. Для каждого получателя модель видит не историю жизни и не юридическое основание выплаты, а набор чисел, отражающих административный профиль. В этом есть холодность метода, и ее нельзя прятать. Кластеризация не слышит объяснение заявителя, не различает случайную ошибку и резкое ухудшение ситуации. Ее сила в другом: она быстро показывает, какие записи похожи между собой и где в массиве возникают повторяющиеся социальные конфигурации.
Формально k-средних разбивает множество стандартизированных наблюдений на k кластеров так, чтобы расстояние между записями и центрами своих кластеров было минимальным. Внутри социальной задачи это читается проще: модель ищет группы получателей, в которых признаки складываются похожим образом. Один центр может соответствовать семьям с иждивенцами и высокой зависимостью от выплат, другой - одиноким пожилым получателям, третий - гражданам с частыми обращениями и средним уровнем доходной уязвимости.
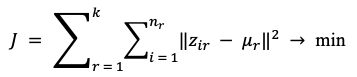 (2)
(2)
где:
Центр кластера рассчитывается как среднее значение векторов признаков, попавших в соответствующую группу. Это не “типичный человек” в бытовом смысле, а расчетный профиль. Но именно такой профиль удобен для интерпретации: по нему видно, что в одном кластере выше обращения, в другом - иждивенческая нагрузка, в третьем - возраст и зависимость от выплат.
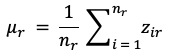 (3)
(3)
где:
Самое уязвимое место кластеризации - выбор числа кластеров. Два кластера почти неизбежно разобьют массив на условно легкие и тяжелые профили, а внутри потеряются различия. Десять кластеров дадут мелкую нарезку, которую трудно объяснить и использовать в отчете. Поэтому k выбирается по двум основаниям: техническому и управленческому. Техническая проверка смотрит на инерцию и силуэт; управленческая отвечает на более жесткий вопрос: сможет ли специалист назвать каждый кластер и понять, что с ним делать.
Для пилотной модели разумным стартом является k = 5. Такое число не дробит массив до бессмысленных микрогрупп и при этом не сжимает разные ситуации в две грубые категории. Пять кластеров позволяют отдельно увидеть умеренную нагрузку, семейную иждивенческую нагрузку, одиночное пожилое проживание, высокую обращаемость и плотную группу высокой уязвимости. Если после расчета две группы почти не отличаются по центрам, k можно уменьшить. Если один кластер оказывается слишком широким и внутри него смешиваются разные профили, k можно увеличить. В статье k = 5 рассматривается не как догма, а как рабочая конфигурация для первой интерпретации.
Названия кластеров не должны превращаться в ярлыки. Они нужны специалисту, чтобы быстрее понимать массив, но не должны подменять индивидуальную оценку. Получатель из кластера высокой обращаемости не обязан быть “проблемным заявителем”. Возможно, у него менялся состав семьи, документы несколько раз возвращались из-за ошибки, или межведомственная информация приходила с задержкой. Кластер дает повод посмотреть внимательнее, а не повод делать вывод за человека.
Таблица 1.
Административные признаки и их роль в кластеризации
|
Группа признаков |
Примеры переменных |
Что помогает увидеть |
|
Материальное положение |
доход, социальные выплаты, доля выплат |
зависимость семьи от регулярной поддержки |
|
Семейная нагрузка |
размер семьи, иждивенцы, возраст |
нагрузку на ограниченный доход |
|
Социальный статус |
занятость, инвалидность, семейное положение |
устойчивые ограничения выхода из нуждаемости |
|
Обращаемость |
число обращений, дата последнего обращения |
повторный контакт с системой социальной защиты |
|
Интегральная оценка |
индекс социальной уязвимости |
общий уровень социальной напряженности профиля |
Таблица показывает, что кластеризация не строится вокруг одного признака. Это принципиально: в социальной сфере опасно группировать получателей только по доходу или только по числу обращений. Низкий доход при малой семейной нагрузке и редких обращениях дает один профиль; тот же доход при инвалидности, иждивенцах и высокой доле выплат дает уже другую ситуацию для специалиста. Индекс социальной уязвимости нужен именно для того, чтобы эта разница не исчезала в общей массе строк.
Таблица 2.
Интерпретационная модель пяти кластеров
|
Кластер |
Рабочее название |
Отличительный профиль |
Управленческий смысл |
|
1 |
Умеренная нагрузка |
доход около порога, редкие обращения, умеренный индекс |
обычное наблюдение |
|
2 |
Семьи с иждивенцами |
крупная семья, иждивенцы, значимая доля выплат |
контроль семейной нагрузки |
|
3 |
Одинокие пожилые получатели |
высокий возраст, малый состав семьи, регулярная поддержка |
сопровождение и доступность услуг |
|
4 |
Высокая обращаемость |
частые и недавние обращения |
причины повторных контактов |
|
5 |
Высокая уязвимость |
одновременно выражены доход, выплаты, обращения, статус |
приоритетное внимание |
Интерпретационная модель не является эмпирическим результатом сама по себе; она задает язык, на котором читаются центры кластеров после расчета. Если алгоритм выдал пять групп, а исследователь не может описать их без слов “кластер 0” и “кластер 1”, модель еще не стала инструментом управления. Таблица 2 фиксирует профили, которые имеют смысл для социальной службы.
Оценивать качество кластеризации только внутренней метрикой недостаточно. Силуэт, инерция и расстояния между центрами полезны, но они не отвечают на главный вопрос: может ли специалист объяснить полученные группы. Поэтому после расчета строится профиль каждого кластера: средний возраст, средний индекс уязвимости, доля инвалидности, число обращений, размер семьи, зависимость от выплат и распределение по районам.
Для дополнительной проверки можно использовать силуэтный коэффициент. Он сравнивает близость записи к своему кластеру и удаленность от соседнего кластера. Высокое значение говорит о более четком разделении групп, низкое - о смешении профилей. Но и здесь нужна осторожность: социальные данные редко дают идеально круглые облака точек. Люди не обязаны укладываться в геометрию алгоритма.
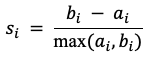 (4)
(4)
где:
Практический результат кластеризации проявляется в отчетах. Вместо длинной таблицы специалист получает несколько групп с понятным профилем: где проверить доходы, где посмотреть семейную нагрузку, где разобраться с частыми обращениями, где оценить зависимость от выплат. Так исчезает слепая зона, где разные случаи выглядят одинаково из-за формальной отчетности.
В связке с районным анализом модель становится еще полезнее. Повышенная доля кластера высокой обращаемости может указывать на перегрузку специалистов, проблемы документооборота или слабую доступность консультаций; концентрация семей с иждивенцами требует другого управленческого разговора - о семейной поддержке и устойчивости выплат. Так кластеризация перестает быть техническим приемом и превращается в карту нагрузки для муниципальной системы.
Ограничения метода нельзя прятать в конце как формальность. K-means чувствителен к масштабу признаков, начальному выбору центров и заранее заданному числу кластеров. Он лучше работает с компактными группами и может плохо описывать сложные, вытянутые или пересекающиеся структуры. В социальных данных это обычная ситуация: профиль семьи может одновременно быть похожим на группу с высокой иждивенческой нагрузкой и на группу с высокой зависимостью от выплат. Поэтому результат должен проверяться специалистом, а не приниматься как окончательная классификация.
Есть и правовое ограничение. Даже обезличенный массив требует аккуратной работы, потому что сочетание возраста, района, семейного состава, инвалидности и выплат может оставаться чувствительным. Для практического применения нужны разграничение доступа, журналирование действий, запрет лишней выгрузки детальных записей и отдельное хранение сведений, которые могут восстановить идентификацию. Без этого аналитика быстро теряет доверие, а в социальной сфере доверие стоит дороже любой модели.
Предложенный подход использует кластеризацию как следующий шаг после расчета индекса социальной уязвимости. Индекс дает общий балл напряженности, а k-means показывает, какие типы получателей стоят за этим баллом. В результате орган социальной защиты получает рабочую карту массива: где преобладает семейная нагрузка, где повторная обращаемость, где зависимость от выплат, где умеренный профиль, а где несколько факторов сжимаются в тяжелую комбинацию. Такая карта нужна муниципальному управлению, потому что решения принимаются не по среднему получателю, которого в жизни не существует, а по группам с разными причинами уязвимости.
Научная ценность статьи состоит в соединении административных признаков, индекса социальной уязвимости и метода k-средних в единую процедуру сегментации получателей мер поддержки. Практическая ценность связана с возможностью встроить результат в программное решение: подготовка признаков, расчет индекса, кластеризация, интерпретация групп и районные отчеты. Такой порядок помогает перейти от учета выплат к анализу социальных профилей.
Список литературы
- Федеральный закон от 17.07.1999 № 178-ФЗ «О государственной социальной помощи»
- Федеральный закон от 27.07.2006 № 152-ФЗ «О персональных данных»
- Единая государственная информационная система социального обеспечения: официальный информационный ресурс. URL: https://www.egisso.ru/
- MacQueen J. Some Methods for Classification and Analysis of Multivariate Observations // Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability. 1967. Vol. 1. P. 281–297
- Scikit-learn documentation. KMeans. URL: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
- Бычков Д. Г., Гришина Е. Е., Емцов Р. Г., Феоктистова О. А., Андреева Е. И. Развитие эффективной социальной поддержки населения в России: адресность, нуждаемость, универсальность. Научный доклад. М.: НИФИ, 2017

