
1. Introduction
The increasing demand for high-performance storage in data-intensive applications has accelerated the adoption of SSDs. However, traditional SSD architectures suffer from inherent inefficiencies, particularly write amplification caused by internal garbage collection and wear leveling. NVMe ZNS SSDs introduce a paradigm shift by allowing host software to manage data placement in sequentially written zones. This reduces the need for internal data movement and enables more predictable performance. Nevertheless, the effectiveness of ZNS devices depends heavily on the host’s zone management policies.
This study investigates how different policies affect write amplification and overall system efficiency using ConfZNS, a configurable simulation and evaluation framework for ZNS-based storage systems.
2. Background
2.1 Write Amplification
Write amplification (WA) refers to the ratio of physical writes performed on flash memory to the logical writes issued by the host. High WA leads to reduced device lifespan and degraded performance.
2.2 NVMe Zoned Namespace (ZNS)
ZNS SSDs divide storage into zones that must be written sequentially. Once a zone is filled, it must be reset before reuse. This design shifts responsibility for data placement and garbage collection from the device to the host.
2.3 Zone Management PoliciesZone management policies determine how data is written, grouped, and reclaimed. Common approaches include:
- Greedy allocation
- Lifetime-based grouping
- Hot/cold data separation
- Log-structured strategies
3. Experimental workflow
To evaluate the influence of zone-management policy on write amplification in NVMe Zoned Namespace (ZNS) SSDs, a configurable Python-based simulator was implemented. The simulator models a namespace partitioned into zones, sequential append-only writes within zones, logical-to-physical mapping, invalidation of overwritten blocks, and garbage collection through victim-zone reclamation. This modeling approach reflects the host-managed nature of ZNS SSDs, in which software-visible data-placement decisions substantially affect device behavior.
The experimental workflow consists of five stages. First, the simulator is initialized using a fixed namespace configuration, including the number of zones, zone capacity, garbage-collection threshold, and policy-dependent parameters such as the hotness threshold and lifetime window. A fixed random seed is used in each experiment to ensure reproducibility.
Second, a synthetic workload is generated. Three workload families are supported: uniform random traffic, skewed Zipfian traffic, and mixed read/write traffic. These workload classes correspond to the main workload types considered in the study: uniform random writes, skewed distributions, and mixed workloads.
Third, each I/O request is processed according to one of four evaluated zone-management policies: Baseline Sequential Allocation (BSA), Hot/Cold Separation (HCS), Lifetime-Aware Allocation (LAA), and Hybrid Adaptive Policy (HAP). For write operations, the simulator classifies the incoming logical block according to the active policy and appends it to a selected zone. If the logical block address has been written previously, the prior physical instance is invalidated. Read operations are counted but do not contribute directly to write amplification.
Fourth, when the amount of available space falls below the configured threshold, garbage collection is invoked. The simulator selects a victim zone, relocates valid blocks, resets the victim zone, and returns it to the reusable pool. To avoid relocation deadlock, one empty zone is reserved as spare relocation space. This mechanism enables controlled observation of the interaction between placement policy and cleaning pressure.
Fifth, the simulator records a set of comparative metrics for each run. These include Write Amplification Factor (WAF), garbage-collection overhead ratio, number of moved blocks, zone-reset count, host invalidations, policy-overhead operations, and a throughput-like score based on useful work relative to relocation and classification cost. These metrics match the evaluation goals of the study, which focus on WAF, throughput, zone-reset frequency, and garbage-collection overhead.
Individual policy runs were used to generate standalone charts and JSON summaries, while batch execution was used to generate scenario-level comparative figures and an overall summary across workloads.
3.1 ConfZNS Framework
ConfZNS provides a flexible environment for simulating ZNS SSD behavior under varying workloads and policies. It supports configurable parameters such as zone size, workload distribution, and garbage collection thresholds.
3.2 Evaluated Policies
Four zone-management strategies were evaluated.
BSA serves as the baseline policy. Data are written sequentially without further classification or grouping.
HCS separates frequently updated data from colder data. The objective is to reduce relocation cost by limiting the coexistence of highly volatile and relatively stable blocks in the same zones.
LAA groups data according to estimated update lifetime. Recently rewritten data are treated as shorter-lived, whereas less frequently updated data are assumed to persist longer.
HAP combines hot/cold separation and lifetime-aware grouping. Its purpose is to adapt more effectively to workload diversity, particularly when no single heuristic is sufficient.
4. Experiments and Results
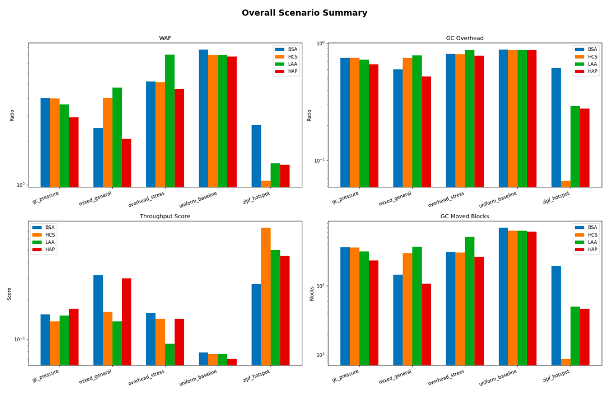
The experimental results show that write amplification in ZNS systems is highly sensitive to the interaction between workload characteristics and zone-management policy. In general, policies that incorporate workload awareness outperform naive sequential placement, although the relative ranking of policies varies across workloads.
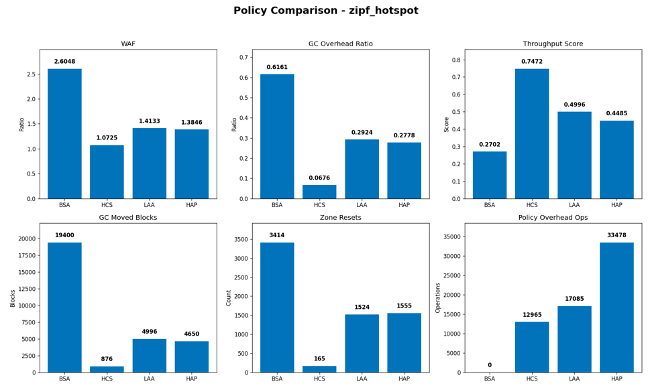
In the zipf_hotspot scenario, which represents strongly skewed access with a concentrated hot set, HCS achieved the lowest WAF at approximately 1.07, while BSA reached approximately 2.60. LAA and HAP also improved on the baseline, with WAF values of approximately 1.41 and 1.38, respectively. These results indicate that explicit hot/cold grouping is particularly effective under strong access locality, where separating highly volatile data from more stable data reduces unnecessary relocation during garbage collection.
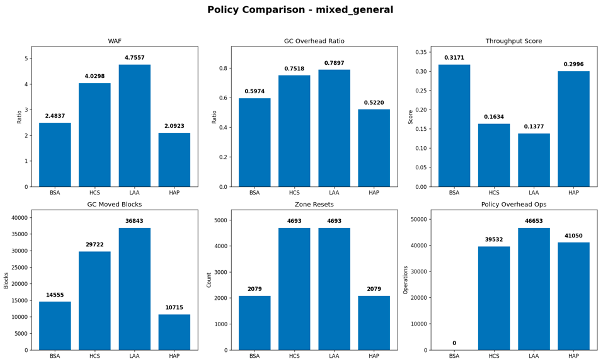
In the mixed_general scenario, HAP achieved the best result, with a WAF of approximately 2.09, outperforming BSA at 2.48, HCS at 4.03, and LAA at 4.76. A similar pattern is reflected in garbage-collection overhead and moved-block count, where HAP also produced lower values than the other policies. This suggests that under mixed access behavior, a hybrid classification strategy can respond more effectively to workload variation than single-purpose heuristics.
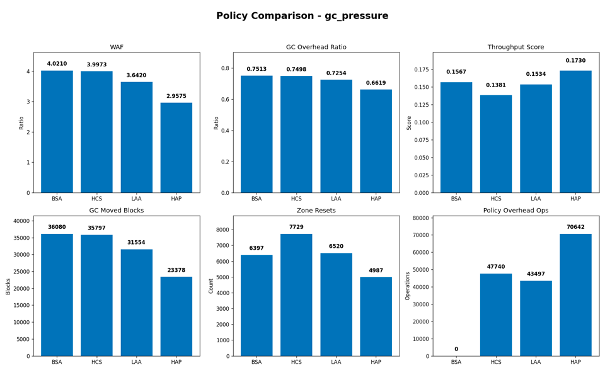
Under gc_pressure, where namespace capacity is tighter and write pressure is higher, HAP again produced the lowest WAF at approximately 2.96. By comparison, LAA reached 3.64, while HCS and BSA both remained near 4.00. This result indicates that the hybrid policy is more resilient when reclamation pressure is elevated and placement decisions directly affect cleaning frequency.
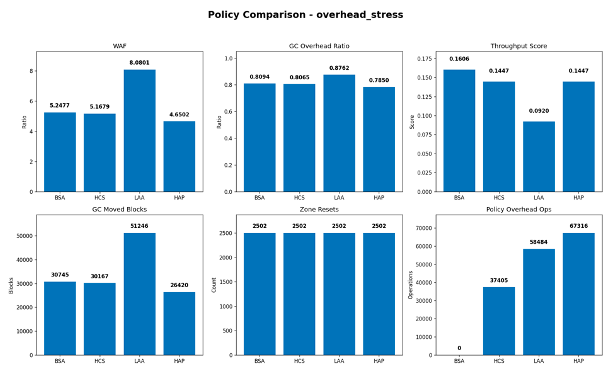
The overhead_stress scenario highlights the trade-off between placement intelligence and policy cost. In this case, HAP achieved the lowest WAF at approximately 4.65, followed by HCS at 5.17, BSA at 5.25, and LAA at 8.08. This result demonstrates that added policy complexity does not automatically yield better behavior. If the classification strategy is not well aligned with workload dynamics, metadata tracking and misgrouping may offset the intended benefits.
In the uniform_baseline scenario, the gap between policies is narrower than in hotspot-dominated or mixed workloads. HAP still achieved the lowest WAF, approximately 7.82, followed by LAA at 8.00, HCS at 8.01, and BSA at 8.75. This indicates that the advantage of workload-aware policies becomes more pronounced when workload structure is more distinctive, whereas under relatively uniform pressure the improvement margin is smaller.
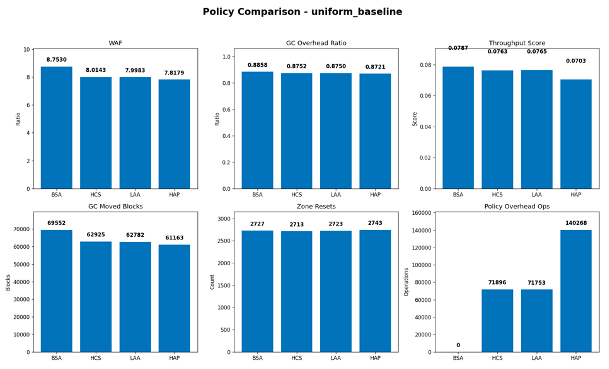
Overall, three observations can be made. First, workload-aware placement policies reduce write amplification relative to the sequential baseline. Second, different workloads favor different strategies: HCS performs best under hotspot-heavy skew, while HAP performs best in several mixed and pressure-intensive scenarios. Third, no single policy is universally optimal; rather, the most effective strategy depends on workload structure, reclamation pressure, and the cost of policy-specific classification.
4.1 Interpretation of Results
The results indicate that HAP provides the most balanced behavior across the evaluated scenarios. It achieves the best WAF in several cases, including mixed traffic, garbage-collection pressure, and overhead-sensitive stress. HCS, however, is particularly effective in skewed hotspot-heavy workloads, where explicit hot/cold separation yields the strongest reduction in write amplification. LAA does not show a consistent advantage in the present implementation and underperforms HAP in mixed and pressure-intensive scenarios.
These findings suggest that intelligent placement and grouping policies can substantially reduce write amplification, but their effectiveness depends on workload structure and on the balance between classification overhead and reclamation efficiency. In this respect, the results reinforce the broader conclusion that adaptive approaches are generally preferable to naive sequential allocation, although hotspot-oriented separation remains especially strong under skewed access patterns.
Reproducibility
To ensure reproducibility, each scenario was executed using a fixed random seed and an identical namespace configuration across all four policies. Results were exported in JSON and CSV formats, and figures were generated automatically for both per-scenario and overall comparison. This workflow enables straightforward repetition of experiments, controlled parameter modification, and direct comparison of WAF, garbage-collection overhead, and throughput-like score across policy variants.
The reproducible workflow consists of scenario definition, per-policy execution, metric collection, per-scenario visualization, and final aggregation into an overall summary plot. This structure supports systematic comparison across multiple workloads and policy variants.
The simulator implementation, experiment runner, configuration presets, and generated figures are available in the accompanying GitHub repository. The repository includes the core simulator, batch experiment scripts, scenario definitions, and instructions for reproducing the reported results.
5. Discussion
Our analysis demonstrates that no single policy is universally optimal. Instead, adaptive approaches that respond to workload dynamics provide the best results. The use of ConfZNS enables reproducible experimentation and highlights the importance of system-level optimization in ZNS environments.
Furthermore, reducing write amplification not only improves endurance but also enhances predictability—an essential requirement for modern data centers and cloud infrastructures.
6. Conclusion
This paper presented a comparative study of zone management policies in NVMe ZNS SSDs using the ConfZNS framework. The results show that intelligent, adaptive strategies can significantly reduce write amplification while maintaining high performance.
Future work includes integrating machine learning techniques for real-time workload classification and extending ConfZNS to support multi-tenant storage environments.
Список литературы
- GitHub. URL: https://github.com/Velocifero1052/WriteAmplificationCourseWork
- Bjørling, M., et al. “Zoned Namespaces: A New Way to Scale Flash Storage
- NVMe Specification 1.4, NVM Express, Inc
- Gupta, A., et al. “Write Amplification in Flash SSDs: Analysis and Mitigation Techniques



