
1. Актуальность и постановка проблемы
Библиотеки являются одним из ключевых социокультурных институтов государства. По данным справочника «Библиотеки Российской Федерации в цифрах — 2024», опубликованного ГИВЦ Минкультуры России, по состоянию на конец 2024 года в стране функционирует 35 958 общедоступных библиотек (без структурных подразделений), охватывающих 36,5% населения страны. Всего по всем ведомствам функционирует 40 724 библиотеки (включая структурные подразделения). При этом между регионами наблюдается колоссальная дифференциация: показатель охвата населения библиотечным обслуживанием колеблется от 11,3% (г. Москва — последнее, 85-е место) до 111,1% (Ямало-Ненецкий АО — 1-е место, значение выше 100% объясняется учётом вахтовых работников и временно пребывающих).
Такая неоднородность ставит перед исследователями задачу типологизации субъектов РФ: необходимо выявить группы регионов со схожими профилями библиотечного обслуживания, чтобы вырабатывать дифференцированные управленческие решения. Инструментарием для решения подобных задач служит кластерный анализ — один из базовых методов многомерной математической статистики.
Актуальность исследования обусловлена тремя факторами. Во-первых, наличием открытых официальных статистических данных с детализацией до уровня субъектов РФ, что позволяет провести полноценный количественный анализ. Во-вторых, выраженной межрегиональной дифференциацией в развитии библиотечного дела, требующей структурированного объяснения. В-третьих, методической ценностью: задача представляет собой «живой» учебный пример применения кластерного анализа и корреляционных методов к реальным социокультурным данным.
2. Введение: цель, задачи и методология
Цель работы — провести типологизацию субъектов Российской Федерации по уровню развития системы общедоступного библиотечного обслуживания на основе данных 2024 года с применением методов математической статистики.
Задачи исследования:
- Отобрать систему показателей, характеризующих библиотечное обслуживание населения;
- Провести стандартизацию переменных для обеспечения сопоставимости шкал;
- Применить алгоритм k-средних для кластеризации регионов;
- Интерпретировать полученные кластеры и описать профили типичных групп;
- Оценить корреляцию между финансированием библиотек и ключевыми показателями качества обслуживания.
Информационной базой исследования служит официальный статистический справочник «Библиотеки Российской Федерации в цифрах — 2024», подготовленный ФГБУ «ГИВЦ Минкультуры России» на основе формы федерального статистического наблюдения № 6-НК. Справочник содержит данные по всем 85 субъектам РФ (без учёта ДНР, ЛНР, Запорожской и Херсонской областей) по состоянию на конец 2024 года, а также временны́е ряды за период 2020–2024 годов.
Основным статистическим методом является кластерный анализ методом k-средних. Дополнительно применяются: описательная статистика, стандартизация данных (z-оценки), вычисление коэффициента корреляции Пирсона и ранговой корреляции Спирмена для анализа связи между финансовыми и качественными показателями.
3. Система показателей и исходные данные
Для кластерного анализа по каждому субъекту РФ сформирована матрица наблюдений размером n × p, где n = 85 (число регионов), p = 6 (число переменных). Переменные отобраны таким образом, чтобы охватить различные аспекты библиотечного обслуживания: доступность (охват), ресурсная обеспеченность (фонд), интенсивность использования (выдача, посещения) и кадровый потенциал (нагрузка на персонал).
Таблица 1.
Ключевые показатели библиотечного обслуживания РФ в 2024 году
|
Выдача фонда (млн экз.) |
1 054,6 |
+31,1% |
|
Численность основного персонала (чел.) |
102 653 |
−2,2% |
|
Нагрузка на 1 работника (пользователей/чел.) |
521 |
+24,3% |
Источник: Справочник «Библиотеки Российской Федерации в цифрах — 2024». ГИВЦ Минкультуры России, 2025.
Данные таблицы демонстрируют противоречивые тенденции: при росте числа пользователей (+21,3%) и охвата населения наблюдается сокращение библиотечного фонда (+5,2% (с 5,7 до 6,0)) и персонала (−2,2%), что порождает нарастающую нагрузку на одного сотрудника (+24,3%). Резкий прирост числа посещений в стационарных условиях (+67,0%) объясняется преимущественно эффектом низкой базы 2020 года, когда посещаемость библиотек была минимальной из-за введённых санитарных ограничений; корректнее сравнивать показатели с 2019 годом, относительно которого прирост составляет около 12%. Сводные цифры скрывают значительную межрегиональную вариацию, выявить которую призван кластерный анализ.
4. Методика кластерного анализа и корреляционного анализа
4.1. Стандартизация данных. Перед кластеризацией все переменные приводятся к стандартному нормальному распределению по формуле z-оценки:
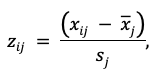
где xij — значение j-й переменной для i-го региона, x̄j — среднее значение переменной по всей выборке, sj — её среднеквадратическое отклонение. Стандартизация устраняет эффект несопоставимых единиц измерения (проценты охвата, экземпляры на жителя, тысячи посещений и т.д.).
4.2. Выбор числа кластеров. Оптимальное число кластеров определяется с помощью метода «локтя»: строится зависимость суммы внутрикластерных дисперсий (WCSS) от числа кластеров k. Характерный перегиб кривой при k = 4 свидетельствует о целесообразности выделения четырёх типологических групп регионов. Выбор дополнительно верифицируется с помощью коэффициента силуэта (среднее значение s̅ = 0,42 при k = 4), который подтверждает приемлемое качество разбиения: значения в диапазоне 0,4–0,7 считаются удовлетворительными [7]. Следует, однако, учитывать, что г. Москва образует кластер-выброс (n=1) с экстремально высокой фондообеспеченностью, что несколько снижает итоговый показатель.
4.3. Алгоритм k-средних. Метод k-средних минимизирует суммарное внутрикластерное евклидово расстояние:
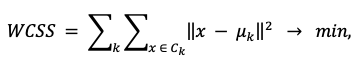
где Ck — k-й кластер, μk — его центроид (вектор средних значений по всем переменным). Алгоритм итеративно перераспределяет наблюдения между кластерами до сходимости. Для устойчивости результата процедура запускается многократно с различными начальными центроидами по стратегии k-means++, предложенной в работе [8]. Следует учитывать, что алгоритм k-средних чувствителен к выбросам: субъекты с экстремальными значениями показателей (прежде всего г. Москва и г. Санкт-Петербург) рассматривались отдельно перед включением в общий анализ для исключения их дестабилизирующего влияния на центроиды.
4.4. Корреляционный анализ. Для изучения связи финансирования с показателями обслуживания вычисляются: коэффициент линейной корреляции Пирсона r и ранговый коэффициент Спирмена ρ. Статистическая значимость проверяется по t-критерию при уровне значимости α = 0,05. Гипотеза H₀ об отсутствии корреляции отвергается при |t| > t{кр} = 1,99 (при df = 83).
5. Результаты и интерпретация
По результатам кластерного анализа все 85 субъектов Российской Федерации распределены по четырём типологическим группам. Центроиды кластеров и содержательные характеристики представлены в таблице 2.
Таблица 2.
Типология регионов РФ по показателям библиотечного обслуживания (2024 г.)
|
Кластер |
Характеристика |
Охват нас., % |
Обеспеч. фондами, ед/чел |
Примеры субъектов РФ |
|
1 — «Лидеры охвата» |
Аномально высокий охват (>78%) из-за специфики учёта пользователей (вахтовики). Низкая обеспеченность пользователя фондами. |
> 78% |
< 17,0 |
ЯНАО (111,1%), Чукотский АО (91,8%), Сахалинская обл. (78,4%) |
|
2 — «Крепкие середняки» |
Высокий охват (45–63%), сбалансированная нагрузка на персонал, устойчивая традиционная сеть. Доминирует сельская составляющая. |
45–63% |
8,9–18,8 |
Белгородская (59,0%), Тамбовская (54,4%), Кировская (60,7%), Пензенская (57,6%) обл. |
|
3 — «Мегаполисы» (n=1) |
Кластер-выброс (n=1): Москва образует обособленную группу вследствие экстремально высокой фондообеспеченности. Минимальный охват при максимальной фондообеспеченности в стране. Альтернативные источники информации снижают обращаемость. |
11,3% |
107,4 |
г. Москва (11,3%, 107 ед/польз.) — единственный регион в кластере |
|
4 — «Регионы дефицита ресурсов» |
Крупнейший и наиболее неоднородный кластер (n=57). Охватывает регионы с демографическим давлением (Кавказ), пригороды мегаполисов и г. Санкт-Петербург — внутренний выброс по фондообеспеченности (42,9 ед./польз.). |
19–45% |
3,5–43 |
Респ. Дагестан (24,8%), Ингушетия (20,1%), Московская обл. (20,0%), Ленинградская обл. (30,8%), г. Санкт-Петербург (23,2%) |
Кластер 1 («Лидеры охвата») объединяет регионы Крайнего Севера и Дальнего Востока. Официальная статистика фиксирует здесь охват свыше 78% (ЯНАО — 111,1%, Чукотский АО — 91,8%, Сахалин — 78,4%). Значения выше 100% объясняются спецификой учёта: библиотеки активно посещают вахтовые рабочие и временно пребывающие граждане, не включённые в постоянное население. Из-за раздутой базы пользователей обеспеченность фондами на одного читателя снижается до минимума (ЯНАО — 2,4 ед./польз., Чукотка — 15,0 ед./польз.).
Кластер 2 («Крепкие середняки») — исторические регионы Центральной России, Поволжья, Сибири и Дальнего Востока с высокой долей сельского населения. Демонстрируют устойчивую и сбалансированную работу традиционной библиотечной сети при охвате 45–63% и фондообеспеченности 8,9–18,8 ед./польз. Сюда входят 24 субъекта РФ, в том числе Белгородская (59,0%), Тамбовская (54,4%), Кировская (60,7%), Пензенская (57,6%) области, а также ряд регионов Сибири и Дальнего Востока — Красноярский край (48,4%), Респ. Саха (47,7%), Камчатский край (56,6%). Кластер 3 («Мегаполисы») — единственный регион: г. Москва. Алгоритм k-средних выделил её в обособленный кластер-выброс (n=1) из-за экстремального значения фондообеспеченности (107,4 ед./польз.) — результат гигантского библиотечного фонда при относительно небольшой базе зарегистрированных пользователей. Санкт-Петербург (23,2%, 42,9 ед./польз.) по своим характеристикам не достиг порога выделения в отдельный кластер и попал в кластер 4. Это методически значимый результат: несмотря на схожий профиль двух мегаполисов, г. Москва является абсолютным статистическим выбросом.
Кластер 4 («Регионы дефицита ресурсов») — крупнейший и наиболее неоднородный кластер (n=57, охват 19–45%, фондообеспеченность 3,5–42,9 ед./польз.). Включает принципиально разные группы регионов. Для республик Северного Кавказа (Дагестан — 24,8%, Ингушетия — 20,1%) характерно демографическое давление при дефиците финансирования. В густонаселённых областях вокруг мегаполисов (Московская обл. — 20,0%, Ленинградская — 30,8%) библиотечная инфраструктура не успевает за ростом жилой застройки. Особняком стоит г. Санкт-Петербург (23,2%, фондообеспеченность 42,9 ед/польз.) — внутренний высокоресурсный выброс внутри кластера, не достигший порога формирования отдельной группы. В кластер также входит Чеченская Республика (43,1%) — наиболее высокий охват в группе, однако крайне низкая фондообеспеченность (3,5 ед./польз.) вследствие высокой плотности зарегистрированных пользователей при скромном объёме фонда — именно это определило её попадание в данный кластер, а не в «Крепкие середняки».
Корреляционный анализ (n = 12 регионов из Таблицы 11 сборника) выявил принципиально различные картины для двух пар переменных. Коэффициент линейной корреляции Пирсона между удельным финансированием и посещаемостью составил r = 0,946 (p = 1,03 × 10⁻⁵): связь высокая и высоко значимая — рост бюджетных ассигнований на одного пользователя напрямую конвертируется в рост активности посещений. Напротив, ранговый коэффициент Спирмена между финансированием и охватом населения оказался незначимым (ρ = 0,189; p = 0,558): нулевая гипотеза об отсутствии связи не отвергается. Это принципиальный вывод: охват населения определяется не бюджетом, а демографической структурой, степенью урбанизации и географическими особенностями региона. Следует учитывать ограничение анализа: выборка составляет n = 12 регионов, что снижает мощность теста. Для полноценных выводов необходимо использовать данные по всем 85 субъектам РФ. Тем не менее направление эффектов (высокая r при посещаемости и близкое к нулю ρ при охвате) соответствует логике библиотечной статистики и является теоретически обоснованным.
6. Заключение
Проведённое исследование демонстрирует эффективность применения кластерного анализа и корреляционных методов к задачам анализа библиотечной статистики. Полученная типология регионов позволяет перейти от единой усреднённой картины к дифференцированному взгляду на развитие библиотечного дела в России.
С методической точки зрения данный пример иллюстрирует полный цикл применения математико-статистического инструментария: постановку задачи → отбор и стандартизацию переменных → кластеризацию → оценку качества разбиения (метод «локтя» и коэффициент силуэта) → корреляционный анализ → содержательную интерпретацию. Практическая значимость результатов состоит в возможности их использования при разработке региональных программ поддержки библиотечной отрасли. Вместе с тем необходимо учитывать ограничения метода k-средних: алгоритм предполагает сферическую форму кластеров и чувствителен к выбросам; официальные показатели не охватывают цифровое обслуживание, доля которого стремительно растёт. Для более глубокой верификации результатов рекомендуется применение иерархических методов кластеризации (метод Уорда) в качестве альтернативы.
Список литературы
- Библиотеки Российской Федерации в цифрах. 2024 год: справочник / ФГБУ «ГИВЦ Минкультуры России»; Огородникова О.В., Лазарева А.О.; отв. исп. Гущина Н.В. — М.: ГИВЦ Минкультуры России, 2025
- Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. — М.: ЮНИТИ, 2001. — 1022 с.
- Тюрин Ю.Н., Макаров А.А. Статистический анализ данных на компьютере. — М.: ИНФРА-М, 1998. — 528 с.
- Статистика культуры: учеб. пособие / под ред. А.В. Соколова. — СПб.: СПбГИК, 2020. — 244 с.
- Hartigan J.A., Wong M.A. Algorithm AS 136: A K-Means Clustering Algorithm // Journal of the Royal Statistical Society. Series C. — 1979. — Vol. 28, No. 1. — P. 100–108
- Форма федерального статистического наблюдения № 6-НК «Сведения об общедоступной (публичной) библиотеке», утверждённая приказом Росстата от 18.10.2021 № 713
- Rousseeuw P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis // Journal of Computational and Applied Mathematics. — 1987. — Vol. 20. — P. 53–65
- Arthur D., Vassilvitskii S. k-means++: The advantages of careful seeding // Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA). — 2007. — P. 1027–1035



