
Introduction
For decades, cloud operations have relied on a reactive posture: systems generate telemetry, dashboards visualize data, and human engineers respond to alerts. Even with the advent of Infrastructure as Code (IaC) and basic automation, the "intelligence" of the system remained external—locked within the cognitive capacity of SRE (Site Reliability Engineering) teams. As infrastructure becomes more ephemeral and global in scale, the "mean time to detect" (MTTD) and "mean time to resolution" (MTTR) are increasingly constrained by human latency.
Agentic Cloud Operations represent the next evolutionary step, moving beyond deterministic scripts toward autonomous entities that act as primary operators. These agents do not merely report that a database is lagging; they analyze the root cause, evaluate potential remediation strategies, and execute the necessary changes within defined guardrails. This shift necessitates a fundamental rethinking of the cloud management plane, transforming it from a collection of APIs into a collaborative environment where agents and humans interact through shared goals and intent-based interfaces.
The core of Agentic Cloud Operations lies in the departure from "If-This-Then-That" logic toward goal-oriented autonomy. In traditional monitoring, a CPU spike triggers a notification; in an agentic system, the spike triggers a reasoning loop where an agent queries logs, traces, and documentation to determine if the spike is an expected load increase, a memory leak, or a security breach. This "Reasoning-Action" cycle allows the infrastructure to adapt to novel situations that were not pre-programmed by developers. Central to this architecture is the integration of agents with the "Control Plane" of the cloud provider.
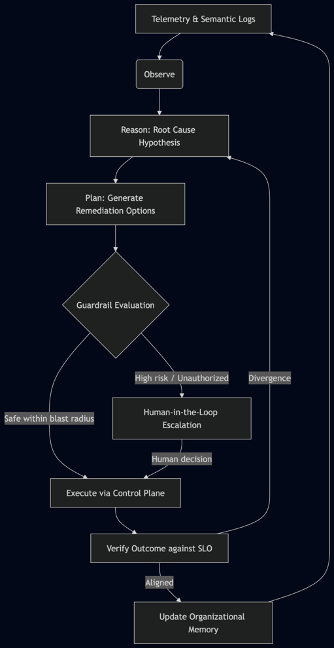
Figure 1. The Autonomous Reasoning-Action Loop
In practice, this cycle expands into a five-stage autonomous feedback loop: Observe, where agents ingest not just metrics but semantic telemetry from distributed traces and natural-language logs; Reason, where probabilistically the agent forms hypotheses about root causes using internal world models augmented by past incident runbooks; Plan, where it generates one or more remediation paths with estimated impact; Execute, but only after compliance with architectural guardrails that validate the blast radius and financial risk; and finally Verify, comparing the new state to the declared Service Level Objectives. Critically, when the outcome deviates from the objective, the agent does not simply retry the same action—it re-enters the reasoning phase with fresh context, avoiding the flapping loops that cripple scripted automations.
Moreover, each completed loop enriches the organizational memory—a vectorized knowledge base of incident post-mortems, runbooks, and engineer feedback—so that future observations trigger faster, more accurate reasoning. This transforms the operation set from a static reaction table into a living, self-improving system.
Field Observation 1 – Retrieval-Augmented Remediation in Streaming Services
In a large-scale AdTech platform running on Kubernetes, an autonomous agent detected an anomalous latency increase (99th percentile) in the video processing pipeline. Instead of simply scaling pods (the scripted response), the agent queried the vectorized post-mortem database and retrieved a similar incident from six months prior where the root cause was an exhausting connection pool in a sidecar. The agent immediately checked the sidecar’s connection graphs, confirmed the same saturation, and rolled out a live configuration patch that increased the pool size—circumventing a full restart that would have caused playback interruptions. Human engineers were notified only after the SLO recovered. This single closed-loop action reduced what would have been a 34-minute human MTTR to under two minutes of autonomous resolution, while simultaneously recording the new runbook association in the memory layer.
By utilizing tools like Kubernetes APIs, Terraform providers, and cloud SDKs, agents can perform complex sequences of actions such as rightsizing instances, rerouting traffic during localized outages, or implementing emergency security patches. The concept of "Golden Signals" in monitoring is thus replaced by "Autonomous Objectives," where the agent is tasked with maintaining a specific Service Level Objective (SLO) rather than just watching a metric. To manage the inherent risks of probabilistic execution, these systems employ "Architectural Guardrails" and "Human-in-the-Loop" (HITL) patterns for high-stakes decisions, ensuring that agents cannot perform destructive actions without verified authorization.
Architectural Foundations
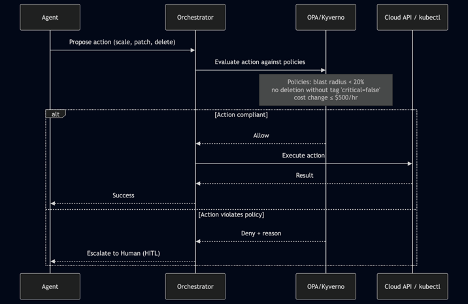
Figure 2. Policy-as-Code Guardrail Sequence
The safety of autonomous operations hinges on a Policy-as-Code Guardrail layer that acts before any execution. Using tools like Open Policy Agent (OPA) or Kyverno, operators codify immutable rules: maximum blast radius (e.g., no more than 10% of pods), forbidden destructive actions (deleting persistent volumes), and cost-delta ceilings. Every action plan proposed by the agent is evaluated by this lightweight engine synchronously. If the action passes, it flows to the cloud control plane; if it violates a policy, the agent is blocked and a pre‑defined escalation to a human on-call is triggered. Crucially, the agent receives the denial reason in natural language or structured format, allowing it to learn and adapt its future plans. This makes safety declarative and auditable, rather than buried in agent code.
Field Observation 2 – Guardrail Preventing Cascade Failure
During a memory leak incident, an agent proposed a rolling restart of 60% of nodes simultaneously to accelerate recovery. The guardrail policy (max concurrent restart ≤ 25%) denied the action, forcing the agent to adopt a phased approach. The platform avoided a capacity collapse that would have occurred with the original aggressive plan, demonstrating how explicit guardrails act as a safety net for probabilistic reasoning.
Digital Twin Sandbox for Pre‑execution Validation

Figure 3. Digital Twin Sandbox Validation Flow
Before releasing an autonomous decision into production, the agent can first validate it inside a Digital Twin Sandbox—an ephemeral, scaled-down replica of the live environment seeded with synthetic traffic and current configuration. The agent applies the planned change (e.g., adjusting autoscaling parameters, rotating certificates) and observes the simulated impact on latency, error budget, and resource cost. Only actions that maintain or improve the defined SLO in the sandbox are promoted to the production control plane. This pattern significantly reduces the risk of hallucinations or unforeseen side effects, especially for complex stateful workloads. The simulation traces also serve as an audit log, providing explainability for why the agent chose a particular action.
Field Observation 3 – Safe Certificate Rotation in FinTech
A Kubernetes operator agent was tasked with rotating TLS certificates for a payment gateway. Before touching production, it spun up a sandbox cluster from a snapshot, executed the rotation, and ran an automated test suite that simulated 10,000 transactions. The sandbox revealed a 0.5% failure rate due to an incorrect trust chain order—flawlessly avoided in production. This pre-validation, powered by a Digital Twin, saved hours of potential outage and compliance risk.
Federated Agent Mesh with Shared Context Bus
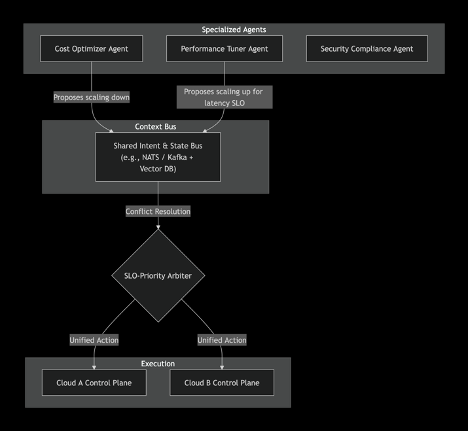
Figure 4. Federated Agent Mesh with Intent Bus
In multi‑cloud setups, a monolithic agent becomes a bottleneck. Instead, a Federated Agent Mesh employs specialized autonomous agents—cost optimizer, performance tuner, security enforcer—each operating within its own domain but communicating through a shared Intent & State Bus. The bus holds the current desired state, SLO hierarchy, and a conflict resolution arbiter. For instance, if the cost agent proposes downsizing a cluster while the performance agent requests an upsizing to meet a latency SLO, the arbiter resolves the conflict by favoring the SLO that carries the highest business priority. This prevents the chaos of agents fighting each other and ensures globally optimal decisions. The bus is typically implemented with a lightweight message broker (NATS) and a vector database for semantic memory, enabling agents to “understand” the context behind each other’s intents.
Field Observation 4 – Collaborative Right‑Sizing in E‑Commerce
In a holiday load test, a performance agent detected a 50% traffic surge and prepared to add 200 nodes. Simultaneously, the cost agent flagged an idle dev cluster that could be borrowed. Communicating via the context bus, the arbiter merged these intents: it temporarily reassigned the dev capacity first, then added only 50 new nodes, achieving the SLO at a 30% lower cost than either agent would have achieved alone.
Furthermore, the efficiency of agentic operations is amplified by their ability to manage "Unit Economics" in real-time.
An autonomous agent can continuously audit cloud spending, identifying orphaned resources and negotiating spot instance pricing with a speed and granularity impossible for human teams. This leads to a state of "Dynamic Optimization," where the infrastructure is constantly reshaping itself to find the most cost-effective and performant configuration. The data layer for these agents extends beyond metrics to include "Semantic Telemetry"—natural language logs and historical incident reports that provide context for decision-making. By leveraging Retrieval-Augmented Generation (RAG), agents can reference past post-mortems to solve current incidents, effectively creating an organizational memory that improves over time.
Semantic Telemetry and Runbook Memory
The effectiveness of Retrieval-Augmented Generation in agentic operations depends on the creation of a Runbook Vector Database—a continuously updated knowledge base that stores not just raw incident logs, but semantically meaningful chunks of past investigations, post-mortems, and engineer annotations. At incident time, the agent embeds the current telemetry summary (including error messages, spike patterns, and affected services) and queries this vector database. The retrieved records, weighted by semantic similarity, are injected into the agent’s prompt context, allowing it to reason by analogy with past resolutions.
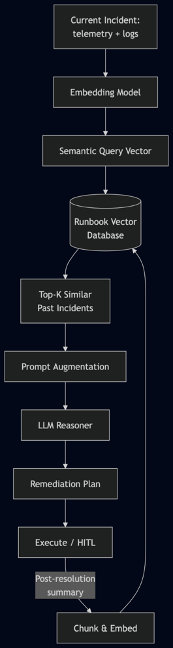
Figure 5. RAG Pipeline for Incident Resolution
This pipeline transforms incident handling from a linear search through documentation into a memory‑augmented reasoning process. The agent does not start from scratch; it stands on the shoulders of the entire organizational incident history. The retrieved incidents provide not only technical fixes but also context about past mistakes, side effects, and human review comments. When the new incident is resolved, its full timeline—observation, reasoning steps, action taken, and outcome—is automatically chunked, embedded, and written back into the database, closing the learning loop.
Crucially, the vector database also stores engineer corrections from the RLHF alignment cycle, creating a tight coupling between human expertise and agent memory. This ensures that the same class of problem is never solved twice.
Field Observation 7 – Runbook Retrieval Shortens Multi‑Signal Correlation
In a travel booking platform, an autonomous agent faced a simultaneous spike in checkout errors and database connection timeouts. It embedded the combined signal and retrieved a three-month-old incident where a misconfigured service mesh retry policy caused cascading connection exhaustion. Though the current symptoms appeared unrelated initially, the agent applied the retrieved remediation (rate-limiting retries client-side) and resolved the issue within 90 seconds. A human SRE later confirmed that the identical root cause had recurred, and praised the agent for recognizing the pattern faster than a human could have correlated the disparate alerts.
The transition also requires a shift in how engineers interact with systems; instead of writing code to manage servers, they write "Agent Manifestos" that define the boundaries, goals, and ethical constraints of the autonomous operators.
This elevates the role of the engineer from a tactical responder to a strategic orchestrator. However, the move to autonomous management also introduces challenges in "Observability of the Agent," necessitating new tools to monitor the reasoning process and decision-making logic of the AI itself.
Agent Observability and Continuous Alignment
Agent Observability Metrics and Dashboard
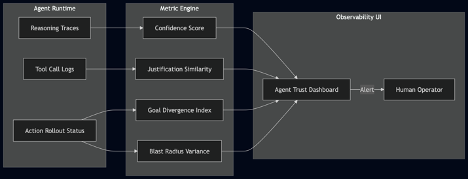
Figure 6. Agent Observability Architecture
Traditional monitoring answers “What is my infrastructure doing?”. Agentic operations require answering “What is my agent thinking, and am I safe?”. This demands an Agent Observability Dashboard fueled by new, psychologically inspired metrics:
- Agent Confidence Score: The model’s self-assessed probability that its root-cause hypothesis is correct. A drop below a configurable threshold (e.g., 0.7) pauses autonomous execution and flags the incident for human review.
- Goal Divergence Index: A running measurement of how far the agent’s recent actions deviate from the declared SLO targets. A sharp rise indicates potential misalignment or hallucination.
- Justification Similarity: For each action, the agent embeds its natural-language justification and compares it to known safe justifications in the vector database. Low similarity triggers scrutiny.
- Blast Radius Variance: The difference between the predicted blast radius (from the plan step) and the actual observed impact. Persistent positive variance suggests the agent’s world model is stale.
These metrics are not theoretical; they form a safety net that allows the organization to gradually increase agent autonomy. When any metric crosses a threshold, the system can automatically move from fully autonomous to advisory mode, alerting human engineers with a complete reasoning trace.
RLHF Alignment Loop (Continuous Learning from Human Feedback)
Observability alone is insufficient; it must close the loop with Reinforcement Learning from Human Feedback (RLHF) tailored for cloud operations.
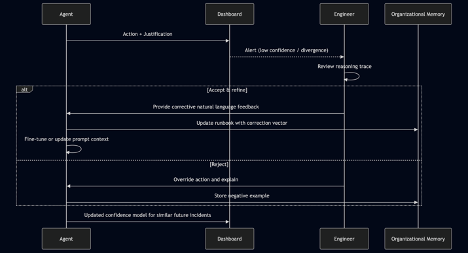
Figure 7. Human-in-the-Loop Alignment Cycle
When an agent’s action triggers a human review—because of low confidence or a novel incident pattern—the engineer examines not just the action but the entire reasoning trace. They then provide natural-language feedback: “Your root cause was correct, but the remediation should have drained the node before termination to preserve running sessions. Update your runbook.”
The agent processes this feedback by storing the corrected sequence as a new vector embedding in the organizational memory. Future similar incidents retrieve the improved runbook, effectively allowing the system to learn from each human override. This process mirrors how SRE teams train junior engineers, but it occurs at machine speed and scale. Over multiple cycles, agents develop an increasingly reliable intuition for the specific infrastructure they manage, reducing the need for human intervention while enhancing safety.
Field Observation 5 – Drift Detection Saves a Database Failover
In a managed database service, the performance agent began repeatedly restarting a replica due to a misinterpreted “slow query” pattern. The Goal Divergence Index spiked within three cycles, automatically pausing the agent and alerting the human SRE. The SRE corrected the agent’s runbook with a note that “slow queries during backup window are normal.” The agent never repeated the error, and the average monthly divergence index dropped by 40% thereafter.
Field Observation 6 – Justification Similarity Catches Hallucinated Remediation
A security agent proposed blocking an entire /16 address range in response to a minor DDoS. Its justification embedding had a similarity score of 0.2 against the corpus of safe security runbooks (typical safe actions score >0.8). The system automatically rejected the action and escalated. Human review confirmed the agent had misclassified traffic shape; the corrected action blocked only the offending /28. This near-miss was recorded and used to retrain the similarity threshold.
Ensuring that agents remain aligned with business intent and do not enter "hallucinatory" states where they misinterpret system health is the primary frontier of current research in this field. Ultimately, the convergence of high-fidelity telemetry and autonomous reasoning enables the creation of "Living Infrastructure" that matures, heals, and scales with minimal human friction.
Conclusion
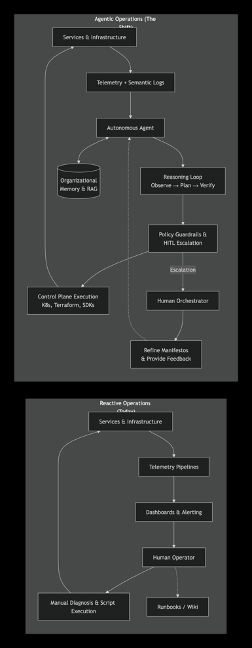
Figure 8. From Reactive Monitoring to Autonomous Agentic Operations
The figure places the two operational models next to each other:
- Left block (Reactive Operations): A human‑bounded vertical loop. Infrastructure metrics flow upward into telemetry pipelines, then into dashboards and alerts. A human operator must manually diagnose each issue, consult static runbooks, and execute scripts, before the loop repeats. The cognitive load and latency reside entirely with the human.
- Right block (Agentic Operations): A closed‑loop, memory‑augmented autonomous system. The same infrastructure data now flows into the autonomous agent, which performs its own reasoning cycle (Observe → Plan → Verify). Pre‑execution guardrails keep actions safe, and only exceptions escalate to a human orchestrator—who now works on refining high‑level manifestos and providing feedback that continuously improves the agent. The agent constantly reads from and writes to an organisational memory (RAG), transforming every resolved incident into a future advantage.
This side‑by‑side view crystallises the paper’s central argument: the journey from static dashboards and human fatigue to self‑healing, cost‑optimised, and resilient infrastructure under autonomous stewardship.
The shift from reactive monitoring to Agentic Cloud Operations is not merely a technical upgrade but a fundamental change in the philosophy of systems management. By empowering autonomous agents to take the lead in infrastructure orchestration, organizations can overcome the limitations of human scale and cognitive load. While the transition requires significant investments in governance, security, and agent-native architecture, the rewards are found in unprecedented levels of system resilience and operational efficiency.
As AI agents become more sophisticated, the boundary between the application and the infrastructure will continue to blur, leading to a future where software is truly self-sustaining. The age of the dashboard as the primary interface of operations is ending; the age of the autonomous agent, acting as a tireless and intelligent steward of the digital world, has begun.
Список литературы
- Radjabov, R. (2026). Agent-First Architectures: Patterns for AI-Native Software Design
- Beyer, B., Jones, C., Petoff, J., & Murphy, N. R. (2016). Site Reliability Engineering: How Google Runs Production Systems. O'Reilly Media
- Limerick, P., & Zhang, Y. (2024). Autonomous Cloud: The Integration of Large Language Models into DevOps Pipelines. Journal of Cloud Engineering
- Gartner. (2025). Market Guide for AI-Augmented Infrastructure Operations
- Wang, X., et al. (2023). A Survey on LLM-based Agents for Software Engineering and Cloud Operations. arXiv preprint
- FinOps Foundation. (2025). Autonomous Cloud Financial Management: The Role of Agents in Unit Economics
- Bernstein, D. (2023). Containers and Microservices: The Path to Autonomous Orchestration. IEEE Cloud Computing
- NIST. (2024). Draft Guidelines for Autonomous System Safety in Critical Cloud Infrastructure



