
ВВЕДЕНИЕ
Многомерные базы данных, реализующие парадигму MOLAP (Multidimensional Online Analytical Processing), представляют собой специализированные аналитические платформы, предназначенные для высокопроизводительного хранения и обработки структурированной информации в формате многомерных кубов. Ключевой задачей подобных систем выступает существенное повышение скорости, удобства и глубины анализа данных за счёт предварительной агрегации показателей. Данные в MOLAP организованы в виде многомерных структур, в которых измерения соответствуют атрибутам анализируемых процессов (временные периоды, товарные позиции, географические регионы и т.п.), а факты отражают количественные метрики – например, выручку, прибыль или объём продаж. Технология находит применение в широком спектре прикладных областей, предполагающих работу с крупными наборами данных и сложными иерархическими агрегатами, включая финансовый анализ, маркетинговые исследования, управление цепочками поставок и складскими запасами [5].
Очевидно, что процессы бизнес-аналитики далеко не всегда описываются строгими числовыми критериями. Нередко аналитик оперирует качественными, размытыми категориями, которые невозможно адекватно представить в виде классических чётких множеств, но которые естественным образом выражаются с помощью лингвистических переменных, таких как «высокая доходность», «низкий объём продаж», «средний уровень запасов» и т.п. При этом конкретные очертания нечётких множеств, интерпретирующих указанные лингвистические термы, будут варьироваться в зависимости от особенностей конкретного бизнес-процесса и отраслевой специфики предприятия. Таким образом, возникает объективная потребность в интеграции механизмов нечёткой логики непосредственно в среду многомерного анализа. В настоящей статье описывается создание комплексного программного продукта, предоставляющего возможность выполнять нечёткие запросы к многомерным кубам данных, что позволяет учесть субъективные и нестрогие требования конечных пользователей.
ОСНОВНАЯ ЧАСТЬ
Методология и используемые технологии
Теоретическим фундаментом работы служит аппарат нечётких множеств и лингвистических переменных, впервые систематически изложенный в трудах Л. Заде. При построении модели предполагается, что лингвистическая переменная задаётся в виде кортежа ⟨a, X, A⟩, где компонент a интерпретируется как имя переменной, X – универсальное множество (область определения), а A представляет собой нечёткое множество на X, характеризующее допустимые значения переменной. Другими словами, смысл лингвистической переменной полностью раскрывается через связанное с ней нечёткое множество, задаваемое соответствующей функцией принадлежности μ(x): X → [0,1].
Для формализации качественных суждений типа «значение близко к…», «находится в интервале…», «приблизительно равно…» на практике широко используются типовые параметрические функции принадлежности, в первую очередь – треугольная и трапециевидная формы, обладающие простой аналитической записью и наглядной геометрической интерпретацией (Рис. 1).
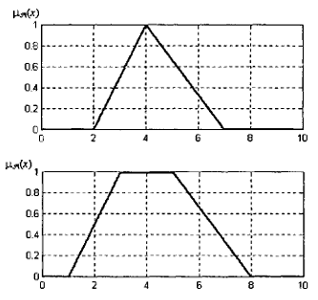
Рис. 1. Графическая интерпретация треугольного и трапециевидного нечётких множеств
Трапециевидная функция принадлежности в общем виде может быть представлена следующим аналитическим выражением (1):
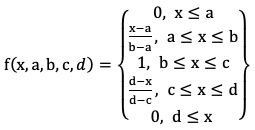 (1)
(1)
Выбор именно этого класса функций обоснован их способностью гибко описывать интервальные оценки с нечёткими границами, что в полной мере отвечает потребностям бизнес-аналитики, где экспертные суждения часто носят интервальный характер («от 400 до 600» является эталонным диапазоном). Более сложные формы (гауссовские, сигмоидальные) могут быть добавлены в систему в дальнейшем без принципиальных изменений архитектуры.
Разработка комплексного программного обеспечения, нацеленного на выполнение нечётких запросов к многомерным данным, декомпозируется на ряд взаимосвязанных подзадач:
- построение реляционного хранилища данных (DWH), выступающего источником информации для многомерного куба;
- реализация ETL-процесса загрузки и трансформации первичных сведений;
- создание серверного модуля, ответственного за персистенцию описаний нечётких лингвистических переменных, вычисление степеней принадлежности для извлекаемых из куба фактов и фильтрацию результирующих наборов;
- разработка многомерного куба в среде выбранной аналитической платформы;
- построение клиентского веб-интерфейса, позволяющего аналитику в интерактивном режиме конструировать нечёткие запросы и визуализировать их результаты.
2. Разработка многомерного хранилища и его источника информации
Структура реляционного хранилища данных, питающего MOLAP-куб, спроектирована в соответствии с методологией «Звезда», которая является классическим подходом к построению DWH для аналитических задач. Данная схема предполагает наличие центральной таблицы фактов, содержащей числовые показатели (меры) и внешние ключи, связывающие её с таблицами измерений. Каждая строка таблицы фактов отражает отдельный учётный факт – например, сумму выручки по конкретной товарной позиции в составе заказа. Таблицы измерений, в свою очередь, детализируют атрибутивный состав: информация о товарах, датах, параметрах заказов и т.д.
Для моделирования предметной области продаж торгового предприятия, рассматриваемого в рамках данного исследования, была реализована реляционная схема, приведённая на (Рис. 2). Регламентное пополнение хранилища актуальными сведениями из транзакционной учётной системы осуществляется посредством специализированного задания, реализованного на языке C#, что обеспечивает контролируемую периодичность и целостность загрузки.
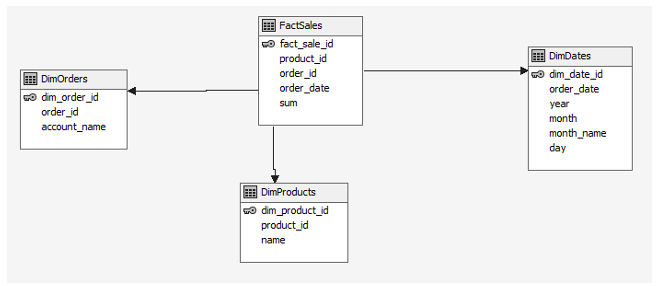
Рис. 2. Структура таблиц в хранилище данных
Спроектированный на основе данного хранилища многомерный куб продаж включает три измерения: «Дата», «Заказ» и «Продукт» (Рис. 3), а также две меры (Рис. 4). При этом измерение «Дата» обогащено пользовательской иерархией «Год – Месяц – День», что является стандартной практикой для удобной навигации и быстрого переключения между уровнями детализации.
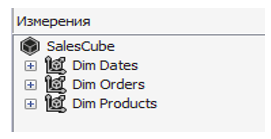
Рис. 3. Измерения куба продаж
Рис. 4. Меры куба продаж
Такой состав измерений и мер даёт возможность анализировать продажи в различных аналитических разрезах, а наличие временной иерархии критически важно для интерпретации нечётких запросов, ориентированных на периоды (например, «среднемесячное количество продаж»).
3. Разработка модуля хранения нечетких лингвистических переменных и применения нечетких запросов
Хранение описаний нечётких лингвистических переменных, определяемых пользователями через клиентское приложение, организуется на основе рассмотренной выше модели ⟨a, X, A⟩. Чтобы вычислить степень принадлежности конкретного значения меры тому или иному нечёткому множеству [4], серверному модулю необходимы следующие данные: наименование переменной, минимальное пороговое значение степени принадлежности (используемое при фильтрации), идентификатор аналитического разреза куба, для которого переменная была создана, наименование целевой меры, а также массив координат точек, описывающих форму функции принадлежности. Таким образом, структура базы данных для хранения нечётких термов включает две связанные таблицы (Рис. 5): первая содержит метаинформацию о переменной, а вторая — геометрические примитивы, конфигурирующие конкретную функцию принадлежности. Принципиально важно отметить, что аналитическое выражение функции в таблицах не сохраняется — достаточно зафиксировать её тип (например, трапециевидная), а непосредственное вычисление значений μ(x) осуществляется на серверной стороне в момент обработки запроса, что обеспечивает гибкость при возможной модернизации набора поддерживаемых функций.
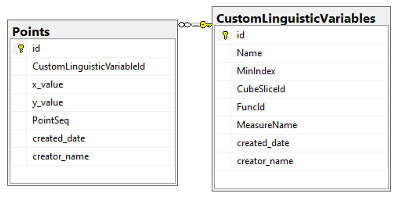
Рис. 5. Структура хранилища нечетких лингвистических переменных
Применение нечёткой логики к многомерным структурам данных наталкивается на известные ограничения языка MDX, традиционно служащего для извлечения сведений из MOLAP-кубов [1]. Синтаксис и семантика MDX ориентированы, главным образом, на навигацию по иерархиям, получение предварительно агрегированных значений и выполнение типовых операций над множествами элементов измерений, но не предполагают встроенных средств для оперирования нечёткими критериями. В качестве эффективного способа преодоления данного барьера предложена трёхзвенная архитектура «MOLAP – сервер приложений – клиент». В рамках такого подхода серверный компонент извлекает из куба с помощью MDX-запроса исходный набор данных в выбранном разрезе, после чего в оперативной памяти построчно вычисляет степени принадлежности для каждой записи на основании конфигурации нечёткой переменной и осуществляет фильтрацию в соответствии с заданным порогом. Клиент получает уже очищенный и верифицированный результат. Вычислительные эксперименты показывают, что при использовании построчной потоковой обработки (с возможностью распараллеливания операций над независимыми строками) скорость выполнения нечёткого запроса остаётся сопоставимой с быстродействием нативных многомерных запросов.
В технологическом стеке .NET построчная обработка данных, получаемых от источника, часто организуется с применением объекта, реализующего интерфейс IDataReader.
4. Клиентский веб-модуль для формирования нечётких запросов
Выбор технологии реализации интерфейса определялся требованиями крупных торговых предприятий к информационной безопасности, простоте развёртывания, регулярной доставке обновлений и гибкой кастомизации. Исходя из этого, интерфейс был реализован в виде защищённого веб-ресурса с аутентификацией и авторизацией на основе cookie.
После авторизации аналитик получает доступ к визуализации одного из разрезов куба продаж, где агрегированные показатели количества продаж и выручки отображаются помесячно (Рис. 6).
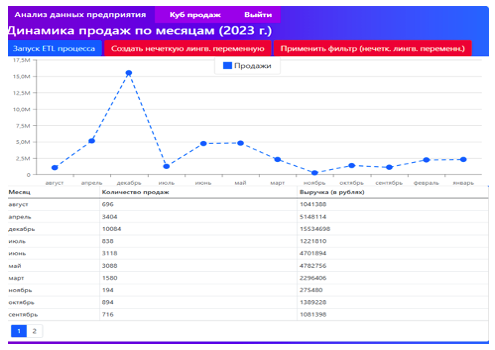
Рис. 6. Интерактивное отображение агрегированных показателей продаж, извлечённых из многомерного куба, в клиентском веб-приложении
В верхней части интерфейса расположены элементы управления, позволяющие конструировать нечёткие запросы. Для запроса вида «ВЫВОД [Месяцев 2023 года] ГДЕ [Количество продаж] = Среднее» достаточно задать одиночную нечёткую лингвистическую переменную с трапециевидной функцией принадлежности (Рис. 7).
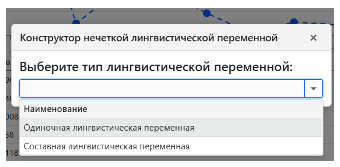
Рис. 7. Определение конфигурации нечёткой лингвистической переменной
Например, аналитик может считать, что среднее количество продаж за месяц характеризуется следующими порогами: 300 ед. — не среднее (0%), интервал 400–600 — эталонное среднее (100%), 800 ед. — не среднее (0%). Настроенная функция и её параметры представлены на (Рис. 8).
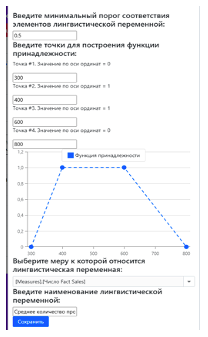
Рис. 8. Конфигурация и числовые характеристики нечёткого терма «Среднее количество»
Далее переменная выбирается в диалоге «Применить фильтр по нечётким лингвистическим переменным», и результатом выполнения нечёткого запроса становится строка многомерной выборки (Рис. 9).
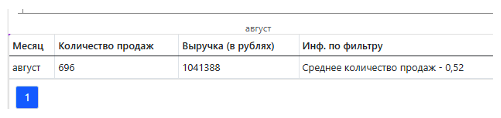
Рис. 9. Результат выполнения нечеткого запроса
ЗАКЛЮЧЕНИЕ
Проведённое исследование подтверждает, что MOLAP-системы служат высокоэффективным инструментом многомерного анализа, обеспечивающим быструю обработку и многоракурсную интерпретацию значительных информационных массивов. Их кубическая архитектура естественным образом поддерживает рассмотрение данных в различных срезах, что востребовано в большинстве функциональных областей коммерческой организации. Вместе с тем процессы бизнес-анализа зачастую сопряжены с нечёткими, качественно сформулированными требованиями, которые не поддаются адекватному выражению в терминах точных числовых диапазонов. В этих условиях обращение к аппарату лингвистических переменных становится не просто уместным, но и необходимым для адекватного отражения реалий, характеризующихся неопределённостью, субъективными экспертными суждениями и размытостью границ экономических понятий.
Список литературы
- Федоров, Алексей; Елманова, Наталья Введение в OLAP-технологии Microsoft; М.: Диалог-МИФИ - Москва, 2011. - 268 c.
- Lam, H. & Chung, Sai-Ho & Lee, C. & Ho, G.T.s & Yip, T.K.T. (2009). Development of an OLAP Based Fuzzy Logic System for Supporting Put Away Decision. International Journal of Engineering Business Management. 1. 1. 10.5772/6779
- Veryha, Yauheni. (2002). Implementation of Fuzzy Classification Query Language in Relational Databases Using Stored Procedures. 195-202
- Лисицына Л.С., Основы теории нечетких множеств– СПб: Университет ИТМО, 2020. – 74 с.
- Эргашев Аслон Акрамович, Садикова Фируза Сафаровна СПОСОБЫ И МЕТОДЫ АНАЛИЗА МНОГОМЕРНОГО БАЗЫ ДАННЫХ // Universum: технические науки. 2021. № 12-1 (93). URL: https://cyberleninka.ru/article/n/sposoby-i-metody-analiza-mnogomernogo-bazy-dannyh
- Броневич А. Г., Лепский А. Е. Нечеткие модели анализа данных и принятия решений: учебное пособие. — М.: Издательский дом Высшей школы экономики, 2022. — 266 с.



