
Introduction
The transition from traditional software-as-a-service models to AI-centric architectures has introduced a new paradigm of operational expenditure characterized by extreme non-linear costs and supply-chain constraints. Unlike traditional cloud workloads that benefit from mature auto-scaling and predictable resource consumption, AI workloads are heavily dependent on Graphics Processing Units (GPUs) and specialized accelerators which are both expensive and scarce. In this environment, the traditional FinOps lifecycle of Inform, Optimize, and Operate must be reimagined to account for the probabilistic nature of AI development. Innovation velocity—the speed at which research teams can iterate on models—often comes at the direct expense of cost governance, creating a friction point that can stall digital transformation efforts. As hardware costs begin to consume a disproportionate share of IT budgets, the necessity for a specialized FinOps framework for AI becomes evident. This paper seeks to bridge the gap between the technical requirements of high-performance computing and the strategic mandates of corporate finance, providing a roadmap for sustainable AI scaling.
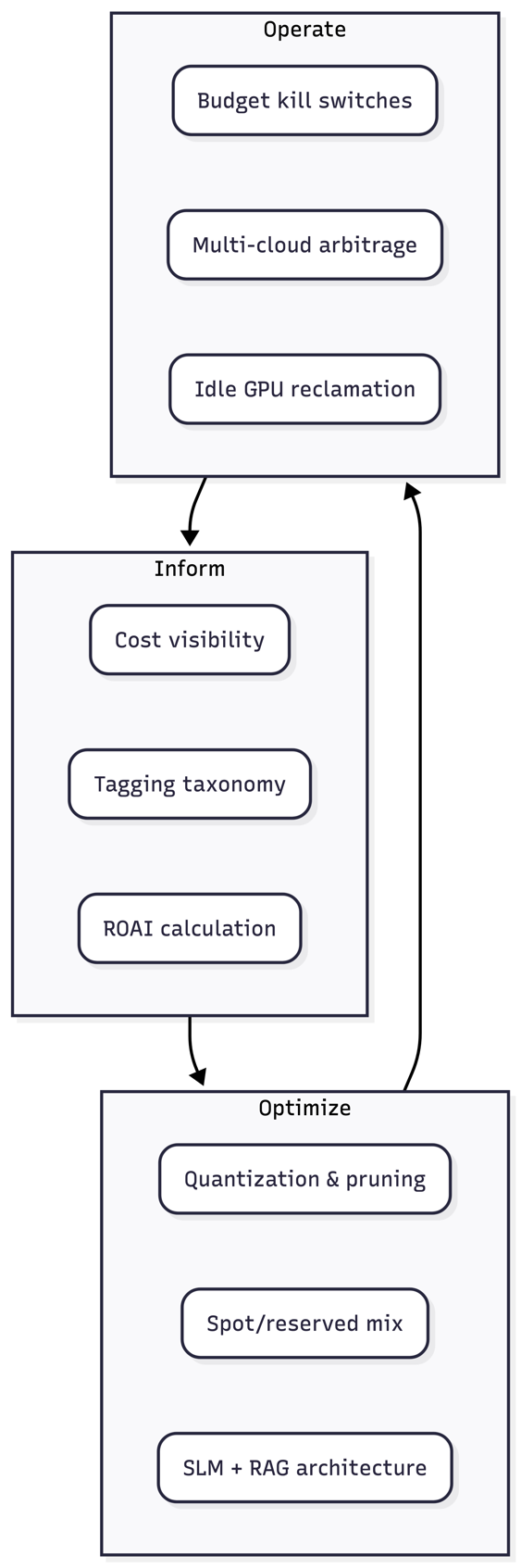
Image 1.
The core of the challenge in governing AI costs lies in the fundamental difference between deterministic computing and the iterative, often unpredictable nature of machine learning lifecycles. Traditional FinOps practices rely on historical data to project future spending, yet AI workloads frequently exhibit "spiky" consumption patterns during training phases and high-latency, high-cost inference demands during production. To address this, a specialized FinOps for AI framework must prioritize granular visibility at the model and project level. This involves implementing advanced tagging strategies that go beyond simple department-level billing to include metadata such as model version, dataset size, and experiment ID.
Without this level of detail, organizations cannot accurately calculate the Return on AI Investment (ROAI), leading to inefficient capital allocation.
Practical tagging taxonomy. A robust tagging strategy for AI workloads goes beyond cost centres and requires a multi‑level hierarchy of labels. Example:
project: customer-chatbot
stage: fine-tuning | inference | evaluation
model: llama-3-8b
experiment-id: exp-2025-04-15-lr-sweep
dataset: support-tickets-v3
owner-team: ai-platform
cost-budget-limit: 500
These labels are embedded in every GPU instance, storage bucket, and job manifest. Infrastructure‑as‑Code (Terraform, Azure Policy) enforces that any resource without the mandatory tags is immediately stopped or blocked from creation.
Unit economics for AI. With accurate labels, organisations can define actionable cost metrics:
- Cost per fine‑tuning run = (GPU‑hours × on‑demand rate) or (spot price × (1 + checkpoint‑recovery overhead %))
- Cost per 1,000 tokens for inference (input, output separately)
- Cost per successful experiment that led to a metric improvement (e.g., 2% accuracy gain)
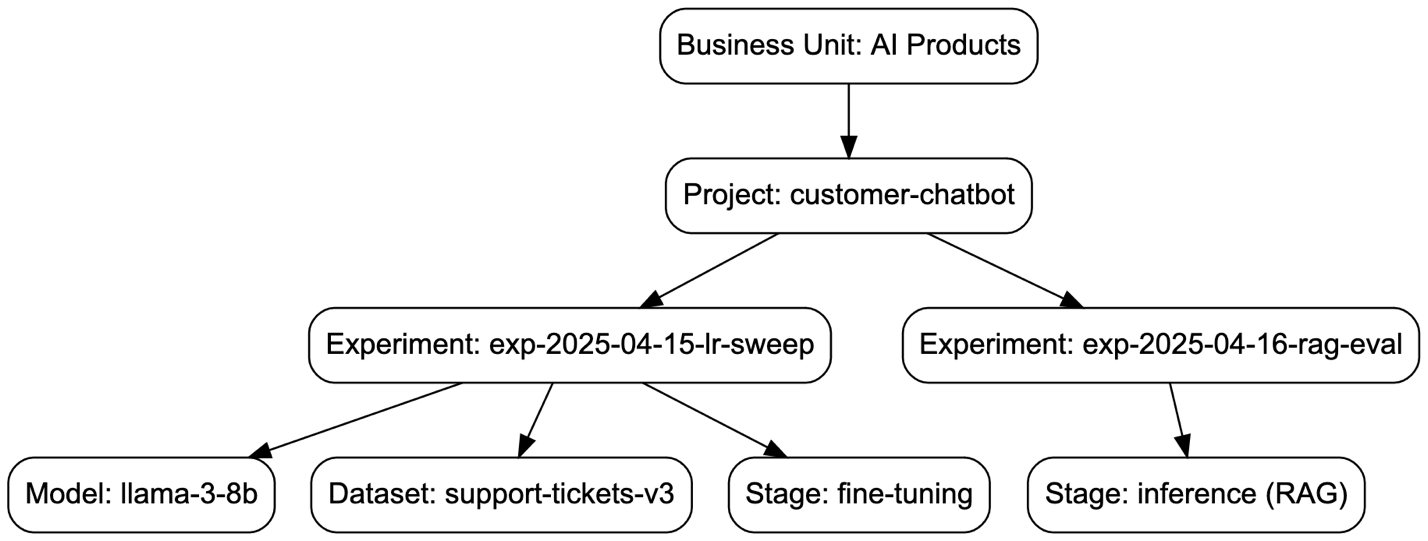
Image 2.
These numbers are fed into development environments. A real‑time “burn rate” widget in MLflow or Jupyter turns red when an experiment’s spend exceeds 80 % of its budget, creating immediate fiscal awareness without leaving the research workflow.
A critical component of cost governance is the strategic management of GPU compute. Enterprises must navigate a complex hierarchy of procurement options, ranging from on-demand instances for rapid prototyping to reserved instances and long-term commitments for stable production environments. Furthermore, the use of preemptible or spot instances offers significant cost savings—often up to ninety percent—but requires sophisticated engineering to handle interruptions, such as checkpointing model weights and utilizing resilient job orchestrators like Kubernetes with specialized deschedulers.
Procurement decision framework. A practical GPU procurement strategy follows a simple decision tree:
- On‑demand instances for short‑lived prototyping and interactive notebooks (0–2 hours), where the overhead of spot interruption outweighs the savings.
- Reserved capacity (1‑ or 3‑year commitments) for steady‑state inference clusters and always‑on training jobs, offering 30–50 % cost reductions relative to on‑demand.
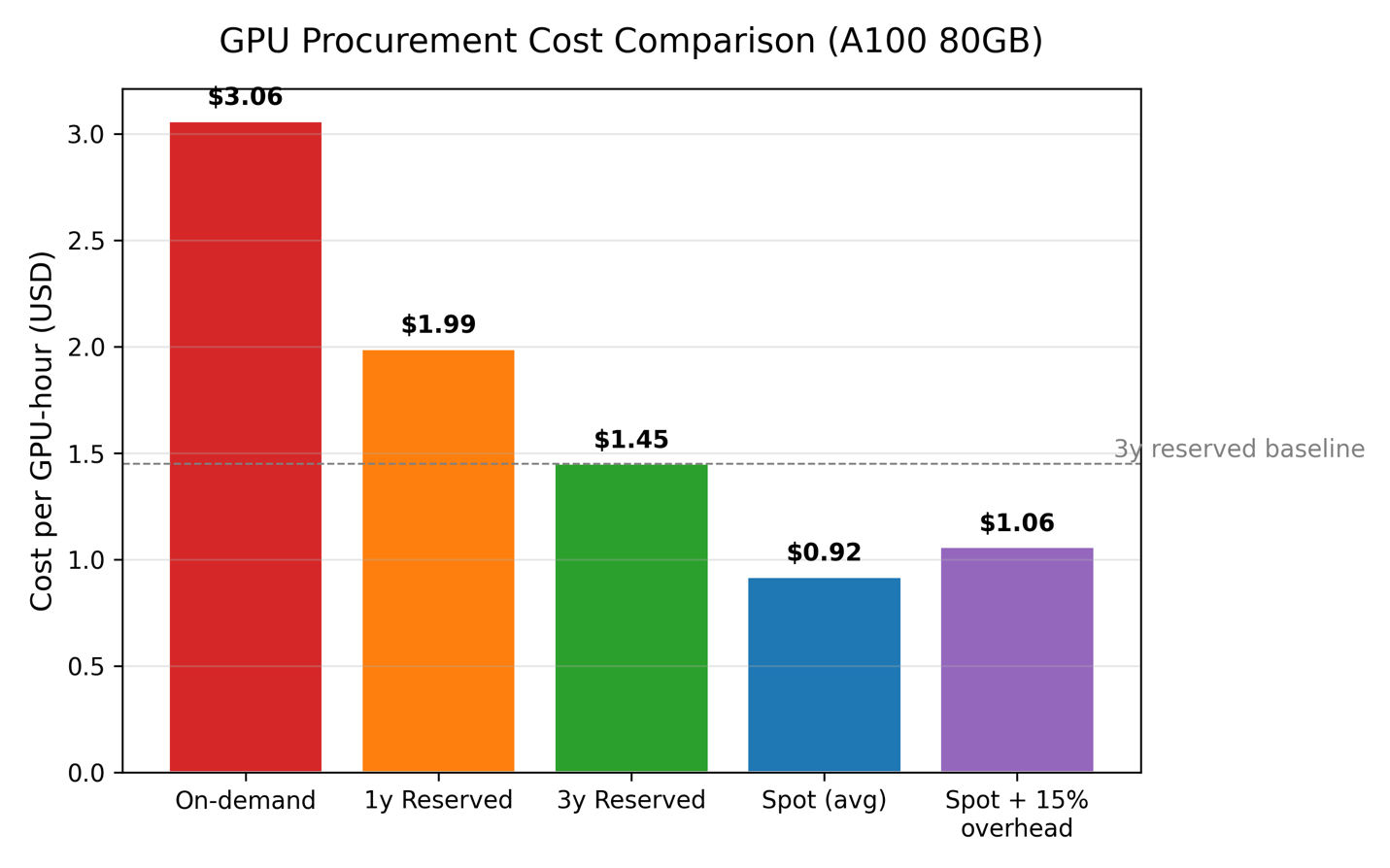
Image 3.
- Spot/preemptible instances for fault‑tolerant, long‑running training jobs. These can reduce costs by up to 90 %, provided the workload implements incremental checkpointing to object storage (e.g., S3) and a container orchestrator that can gracefully reschedule preempted pods (e.g., AWS Karpenter, Volcano).
Multi‑cloud arbitrage implementation. A multi‑cloud GPU orchestrator (e.g., SkyPilot, a custom K8s federation) continuously queries real‑time pricing APIs from AWS, Azure, GCP, and specialised GPU clouds (CoreWeave, Lambda Labs). A job specification includes a cost‑threshold parameter; the scheduler then places the workload on the cheapest available cluster that meets the GPU type and memory constraints. The orchestrator also manages data locality, copying datasets from a central lake to the target region if transfer time does not negate the compute savings.
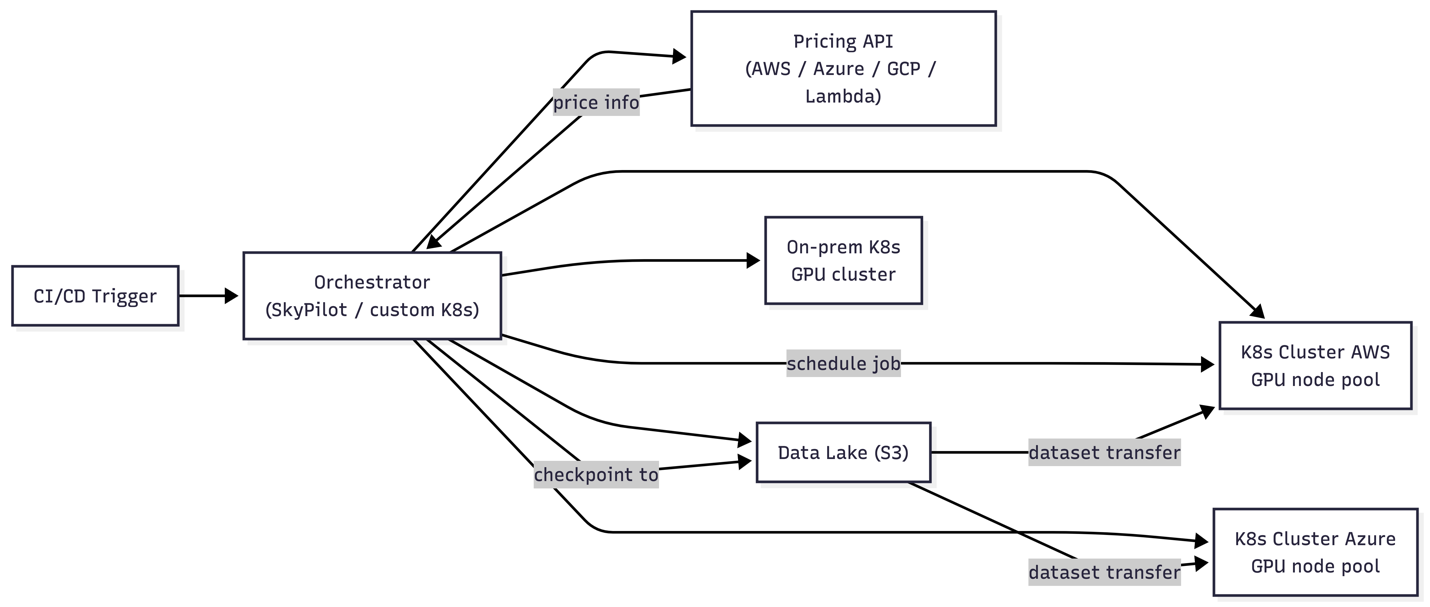
Image 4.
Hybrid‑cloud bursting. Enterprises with amortised on‑premises GPU clusters can handle 80 % of steady load internally and burst to the public cloud for peak demand. This is achieved by federating on‑prem Kubernetes with cloud GPU node pools using cluster‑autoscaler and setting priority‑based pod preemption, ensuring that cloud resources are only used when on‑prem capacity is exhausted. Long‑term enterprise agreements with cloud providers can further reduce the burst rate for reserved capacity, turning cloud expenditure into a predictable variable cost. Another major factor is the optimization of the AI pipeline itself.
Cost-efficient AI is not merely about buying cheaper compute; it is about reducing the total floating-point operations required to achieve a desired outcome. Techniques such as quantization, where model precision is reduced from 32-bit to 8-bit or 4-bit, and pruning, which removes redundant parameters, play a vital role in reducing the memory footprint and inference costs. Additionally, the shift toward "Small Language Models" (SLMs) and Retrieval-Augmented Generation (RAG) represents a strategic move to maintain innovation while minimizing the need for massive, high-cost retraining cycles of foundation models.
Quantization in practice. Tools like bitsandbytes or GPTQ can load a 7B‑parameter model in 4‑bit precision, reducing GPU memory from approximately 14 GB (FP16) to under 4 GB. This allows inference on a single T4 or A10G instead of an A100, cutting cost per million tokens by up to 80 %. A typical quantization configuration for QLoRA keeps base weights in 4‑bit while training low‑rank adapters in BF16, preserving near‑full accuracy.
Pruning and distillation benchmarks. Unstructured pruning methods like SparseGPT can remove 50 % of a model’s parameters while maintaining 90–95 % of the original accuracy. Knowledge distillation (e.g., DistilBERT) produces smaller, faster models with only 60 % of the original parameters but 95 % of the performance. The cost‑accuracy curve shows that these compressed models sit on a “Pareto frontier” where further compression hurts quality disproportionately; FinOps dashboards should track this frontier per project.
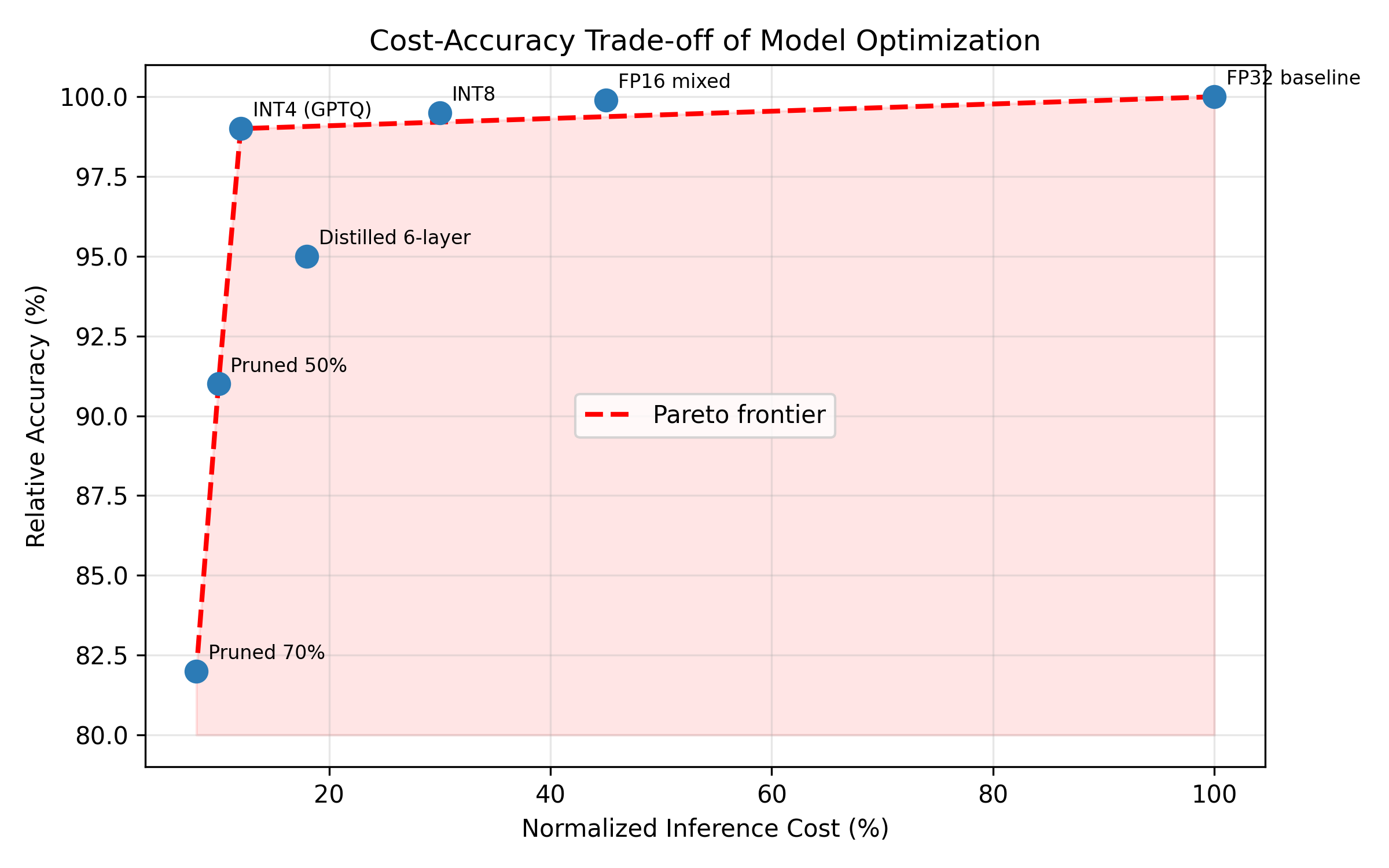
Image 5.
RAG as a cost‑avoidance architecture. Instead of fine‑tuning a large foundation model on domain‑specific data, a retrieval‑augmented generation pipeline stores documents in a vector database (Pinecone, pgvector) and queries a smaller, static model. Updating the knowledge base costs a fraction of a retraining cycle. For example, a 70B model fine‑tuned monthly might cost 100k, while a RAG system with a frozen 7B model and weekly vector index rebuilds costs under 100k,while a RAG system with a frozen 7B model and weekly vector index rebuilds costs under 5k, achieving comparable accuracy on factual queries.
Speculative decoding. A recent inference optimisation employs a small draft model (e.g., a 3‑layer transformer) to propose multiple token candidates, which a large model verifies in parallel. This reduces latency by 2–3× and lowers per‑token cost proportionally, without any accuracy loss. Frameworks like vLLM and TensorRT‑LLM support this natively.
Governance in this context also requires a cultural shift toward "unit economics," where data scientists are empowered with real-time cost feedback within their development environments, such as Jupyter notebooks or MLflow dashboards. This democratization of cost data encourages the development of "frugal AI," where model complexity is weighed against its economic impact from the very first line of code. The integration of automated guardrails, such as budget-based killing of orphaned training jobs and automated rightsizing of inference clusters based on real-time token throughput, ensures that governance is proactive rather than reactive.
Budget‑enforcement operator. In a Kubernetes‑native AI platform, a custom admission controller intercepts every training or inference pod creation. It reads a finops label (e.g., max‑cost‑per‑run: 300 USD) and compares it against a real‑time cost API. If the allowed budget is exceeded, the pod is rejected or gracefully terminated. Notifications are routed to Slack and a FinOps dashboard.
Idle GPU detection and draining. A lightweight daemon runs on every GPU node, collecting utilisation metrics via nvidia‑smi or DCGM. If a GPU remains below 10 % utilisation for 15 consecutive minutes, the node is automatically cordoned and drained, and a snapshot of the job state is uploaded to persistent storage. This reclaims expensive resources without data loss.
Token‑throughput‑based inference autoscaling. Traditional CPU/memory‑based autoscaling is insufficient for LLM inference. Instead, a Kubernetes‑native event‑driven autoscaler (KEDA) scales the number of inference replicas based on prompt_tokens_per_second and generation_tokens_per_second metrics exposed by the model server (e.g., vLLM, Triton). Minimum and maximum replica counts are linked to hourly cost limits, preventing a sudden traffic spike from creating runaway expenses.
Pipeline kill switches. In orchestrators like Kubeflow or Airflow, a dedicated sensor task queries the cloud provider’s cost API before launching expensive training steps. If the cumulative project spend has reached a predefined budget threshold, the pipeline fails gracefully, preserving partial results and logging the reason for auditability.
By aligning the incentives of the engineering, data science, and finance teams, organizations can create a virtuous cycle where cost savings are reinvested into further innovation, thereby accelerating velocity without compromising fiscal health. Multi-cloud and hybrid-cloud strategies also emerge as pivotal, allowing firms to arbitrage GPU pricing across different providers and utilize on-premises hardware for steady-state workloads while bursting to the cloud for peak training demands. Ultimately, FinOps for AI is about transforming cost from a static constraint into a dynamic variable that can be optimized to drive maximum business value.
Emerging Challenges in AI FinOps
Token‑based pricing unpredictability. Managed AI services (OpenAI, Azure OpenAI) charge per 1,000 tokens, with distinct rates for input and output. Multi‑agent chains or recursive reasoning loops multiply token consumption non‑linearly, making cost forecasting difficult. FinOps for AI must adopt token‑level monitoring and per‑call cost caps.
Spot‑instance scarcity in GPU‑starved regions. GPU spot capacity is increasingly reclaimed with little notice. Workloads must support frequent checkpointing (every 50–100 steps) and rapid job rescheduling across regions or providers, adding operational complexity and a small but measurable overhead.
Carbon accounting as a financial metric. Many enterprises now operate internal carbon budgets or face carbon taxes. GPU‑hours directly translate to CO₂‑eq emissions. FinOps tools must integrate carbon telemetry, attaching a shadow carbon price to each AI job and enabling a model‑training sustainability report alongside cost reports.
Regulatory data gravity. Data residency laws (GDPR, EU AI Act) mandate that training data remain in‑region, limiting multi‑cloud flexibility. This reduces negotiating leverage and locks organisations into regional GPU providers, potentially increasing cost and decreasing spot availability.
Shadow AI and unsanctioned API usage. Employees using consumer AI tools or unregulated API keys create “shadow AI” spending that sits outside central FinOps visibility. Governance must include API key inventory scanning, usage anomaly detection, and automatic de‑provisioning of unapproved keys.
Hardware lock‑in and accelerated depreciation. On‑premises GPU investments (e.g., H100 clusters) depreciate rapidly as new generations (H200, B200) arrive. FinOps must model total cost of ownership over a 3‑year lifecycle, including residual value and the opportunity cost of missing future hardware innovation.
Conclusion
In conclusion, the successful integration of artificial intelligence into the enterprise depends as much on economic management as it does on algorithmic breakthroughs. FinOps for AI workloads provides the necessary structure to navigate the "GPU era," offering a sophisticated approach to cost governance that does not stifle the creative energy of research and development teams. By focusing on granular visibility, architectural optimization, and strategic procurement, organizations can mitigate the risks of unconstrained spending.
The balance between innovation velocity and cost governance is not a zero-sum game; rather, a robust FinOps practice acts as a catalyst for sustainable growth, allowing enterprises to scale their AI ambitions while maintaining a clear view of the bottom line. As AI hardware continues to evolve and the demand for tokens grows exponentially, the principles of AI-native financial management will become the cornerstone of successful corporate strategy in the digital age.
Source code:
Image 1:
graph TD
subgraph Inform
I1(Cost visibility)
I2(Tagging taxonomy)
I3(ROAI calculation)
end
subgraph Optimize
O1(Quantization & pruning)
O2(Spot/reserved mix)
O3(SLM + RAG architecture)
end
subgraph Operate
P1(Budget kill switches)
P2(Multi-cloud arbitrage)
P3(Idle GPU reclamation)
end
Inform --> Optimize
Optimize --> Operate
Operate --> Inform
Image 2.
digraph G {
rankdir=TB;
node [shape=box, style=rounded, fontname="Arial"];
root [label="Business Unit: AI Products"];
proj [label="Project: customer-chatbot"];
exp1 [label="Experiment: exp-2025-04-15-lr-sweep"];
exp2 [label="Experiment: exp-2025-04-16-rag-eval"];
model [label="Model: llama-3-8b"];
dataset [label="Dataset: support-tickets-v3"];
stage1 [label="Stage: fine-tuning"];
stage2 [label="Stage: inference (RAG)"];
root -> proj;
proj -> exp1;
proj -> exp2;
exp1 -> model;
exp1 -> dataset;
exp1 -> stage1;
exp2 -> stage2;
}
Image 3.
import matplotlib.pyplot as plt
categories = ['On-demand', '1y Reserved', '3y Reserved', 'Spot (avg)', 'Spot + 15%\noverhead']
costs = [3.06, 1.99, 1.45, 0.92, 1.06]
colors = ['#d62728', '#ff7f0e', '#2ca02c', '#1f77b4', '#9467bd']
fig, ax = plt.subplots(figsize=(8, 5))
bars = ax.bar(categories, costs, color=colors, edgecolor='white')
# Add value labels
for bar, val in zip(bars, costs):
ax.text(bar.get_x() + bar.get_width()/2, val + 0.05, f'${val:.2f}',
ha='center', va='bottom', fontweight='bold')
ax.set_ylabel('Cost per GPU-hour (USD)', fontsize=12)
ax.set_title('GPU Procurement Cost Comparison (A100 80GB)', fontsize=14, pad=15)
ax.axhline(y=1.45, color='gray', linestyle='--', linewidth=0.8)
ax.text(4.5, 1.48, '3y reserved baseline', fontsize=10, color='gray')
ax.grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.savefig('gpu_pricing_comparison.png', dpi=300)
plt.show()
Image 4.
graph LR
A[CI/CD Trigger] --> B["Orchestrator<br/>(SkyPilot / custom K8s)"]
B --> C["Pricing API<br/>(AWS / Azure / GCP / Lambda)"]
B --> D["Data Lake (S3)"]
B --> E[K8s Cluster AWS<br/>GPU node pool]
B --> F[K8s Cluster Azure<br/>GPU node pool]
B --> G[On-prem K8s<br/>GPU cluster]
C -- price info --> B
B -- schedule job --> E
B -- checkpoint to --> D
D -- dataset transfer --> E
D -- dataset transfer --> F
Image 5.
import numpy as np
import matplotlib.pyplot as plt
techniques = ['FP32 baseline', 'FP16 mixed', 'INT8', 'INT4 (GPTQ)',
'Distilled 6-layer', 'Pruned 50%', 'Pruned 70%']
accuracy = [100, 99.9, 99.5, 99.0, 95.0, 91.0, 82.0]
cost = [100, 45, 30, 12, 18, 10, 8]
frontier_idx = [0, 3, 5, 6] # points on Pareto frontier
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(cost, accuracy, color='#2c7bb6', s=80, zorder=3)
# Label each point
for i, tech in enumerate(techniques):
ax.annotate(tech, (cost[i], accuracy[i]), textcoords="offset points",
xytext=(5,5), fontsize=8)
# Connect Pareto frontier
frontier_cost = [cost[i] for i in frontier_idx]
frontier_acc = [accuracy[i] for i in frontier_idx]
ax.plot(frontier_cost, frontier_acc, 'r--', linewidth=2, label='Pareto frontier')
ax.fill_between(frontier_cost, 80, frontier_acc, alpha=0.1, color='red')
ax.set_xlabel('Normalized Inference Cost (%)')
ax.set_ylabel('Relative Accuracy (%)')
ax.set_title('Cost-Accuracy Trade-off of Model Optimization')
ax.legend()
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig('cost_accuracy_tradeoff.png', dpi=300)
plt.show()
Список литературы
- Amin, A., & Adhikari, M. (2023). Resource management and scheduling in cloud-based deep learning: A survey. Journal of Cloud Computing, 12(1), 45-68
- Amodei, D., & Hernandez, D. (2018). AI and Compute. OpenAI. Retrieved from https://openai.com/blog/ai-and-compute/
- Cloud FinOps: Collaborative, Real-Time Cloud Financial Management (2nd ed.) by J.R. Storment and M. Fuller. O'Reilly Media, 2023
- Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2024). QLoRA: Efficient Finetuning of Quantized LLMs. Advances in Neural Information Processing Systems, 36
- FinOps Foundation. (2024). The State of FinOps for AI: Managing the Cost of Generative AI. Technical Report
- Gholami, A., Kim, S., Dong, Z., Yao, Z., Mahoney, M. W., & Keutzer, K. (2021). A Survey of Quantization Methods for Efficient Neural Network Inference. Low-Power Computer Vision, 235-256
- Hoffmann, J., Borgeaud, S., Mensch, A., et al. (2022). Training Compute-Optimal Large Language Models. arXiv preprint arXiv:2203.15556. (The Chinchilla Paper)
- Kaplan, J., McCandlish, S., Henighan, T., et al. (2020). Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361
- Li, B., & Tan, L. (2023). Cost-Aware Orchestration of GPU Resources for Large-Scale AI Training. IEEE Transactions on Parallel and Distributed Systems, 34(5), 1412-1428
- Patterson, D., Gonzalez, J., Le, Q., et al. (2021). Carbon Emissions and Large Neural Network Training. arXiv preprint arXiv:2104.10350. (Analysis of compute efficiency and cost)
- Rengasamy, V., & Roth, P. C. (2022). Characterizing the GPU Resource Utilization of Modern AI Workloads. Proceedings of the International Conference on High Performance Computing, 112-124
- Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108
- Touvron, H., Lavril, T., Izacard, G., et al. (2023). Llama: Open and Efficient Foundation Language Models. Meta AI Technical Report (The Meta organization is recognized as extremist in Russia and is banned)
- Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30. (Foundational for GPU memory estimation)
- Wang, Y., & Zhao, H. (2023). Spot Instance Bidding Strategies for Deep Learning Workloads in Public Clouds. IEEE Cloud Computing, 10(2), 24-33



