
Введение
В настоящее время большая часть людей пользуется онлайн-магазинами вместо того, чтобы ходить в физические и выбирать товары там. Однако физические магазины имеют неоспоримое преимущество перед онлайн-магазинами: они предоставляют возможность ознакомиться со свойствами товара до покупки и, более того, до оплаты пути товара. В случае же, когда товар не подходит, покупатель может сразу поменять выбор, не дожидаясь второй доставки. Для того, чтобы совершить покупку в онлайн-магазине, пользователю нужно читать комментарии, многочисленные и не всегда несущие полезную нагрузку. Именно поэтому автоматическая обработка комментариев в интернет-магазинах для выделения свойств продукта — это важная задача. Когда покупатель делает приобретение в интернет-магазине, он часто оказывается в неведении относительно свойств продукта, в то время как комментарии на этой и других платформах уже содержат всю необходимую ему для принятия решения информацию. Данная проблема становится особенно острой сейчас, когда на рынке несколько больших маркетплейсов, продукты в которых часто совпадают, а комментарии — отличаются. Число комментариев также становится всё больше, а это значит, что покупатель часто не может себе позволить потратить время, достаточное для формирования обоснованного мнения о продукте на основе комментариев. Представляет интерес создание независимой системы, способной собрать данные о продукте со всех маркетплейсов и сформировать всеобъемлющий отчёт об общем настроении отзывов и свойствах продукта. Частично данная задача уже решена. В этой статье рассматриваются различные методы и средства определения указанных свойств комментариев.
Термины и постановка задачи
В данной статье используются следующие термины:
- BiLSTM — модификация рекуррентной нейронной сети LSTM, выполняющая обработку входных данных в двух направлениях одновременно — в прямом и в обратном.
- LSTM — рекуррентная нейронная сеть, которая использует два хранилища весов — долгосрочную и краткосрочную память, отчего и получила своё название. Более о LSTM можно прочитать в статье Sepp Hochreiter, Jürgen Shmidhüber «Long Short-Term Memory», Neural Computation 9(8): 1735-1780, 1997.
- Модель — Модель искусственного интеллекта, модель нейронной сети, искусственная нейронная сеть; также результат обучения нейронной сети.
- Слабоструктурированные текстовые данные (ССТД) — это любые структуры текстовых данных между строгой структурированностью и её полным отсутствием, то есть, это данные, находящиеся не в табличном формате, но и не хаотично разбросанные по тексту.
- MBTI — Myers-Briggs Type Indicator, система психологического тестирования, типология Майерс — Бриггс.
В данной статье ставится задача обзора существующих материалов, способных помочь в создании системы, обрабатывающей комментарии к продуктам. Данная задача состоит из нескольких подзадач. Во-первых, требуется обрабатывать слабоструктурированные текстовые данные: исправлять опечатки и заменять сокращения на их расшифровки. Это может оказаться необходимо, поскольку при дальнейшей обработке опечатки и сокращения могут искажать значение комментария в глазах алгоритмов. Во-вторых, необходимо извлекать значимые части из комментариев. В-третьих, требуется проводить анализ тональности в комментариях для получения общей картины отзыва.
Обработка слабоструктурированных текстов
Первая задача, обработка слабоструктурированных текстов, рассмотрена в диссертации Макаровой Елены Андреевны по теме «Модели и алгоритмы обработки слабоструктурированных текстовых данных на основе методов искусственного интеллекта» [1]. В диссертации предлагаются методы и алгоритмы обработки текстовых данных на основе искусственного интеллекта. Хотя целью автореферата не является обработка комментариев, но в силу близости отраслей становится возможным использование результатов автора. В работе предлагается несколько алгоритмов автоматизированной обработки сокращений, что важно для обработки комментариев, поскольку при использовании сокращений в список свойств товара одно и то же свойство может попасть в сокращённом написании и в полном, что нежелательно.
Один из алгоритмов использует словари:
- Определить все слова в тексте, не соответствующие словам из словаря (к примеру, словаря Даля).
- Раскрыть эти слова как сокращения, подставив вместо них соответствующие им в словаре сокращений словосочетания.
Однако, анализируя контекст сокращений, возможно получить более точные расшифровки сокращений, если на исследуемых данных обучить нейросетевую модель для вычисления векторного представления слов и предсказывать общее значение сокращений по их окружению. Тогда семантическая близость между лингвистическими единицами вычисляется как расстояние между векторами. Кроме того, для того, чтобы автоматически трансформировать сокращение в полную форму слова, помимо контекстной близости, в русской традиции сокращений необходимо выполнение также следующих правил:
1. Выполняется одно из условий:
- сокращение совпадает с началом семантически близкого слова;
- сокращение совпадает с началом семантически близкого слова, при условии удаления гласных букв;
- начало и конец найденного слова совпадает с сокращением, середина заменяется дефисом или «/».
2. найденное слово не является сокращением и присутствует в словаре употребляемых слов русского языка;
3. слово, удовлетворяющее вышеперечисленным условиям, является единственным в окрестности слова.
Также в работе предлагается алгоритм для определения семантической близости слабоструктурированных текстов, что также полезно для обработки комментариев, поскольку при достаточной близости извлечённых значимых частей комментариев имеет смысл их объединять, к примеру, такие предложения, как «Понравился цвет» и «Цвет хороший» стоит объединить. Семантическая близость – метрика близости, используемая для оценки семантической (смысловой) схожести языковых единиц (слов, словосочетаний, выражений, предложений и т.д.). Меры семантической близости широко применяются в различных задачах обработки ССТД. В зависимости от используемой метрики и алгоритма, семантическую близость можно определить для данных разной длины: от отдельных слов до больших текстовых документов. Среди метрик предлагаются:
- коэффициент Жаккара;
- косинусное расстояние с векторизацией методом TF-IDF;
- Word Mover’s Distance.
Автореферат использует для апробации указанных методов несколько наборов данных, среди которых набор резюме и два набора медицинских данных. Среди важных замечаний следует упомянуть, что автор для своих целей и задач использует в том числе методы классического машинного обучения, при этом почти исключив из рассмотрения нейронные сети. Это даёт автореферату уникальную точку зрения, которая, несомненно, ценна для формирования более широкого представления о текущем состоянии области знаний. Поскольку классическое машинное обучение отличается значительной производительностью в сравнении с моделями искусственного интеллекта, по крайней мере, если говорить об архитектурах BERT или GPT, то данный взгляд может оказаться важным для моей темы, и, более того, может оказаться именно тем решением, которое окажется наиболее подходящим для задач извлечения из комментариев к продукту интернет-магазинов свойств товара.
Определение значимых частей в комментариях
Перейдём к другому аспекту данной области, а именно к определению значительных частей в комментариях. Рассмотрим для этого автореферат Бабака Никиты Григорьевича на тему «Автоматическое обезличивание персональных данных с использованием технологий искусственного интеллекта» [2]. Существует также статья Антонова Е.В. «Evaluation of Named Entity Recognition Software Packages for Data Mining», опубликованную в 2024 г. в журнале Physics of Particles and Nuclei [3]. Статья рассказывает о проведённых автором исследованиях в области определения значимых частей в предложениях на русском языке, в частности, именованных сущностей, таких как человек, место, организация. Данная статья представляет значительный интерес для обработки комментариев, поскольку разрабатываемая методика предполагает определение в комментариях значимых частей, а сами комментарии предполагаются на русском языке. В статье сравниваются различные программные пакеты: Natasha, SpaCy, Stanza, DeepPavlov, — предназначенные для указанной цели. В результате сравнения определено, что наилучших характеристик достигает модель Natasha, которая достигает точности 0.88 при определении людей, 0.68 при определении мест и 0.47 при определении организаций. Стоит заметить, что, хотя кажется, что результат 0.47 хуже случайного выбора, на самом деле это не так, поскольку перед моделью стоит не задача выбора из двух вариантов, а задача определения положения объекта в тексте, где вероятность ошибки значительно возрастает. Таким образом, точность 0.47 достаточно высока. Важным замечанием в статье является то, что для достижения наилучших результатов возможно комбинирование различных моделей.
Также существует статья «Распознавание персональных данных с помощью модели глубокого обучения» [4], опубликованной Бабаком Н.Г. в 2024 г. в журнале «Современные информационные технологии и ИТ-образование». В статье описано распознавание персональных данных с помощью модели глубокого обучения, однако важно заметить, что многие методы, указанные в статье, также могут быть использованы и для определения значимых частей в комментариях. Статья предлагает определение необходимых данных несколькими способами:
- распознавание на основе правил, включая использование регулярных выражений и словарей,
- распознавание с использованием моделей ИИ,
- ручное распознавание, при котором владелец данных самостоятельно определяет содержание персональной информации.
В статье описываются ограничения на область применимости методик ручного распознавания и распознавания на основе правил. Автор рассматривает в качестве средств распознавания данных следующее:
- регулярные выражения;
- расчёт контрольного разряда;
- поиск по словарю;
- нечёткий поиск;
- анализ контекстного окружения.
Некоторая часть методов неприменима для обработки комментариев, однако другие достаточно актуальны, к примеру, регулярные выражения, нечёткий поиск, анализ контекстного окружения.
В статье также было проведено сравнение между моделями нейронных сетей BiLSTM, BERT и GigaChat (GPT). Исследование требует повтора для нового набора исходных данных, поскольку специфика комментариев может существенно отличаться от таковой у документов и других источников, содержащих персональные данные, однако структура исследования заслуживает внимания. Важным замечанием является то, что BiLSTM обучается автором лично, в то время как GPT и BERT предоставлялись в обученном виде, что заранее предоставляет этим моделям некоторое преимущество при измерениях. Статья использует для проведения исследования язык Python и библиотеку PyTorch. В исследовании упоминается, что BiLSTM «недостаточно хорошо учитывает контекст, из-за чего разнородные атрибуты Пдн плохо распознаются в неструктурированной информации». Исследование не упоминает, связан ли такой результат BiLSTM с аппаратными ограничениями, имеющимися у автора, или же с ограничениями, связанными с архитектурой модели, потому данный раздел статьи представляет значительный интерес для дальнейшего исследования. Далее приводятся результаты предобученных моделей BERT и GPT. Выяснено, что при равных аппаратных условиях на источниках персональных данных более оптимальной является модель BERT.
Также в статье предложен комбинированный метод распознавания, применимый также и в выбранной мной области. Комбинированный метод представляет собой сочетание алгоритмов на основе правил с моделью BERT и оказывается наиболее результативным, имеющим показатели, значительно превосходящие альтернативы. Замечанием является следующее: поскольку обработка комментариев специфична высокой нагрузкой на оборудование и программные средства, то модель BERT кажется несколько расточительной. Для полноты картины также следует включить в исследование такие модели, как DistilBert и TinyBert. Окончательные результаты измерений можно видеть на рисунке 1.
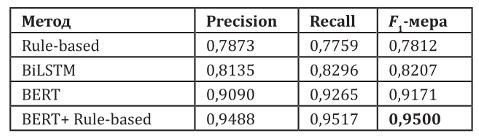
Рисунок 1. Таблица результатов замеров, приведённая в статье
Определение тональности
Последним по порядку, но не по важности является тема определения тональности комментариев, и в этой теме значительное место занимает исследование Зоткиной Алены Александровны по теме «Методы и алгоритмы формирования психологического портрета пользователя социальной сети для эффективного подбора кадров»[5]. В качестве метода классификации в автореферате используется методика MBTI. Автореферат указывает, что причиной этому наибольшая среди известных комплексность суждения. В работе для классификации по MBTI сравнивается несколько различных классификаторов, в том числе, искусственные нейронные сети и K Nearest Neighbours. Выясняется, что для большинства типов личности согласно MBTI искусственная нейронная сеть показывает лучшие результаты, однако на двух из них оказывается позади. С чем такое различие может быть связяно, сказать, судя только по статье, достаточно сложно, однако вероятно, что поскольку сами типы MBTI являются в достаточной мере неопределёнными, то нейронная сеть, возможно, выявила это свойство типов и не смогла выдавать достаточно точные ответы на таких типах. Для моих задач куда более важными являются статьи, упомянутые в исследовании и результаты которых в том числе отражены в автореферате. Среди них:
- Зоткина А.А., Холкина В.М. Обзор методов анализа настроений // Современные информационные технологии. — 2023. — № 38 (38). — С. 55-59 [6].
- Мартышкин А.И., Зоткина А.А. Основные проблемы в области определения тональности текста // Современные информационные технологии. — 2024. — № 39 (39). - С. 85-88 [7].
- Мартышкин А.И., Зоткина А.А. Некоторые подходы к определению тональности текста // Современные информационные технологии. — 2024. — № 39 (39). - С. 88-92 [8].
В статьях описываются важные аспекты определения тональности, в том числе в приложении к задачам, достаточно близким к задачам моего исследования.
Статья «Обзор методов анализа настроений» рассматривает методы для анализа настроений, которые включают «подход на основе лексики, подход машинного обучения и гибридный подход». Отмечаются недостатки подхода на основе лексики, в частности, малая связь с контекстом, что не позволяет достаточно точно оценивать настроение касательно конкретных пунктов. В статье предлагается также и решение данной проблемы, а именно, использование специализированных словарей под каждую предметную область, однако в силу количества товаров в интернет-магазине данный подход кажется неприменимым. Также в статье рассматриваются методы машинного обучения. Утверждается, что наиболее распространены подходы обучения с учителем на основе датасета и обучения без учителя на основе лексикона. Наиболее популярным, как следует из статьи, является гибридный метод, когда методы машинного обучения объединяются с методами анализа на основе лексиконов. Статья предлагает следующие шаги гибридного метода:
- выявление функций, которые будут использоваться в рамках подхода машинного обучения;
- автоматическое создание аннотированного корпуса для обучения и проверки классификаторов при разных размерах датасета;
- создание словаря тональности;
- эти различные подходы объединяются и тестируются для получения лучших и оптимизированных результатов.
В статье упоминается, что даже применение гибридного подхода не решает проблему зависимости от предметной области. Возможно, что более сложные модели искусственного интеллекта, такие как BERT, окажутся достаточны, чтобы решить данную проблему.
Статья «Основные проблемы в области определения тональности текста» обсуждает сложности, которые встают перед исследователем, который решится обратиться к средствам определения тональности текста. Некоторые из них связаны с неструктурированностью текста, другие — с тем, что чёткого определения для эмоций человека на данный момент не существует, и, соответственно, невозможно однозначно безошибочно машинным образом определить тональность текста. Однако возможно приблизиться к этому достаточно, чтобы считать ошибку незначительной или, может быть, даже сравнимой с таковой у человека. Важной деталью является различие в рассматриваемых различными методами спектрах эмоций. Большинство придерживается тройки «положительно-нейтрально-отрицательно», однако другие методы используют более сложные системы, к примеру, «сильно положительный, положительный, нейтральный, отрицательный и сильно отрицательный». Также поднимается проблема оценки качества классификатора. В качестве решения предлагается F1-мера, поскольку она сочетает в себе наиболее важные метрики, а именно, точность (precision) и полнота (recall).
Статья «Некоторые подходы к определению тональности текста» является развитием статьи «обзор методов анализа настроений» и предлагает более развёрнутое рассмотрение существующих методик. Статья предлагает такие средства, как наивный Байесовский классификатор, метод опорных векторов и нейронные сети. Статья рассказывает о недостатках классических методов машинного обучения, среди которых сильная зависимость от данных в том смысле, что, во-первых, данные методы требуют значительное количество данных для обучения, и, во-вторых, из данных требуется извлечь признаки, в то время как в классической постановке задачи на вход подаётся текст, и, возможно, некоторые метки класса. Преимуществом нейронных сетей в этом контексте является как раз самостоятельность при выделении признаков. К сожалению, при этом нейронные сети, как указывает статья, не избежали трудностей, связанных с объёмом данных для обучения.
Обобщая вышесказанное, автореферат и статьи, указанные в нём, позволяют судить о текущем состоянии области анализа тональности в тексте. Как можно заметить, область находится в стадии развития, однако существующие средства могут оказаться достаточными для решения задач обработки комментариев.
Не менее важной в подтеме определения тональности является работа P. Vijayaragavan и др. «Sustainable sentiment analysis on E-commerce platforms using a weighted parallel hybrid deep learning approach for smart cities applications» [9]. Статья предоставляет уникальный взгляд на изучаемую проблему. Она опирается на более раннюю статью [10], где рассказывается об использовании метода опорных векторов в определении тональности комментариев, а также на статью [11], где сравниваются результаты применения метода случайного леса с рекурсивным удалением признаков (RF-RFD) с методами машинного обучения: Naive Bayes, деревом решений, методом опорных векторов.
В статье рассказывается о улучшенном подходе к анализу тональности, WPHDL-SAEPR, который построен на основе Word2Vec, SVD и Restricted Boltzmann.
Word2Vec - общее название для семейства алгоритмов, учитывающих ближайшие N слов, служащих для преобразования слов в тексте в векторы таким образом, чтобы более близкие по значению слова в векторном представлении оказались также близки друг к другу геометрически [12].
Также утверждается [12], что модель в её наиболее известной версии, CBOW, способна воспринимать и отображать некоторые зависимости между словами, такие как "слово "Королева" относится к слову "Королевы" так же, как "Король" к слову "Короли".
SVD - Singular Value Decomposition, сингулярное разложение - техника линейной алгебры, определяющаяся, как показывает формула (1):
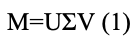
где 𝑀 - матрица, подлежащая разложению,
𝑈, 𝑉 - унитарные матрицы, состоящие из левых и правых сингулярных векторов 𝑀 соответственно,
Σ - матрица размера 𝑚 ∗ 𝑛 с неотрицательными элементами, у которой элементы, лежащие на главной диагонали — это сингулярные числа, а все элементы, не лежащие на главной диагонали, нулевые.
Restricted Boltzmann Machine - нейронная сеть, обучающаяся без учителя на основе вероятностной модели; она имеет целью максимизацию вероятности того, что конкретный терм будет найден в текущей позиции[13]. RBM вводится в [14] П. Смоленским из Johns Hopkins University в поисках языка для представления теорий о сознании в парадигме машинного обучения как противоположности символическому ИИ.
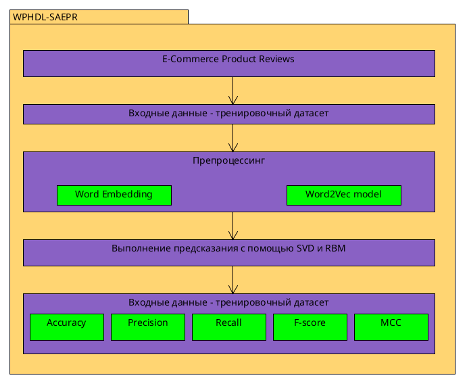
Рисунок 2. Общий вид подхода WPHDL-SAEPR
Подход имеет общую структуру, как показывает рис. 2. Как можно заметить, автор использует модель Word2Vec для препроцессинга исходных данных, чтобы затем выполнить классификацию с помощью гибридной модели SVD-RBM. Здесь датасет сначала подготавливается, затем пропускается через препроцессинг - модель Word2Vec, после чего передаётся для выполнения предсказания SVD и затем модели Больцмана. Последним шагом является проверка качества модели посредством нескольких мер, среди которых Accuracy, Precision, Recall, F-Score, MCC, которые рассчитываются по формулам (2), (3), (4), (5), (6) соответственно.
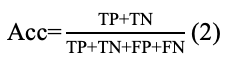
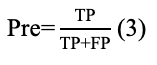
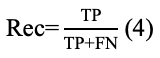
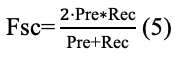
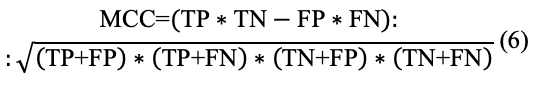
где Acc — Accuracy,
TP — число значений в датасете, которые были отнесены моделью искусственного интеллекта (ИИ) к положительным эмоциям, в то время как в датасете они также отнесены к положительным эмоциям;
FP — число значений в датасете, которые были отнесены моделью ИИ к положительным эмоциям, в то время как в датасете они отнесены к отрицательным эмоциям;
TN — число значений в датасете, которые были отнесены моделью ИИ к отрицательным эмоциям, в то время как в датасете они также отнесены к отрицательным эмоциям;
FN — число значений в датасете, которые были отнесены моделью ИИ к отрицательным эмоциям, в то время как в датасете они отнесены к положительным эмоциям;
Pre — Precision;
Rec — Recall;
Fsc — F-Score;
MCC — MCC.
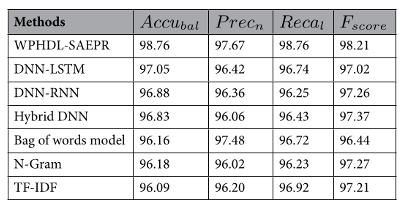
Рисунок 3. Результаты сравнения модели WPHDL-SAEPR с другими методами
Автор сравнивает свой подход с другими подходами, как показывает рис. 3. Результаты показывают превосходство представленной модели над другими методами, однако также показывают, что менее затратные методы, такие как DNN-LSTM и TF-IDF, также достигают результатов, приемлемых для исследования. Стоит пояснить, что скрывается под аббревиатурами в таблице. DNN-LSTM - многослойная модель нейронной сети, использующая слои LSTM; DNN-RNN - многослойная модель нейронной сети, использующая рекуррентные нейронные сети; Hybrid DNN - гибридная многослойная нейронная сеть (Deep Neural Network); Bag of Words Model - модель ИИ, использующая для работы неупорядоченный набор слов из текста, вместо этого сосредотачиваясь исключительно на количествах слов; N-Gram - модель, использующая для предсказаний словосочетания из нескольких слов; TF-IDF - усложнение Bag of Words, сосредотачивающееся не на количестве вхождений слова в каждый из примеров, а на метрике, прямо пропорциональной числу вхождений слова в пример, и обратно пропорциональной его частоте в документе. Реализаций моделей автор не предоставил.
Важным здесь является замечание, что автор посчитал достаточной бинарную классификацию отзывов по тональности, что также удовлетворяет потребности данного исследования.
Обобщая вышесказанное, можно видеть, что для решения задачи анализа тональности в комментариях существует достаточно много инструментов, среди которых наивный Байесовский классификатор, метод опорных векторов, TF-IDF, BoW, а также LSTM и рекуррентные нейронные сети, а также подход WPHDL-SAEPR, представленный в [9].
Заключение
В данной статье были рассмотрены материалы нескольких авторов, освещающие различные аспекты автоматической обработки комментариев для выделения положительных и отрицательных качеств продукта.
Исходя из собранных в статье сведений, можно заключить, что существуют следующие методы и программные средства, которые могут помочь в создании системы обработки комментариев:
- GPT, BERT, BiLSTM способны обеспечить нахождение значительных частей в предложениях,
- наивный Байесовский классификатор, метод опорных векторов, и нейронные сети, такие как LSTM или рекуррентные нейронные сети, нейронные сети с предобработкой с помощью TF-IDF или Bag of Words, а также подход WPHDL-SAEPR, представленный в [9], используются в анализе тональности.
Данная область имеет значительный потенциал развития. Опираясь на предыдущие исследования, можно построить полноценную систему для автоматической обработки комментариев для выделения положительных и отрицательных качеств продукта.
Список литературы
- Макарова Е.А., Модели и алгоритмы обработки слабоструктурированных текстовых данных на основе методов искусственного интеллекта, диссертация на соискание учёной степени кандидата технических наук, 2023
- Бабак Н.Г., Автоматическое обезличивание персональных данных с использованием технологий искусственного интеллекта, диссертация на соискание учёной степени кандидата технических наук, 2024
- Соколов И., Антонов Е.В., Evaluation of Named Entity Recognition Software Packages for Data Mining // Physics of Particles and Nuclei. 55, № 3
- Бабак Н.Г., Распознавание персональных данных с помощью модели глубокого обучения // Современные информационные технологии и ИТ-образование. 20, № 1
- Зоткина А.А., Методы и алгоритмы формирования психологического портрета пользователя социальной сети для эффективного подбора кадров, диссертация на соискание учёной степени кандидата технических наук, 2024
- Зоткина А.А., Холкина В.М., Обзор методов анализа настроений // Современные информационные технологии, № 38
- Мартышкин А.И., Зоткина А.А, Основные проблемы в области определения тональности текста // Современные информационные технологии. № 39
- Мартышкин А.И., Зоткина А.А., Некоторые подходы к определению тональности текста // Современные информационные технологии. № 39
- P. Vijayaragavan и др. Sustainable sentiment analysis on E-commerce platforms using a weighted parallel hybrid deep learning approach for smart cities applications [Электронный ресурс]. Scientific Reports, 2024. URL: https://www.nature.com/articles/s41598-024-78318-1 (дата обращения: 10.11.2025)
- Vijayaragavan P., Ponnusamy R., Aramudhan M. An optimal support vector Machine-based classification model for sentimental analysis of online product reviews [Электронный ресурс]. URL: https://www.sciencedirect.com/science/article/pii/S0167739X19333138 (дата обращения: 28.01.2026)
- Rezapour M. Sentiment classification of skewed shoppers’ reviews using machine learning techniques, examining the textual features [Электронный ресурс]. URL: https://www.researchgate.net/publication/344416505_Sentiment_classification_of_skewed_shoppers'_reviews_using_machine_learning_techniques_examining_the_textual_features (дата обращения: 28.01.2026)
- Tomas Mikolov и др. Efficient Estimation of Word Representations in Vector Space [Электронный ресурс]. arxiv.com, 2013. URL: https://arxiv.org/pdf/1301.3781 (дата обращения: 28.01.2026)
- scikit-learn developers. Neural network models (unsupervised) [Электронный ресурс]. Scikit-learn, 2024. URL: https://scikit-learn.org/stable/modules/neural_networks_unsupervised.html (дата обращения: 28.01.2026)
- P. Smolensky. Information Processing in Dynamical Systems: Foundations of Harmony Theory [Электронный ресурс]. 1986. URL: https://www.researchgate.net/publication/239571798_Information_processing_in_dynamical_systems_Foundations_of_harmony_theory (дата обращения: 28.01.2026)

