
Общая архитектура системы
Реализованная схема RAG включает три основных уровня: подготовку данных, семантический поиск и генерацию ответа. На этапе подготовки данные извлекаются из PDF и текстовых файлов, затем разбиваются на фрагменты фиксированного размера. После этого каждый фрагмент преобразуется в векторное представление при помощи embedding-модели и помещается в индекс FAISS [1]. На этапе запроса пользовательский вопрос кодируется в вектор, после чего выполняется поиск ближайших кандидатов. Далее кандидаты проходят дополнительный этап reranking, позволяющий повысить качество итоговой выборки. Только после этого наиболее релевантные фрагменты передаются в генеративную модель, которая формирует ответ.
Такой подход отличается от обычного вопросно-ответного сценария тем, что между запросом пользователя и генерацией ответа находится полноценный этап retrieval. Именно он делает систему контекстно-ориентированной и позволяет использовать внешнюю базу знаний вместо неявной памяти модели.
Загрузка и подготовка документов
Любая RAG-система начинается не с модели, а с данных. В данной реализации предусмотрена работа с файлами двух типов: PDF и TXT. Для этого используются стандартные загрузчики PyPDFLoader и TextLoader [1]. Подобный выбор оправдан тем, что именно PDF и текстовые документы чаще всего встречаются в корпоративных архивах, справочниках и технической документации.
После загрузки документы проходят этап разбиения на фрагменты. В коде используется RecursiveCharacterTextSplitter, который позволяет нарезать текст по смысловым границам, стараясь сохранить структуру абзацев и предложений. Это особенно важно, потому что слишком крупные фрагменты ухудшают точность поиска, а слишком мелкие могут потерять содержательную связность.
В используемой конфигурации размер чанка составляет 1000 символов, а перекрытие — 250 символов. Такое сочетание параметров позволяет сохранить информацию на стыках соседних фрагментов и уменьшить риск того, что важная мысль окажется разорванной между двумя chunk’ами.
Простейшая логика этого этапа на рисунке 1:
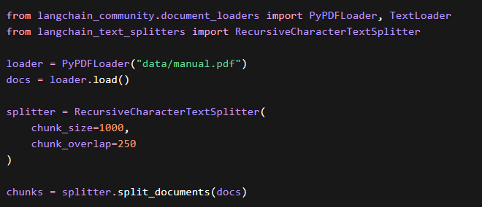
Рисунок 1. Загрузка документа и разбиение на чанки
После разбиения каждый фрагмент документа сохраняется как самостоятельная единица поиска. Это важно, поскольку именно chunk становится основной сущностью, с которой дальше работает retrieval-механизм.
Эмбеддинги и векторное представление текста
Ключевым элементом всей RAG-архитектуры является модель эмбеддингов. Она переводит текстовый фрагмент в числовой вектор, который можно сравнивать с другими векторами по семантической близости. В рассматриваемой реализации используется модель Qwen/Qwen3-Embedding-0.6B, загружаемая через AutoTokenizer и AutoModel [2].
Эмбеддинги играют роль промежуточного языка между текстом и математическим поиском. Вместо того чтобы искать совпадения по словам, система сопоставляет смысловые представления текста. Это особенно полезно, когда формулировка запроса и документ отличаются лексически, но совпадают по смыслу.
Отдельного внимания заслуживает способ агрегации скрытых состояний. В коде используется функция last_token_pool, которая извлекает представление последнего значимого токена с учётом attention mask. После этого эмбеддинты нормализуются по L2-норме. Такая нормализация делает векторное пространство более удобным для вычисления расстояний и сопоставления фрагментов.
Практическая ценность такой схемы состоит в том, что она позволяет построить единое векторное пространство для документов и запросов. В результате запрос пользователя можно сравнивать с фрагментами базы знаний не по поверхностному совпадению, а по смысловой близости.
Построение и использование FAISS-индекса
После получения эмбеддингов документы необходимо сохранить в структуре, пригодной для быстрого поиска. Для этого используется FAISS — одна из наиболее известных библиотек для поиска ближайших соседей в векторном пространстве. В данной реализации выбран IndexFlatL2, то есть простой индекс, основанный на L2-расстоянии [2].
FAISS хорошо подходит для локальных систем, поскольку обеспечивает быстрый поиск и не требует сложной инфраструктуры. Это делает его удобным для прототипов, исследовательских решений и небольших прикладных систем, где база документов ещё не достигла промышленного масштаба.
Построение индекса в упрощённом виде выглядит следующим образом (рисунок 2):
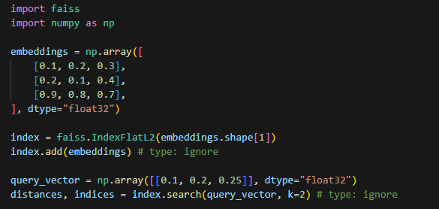
Рисунок 2. Построение индекса
В реальной реализации сначала индексируется весь набор фрагментов документов, а затем при поступлении запроса выполняется поиск top-k наиболее близких chunks. Важно понимать, что этот этап даёт только кандидатов. Он ещё не гарантирует, что найденные фрагменты действительно являются лучшими с точки зрения конечного вопроса. Поэтому после первичного retrieval следует reranking.
Первичный retrieval и reranking
Первичный поиск по векторному индексу обычно решает задачу полноты: система старается быстро найти все фрагменты, которые потенциально могут быть полезны. Однако семантическая близость не всегда означает точную релевантность. Иногда документ содержит похожие формулировки, но отвечает совсем на другой вопрос. Именно поэтому в RAG-системах часто используют дополнительный reranker.
В рассматриваемой реализации reranker построен на модели Qwen/Qwen3-Reranker-0.6B. В отличие от embedding-модели, которая работает на уровне общего представления текста, reranker оценивает конкретную пару “запрос — документ”. Это делает его более точным инструментом для финального отбора источников.
Суть reranking можно описать как переоценку кандидатов после первичного поиска. Сначала FAISS возвращает, например, 100 наиболее близких фрагментов. Затем каждый из них проходит через reranker, который присваивает score релевантности. После этого документы сортируются по убыванию score, и в prompt попадает только верхняя часть списка.
Упрощённо эта логика может выглядеть ниже на рисунке 3:
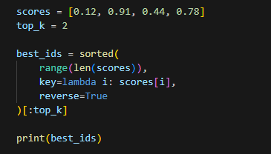
Рисунок 3. Упрощенная логика сортировки
В более сложной форме reranker использует текстовую инструкцию, в которой ему предлагается оценить соответствие документа запросу. В коде это реализовано через шаблон, содержащий Instruct, Query и Document. Затем по логитам последних токенов вычисляется вероятность того, что фрагмент действительно отвечает на вопрос.
Такой подход важен по двум причинам. Во-первых, он повышает точность выбора контекста. Во-вторых, он уменьшает риск того, что генеративная модель получит лишние или нерелевантные данные, из-за которых ответ станет менее точным.
Формирование prompt и передача контекста в LLM
После отбора лучших документов начинается этап генерации. Здесь особенно важен prompt, поскольку именно он связывает retrieval и generation в единую цепочку. В данной реализации используется подход context injection: найденные фрагменты текста вставляются прямо в запрос к модели. Это означает, что генератор получает не просто вопрос, а вопрос вместе с контекстом, извлечённым из документов.
Формирование prompt начинается с добавления инструкции, ограничивающей поведение модели. В частности, явно задаётся требование использовать только предоставленный контекст и не допускать генерации ответа “из общих знаний”. После этого к пользовательскому запросу последовательно добавляются отобранные фрагменты документов, каждый из которых оформляется как отдельный блок, пример на рисунке 4 ниже:

Рисунок 4. Подготовка промпта
Таким образом формируется единый текст, содержащий вопрос и набор релевантных фрагментов, на основе которых модель должна построить ответ.
Далее prompt приводится к формату, ожидаемому диалоговой моделью. Для этого используется chat-шаблон, в котором сформированный текст передаётся как сообщение пользователя. После этого выполняется токенизация и перенос входных данных на устройство, пример на рисунке 5 ниже:
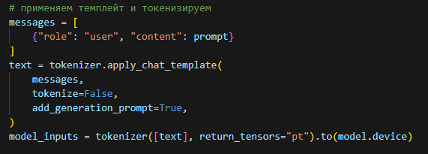
Рисунок 5. Подготовка и токенизация текста
Генерация ответа осуществляется с помощью метода generate с ограничением на максимальную длину, пример ниже на рисунке 6:
Рисунок 6. Генерация текста
Поскольку выход модели включает исходный prompt, на следующем этапе выделяется только сгенерированная часть (рисунок 7). Дополнительно учитывается особенность используемой модели, связанная с наличием внутреннего reasoning-блока, который удаляется из финального ответа:

Рисунок 7. Итоговая генерация ответа
В результате на выходе получается ответ, сформированный языковой моделью строго на основе переданного контекста, что обеспечивает связку между этапами retrieval и generation и повышает достоверность итогового результата.
Главное достоинство RAG заключается в том, что она позволяет получать ответы на основе конкретного корпуса документов без переобучения всей модели. Это особенно важно в тех случаях, когда база знаний часто меняется. Достаточно обновить документы и переиндексировать их, чтобы система начала учитывать новую информацию. В этом смысле RAG значительно гибче, чем fine-tuning.
Кроме того, такая архитектура делает ответы более проверяемыми. Поскольку контекст можно отследить, становится проще понять, на чём основан тот или иной вывод модели. Это особенно важно для корпоративных и технических систем, где пользователю нужно доверять не только форме, но и источнику ответа.
Однако у подхода есть и ограничения. Если retrieval возвращает нерелевантные фрагменты, генератор уже не сможет исправить ошибку. Если база документов плохо структурирована, качество поиска снизится. Если индексы устаревают, система начинает работать с неправильным контекстом. И, наконец, при росте объёма данных возрастает стоимость поиска и reranking, особенно если используются крупные модели.
Retrieval-Augmented Generation является одной из наиболее практически значимых архитектур в современной разработке NLP-систем. Она решает важную задачу: связывает генерацию текста с актуальными внешними источниками и делает ответы более точными, проверяемыми и полезными в прикладной работе. В реализованной схеме используются локальная обработка документов, разбиение текста на фрагменты, Qwen-эмбеддинги, FAISS, reranking и генеративная модель с контекстным prompt.
Показанная архитектура демонстрирует, что полноценную RAG-систему можно построить в компактном и прозрачном виде, не прибегая к сложной распределённой инфраструктуре. При этом качество конечного ответа зависит не только от выбора модели, но и от всей цепочки решений: как загружаются документы, как они режутся на chunks, как строится индекс, как отбираются кандидаты и как именно задаётся инструкция для генератора. Именно эта последовательность превращает набор отдельных моделей в рабочую интеллектуальную систему.
Список литературы
- LangChain. PyPDFLoader — загрузчик PDF-документов. [Электронный ресурс]. URL: https://reference.langchain.com/python/langchain-community/document_loaders/pdf/PyPDFLoader (дата обращения: 18.03.2026)
- Hugging Face. Qwen3-Embedding-0.6B — модель для эмбеддингов. [Электронный ресурс]. URL: https://huggingface.co/Qwen/Qwen3-Embedding-0.6B (дата обращения: 18.03.2026)
- FAISS. Facebook AI Similarity Search. [Электронный ресурс]. URL: https://faiss.ai/index.html (дата обращения: 18.03.2026)



