
Открытые большие языковые модели (LLM) позволяют специализировать их под конкретную предметную область путём дообучения на небольшом корпусе данных – без полного обучения с нуля. Однако дообучение моделей масштаба 3-7 миллиарда параметров долгое время требовало серверной инфраструктуры. Метод QLoRA сделал этот процесс доступным на потребительском оборудовании. Цель статьи – описать алгоритм: от формирования датасета до интерактивного использования дообученной модели локально, в условиях типичной рабочей станции под управлением Windows.
При полном дообучении необходимо хранить веса модели, градиенты и состояния оптимизатора, что суммарно требует до 8-12× объём самих весов. Для модели 3B в формате float32 это составляет порядка 96 ГБ. Метод LoRA «замораживает» исходные веса W и вводит пару низкоранговых адаптерных матриц A ∈ ℝ^(r×k) и B ∈ ℝ^(d×r), где r ≪ min(d, k). Обновлённая матрица в прямом проходе:
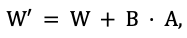 (1)
(1)
При ранге r = 16 число обучаемых параметров сокращается примерно до 0.8% от общего числа. Метод QLoRA дополняет LoRA квантизацией замороженных весов базовой модели до формата NF4. Это снижает объём памяти под базовую модель в ~8 раз. Вычисления выполняются в bfloat16 через динамическую деквантизацию. В совокупности дообучение модели 3B требует лишь ~3.5–4 ГБ VRAM. Реализованный алгоритм включает четыре последовательных этапа:
1. Подготовка датасета
Для supervised fine-tuning используется формат Alpaca: каждый пример – JSON-объект с полями instruction, input (опционально) и output. Датасет хранится в формате JSONL. Перед передачей в тренер каждый пример форматируется по шаблону, представленному на рисунке 1.

Рисунок 1. Шаблон примера датасета
Минимально необходимый объём датасета 60-100 примеров. При задачах точного запоминания фактического материала рекомендуется создавать несколько примеров с разными формулировками вопроса к одному и тому же ответу.
2. Дообучение
Базовая модель загружается в 4-битном формате через BitsAndBytesConfig с параметрами load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16. Параметр low_cpu_mem_usage=True снижает пиковое потребление оперативной памяти с ~14 ГБ до ~5 ГБ за счёт последовательной (слой за слоем) загрузки весов. К замороженной модели добавляются LoRA-адаптеры через get_peft_model с рангом r = 16 на целевые проекции механизма внимания и MLP-блоков. Обучение выполняется через SFTTrainer из библиотеки TRL. Среди значимых гиперпараметров: оптимизатор adamw_8bit снижает расход VRAM под состояния оптимизатора вдвое; gradient_checkpointing перевычисляет активации при обратном проходе вместо их хранения.
3. Конвертация в GGUF
Перед конвертацией адаптеры объединяются с базовой моделью через merge_and_unload: для каждой целевой матрицы вычисляется W' = W + B·A, после чего адаптеры удаляются. Объединённая модель сохраняется в формате HuggingFace. Конвертацию в GGUF выполняет скрипт convert_hf_to_gguf.py из репозитория llama.cpp. Первичный вывод производится в формат f16, результирующий файл занимает около 6 ГБ. Дополнительная квантизация до формата Q4_K_M снижает размер до ~2 ГБ при минимальной потере качества.
4. Размещение в Ollama
Ollama управляет моделями через конфигурационный файл Modelfile, в котором указываются ссылка на GGUF-файл, параметры генерации (температура, top_p, top_k, repeat_penalty, длина контекста) и шаблон форматирования диалога. Для моделей Qwen2.5 используется шаблон ChatML. Регистрация выполняется командой ollama create <имя> -f Modelfile --quantize q4_K_M, после чего модель доступна через CLI и HTTP API.
При реализации конвейера под Windows выявлено пять несовместимостей.
Unsloth и компилятор triton. Библиотека Unsloth при инициализации обращается к компилятору triton, не поддерживаемому на Windows с PyTorch 2.6. Поскольку обращение происходит на уровне импорта, отключить его конфигурационными параметрами невозможно. Решение – замена Unsloth базовым стеком библиотек HuggingFace.
Механизм динамической компиляции torch.compile. JIT-компилятор вычислительных графов, введённый в PyTorch 2.0, также использует triton в качестве backend и недоступен на Windows. Проблема устраняется превентивным отключением компилятора через переменные окружения до загрузки библиотеки.
Отсутствие поддержки bitsandbytes на Windows. Библиотека bitsandbytes, обеспечивающая 4-битную квантизацию и 8-битный оптимизатор, официально поддерживает только Linux. Решением служит установка неофициальной сборки, поддерживаемой сообществом и содержащей бинарные файлы для Windows.
Нарушение обратной совместимости API в TRL 0.24.0. Версия 0.24.0 содержит ряд несовместимых изменений интерфейса: ключевые параметры переименованы, часть из них перенесена в отдельный конфигурационный класс. Использование устаревших сигнатур, которые фигурируют в большинстве актуальных руководств, приводит к ошибкам на старте обучения.
Несовместимость формата конфигурации токенизатора при конвертации в GGUF. Модели Qwen2.5 хранят список специальных токенов в виде массива строк, тогда как скрипт конвертации ожидает словарь. Несоответствие проявляется в виде ошибки атрибута и устраняется нормализацией файла конфигурации перед запуском конвертации.
5. Результаты
Конвейер верифицирован на конфигурации: Windows 10, NVIDIA RTX 2070 (8 ГБ VRAM), 16 ГБ RAM, Python 3.12, PyTorch 2.6, CUDA 12.4. Базовая модель Qwen/Qwen2.5-3B-Instruct, датасет 66 примеров предметной области. Обучение 20 эпох заняло ~1400 с, финальный loss 0.21, пиковое потребление VRAM 6.8 ГБ. Результирующий GGUF-файл 6178 МБ (f16), после квантизации Q4_K_M ~2 ГБ. Дообученная модель успешно воспроизводит специфические факты из обучающего датасета.
Список литературы
- Тихомиров М., Чернышев Д. Содействие адаптации большой языковой модели к русскому языку с помощью распространения изученного векторного представления // Journal of Language and Education. – 2024. – Т. 10, № 4. – С. 134-150. – DOI: 10.17323/jle.2024.22224
- Yandex Cloud. Fine‑tuning языковых моделей: как адаптировать ИИ для решения специализированных задач [Электронный ресурс]. — 2025. — URL: https://yandex.cloud/ru/blog/posts/2025/03/fine-tuning (дата обращения: 08.04.2026)
- Матаков Д. Обучение больших моделей с помощью QLoRA [Электронный ресурс]. – 2025. – URL: https://matakov.com/obuchenie-bolshix-modelej-s-pomoshhyu-qlora/ (дата обращения: 08.04.2026)



