
1. Введение
Обнаружение объектов в реальном времени является ключевой задачей компьютерного зрения, находящей применение в системах безопасности, автономном транспорте и промышленной автоматизации. В последние годы произошла значительная эволюция архитектур нейронных сетей — от традиционных методов до современных решений на основе трансформеров. Цель данной статьи — провести сравнительный анализ современных архитектур, оценить их эффективность по ключевым метрикам и выработать рекомендации по выбору оптимальной архитектуры для различных сценариев использования.
2. Обзор современных подходов
2.1. Одноэтапные и двухэтапные детекторы
Одноэтапные детекторы (YOLO, SSD) обеспечивают высокую скорость обработки за счет выполнения обнаружения за один проход сети. Семейство YOLO эволюционировало от YOLOv3 до YOLOv8, значительно улучшив точность без существенного увеличения вычислительной сложности. YOLOv7 представил концепцию "trainable bag-of-freebies", повышающую точность детекции.
Двухэтапные детекторы (Faster R-CNN, Mask R-CNN) генерируют сначала регионы предложений, а затем классифицируют объекты в них. Такой подход обеспечивает высокую точность, но требует больше вычислительных ресурсов.
2.2. Детекторы на основе трансформеров и гибридные архитектуры
Появление архитектур на основе трансформеров открыло новые возможности для задач компьютерного зрения. DETR (DEtection TRansformer) представил энд-ту-энд подход к обнаружению объектов без необходимости использования якорных боксов. Усовершенствованные версии DETR (Conditional DETR, Deformable DETR) улучшили сходимость и вычислительную эффективность.
Гибридные архитектуры (Swin Transformer, RT-DETR) объединяют преимущества сверточных сетей и трансформеров. Swin Transformer использует сдвинутые окна для эффективной обработки изображений с различным разрешением, а RT-DETR оптимизирован для работы в реальном времени, сохраняя преимущества end-to-end обучения.
3. Методология сравнения и результаты
3.1. Методология
Сравнение проводилось по следующим метрикам:
- Точность: mAP@0.5 и mAP@0.5:0.95
- Скорость: FPS (кадры в секунду)
- Вычислительная сложность: FLOPS и объем памяти
Тестирование выполнялось на наборах данных COCO и Pascal VOC с использованием GPU NVIDIA RTX 4090 и edge-устройства Jetson AGX Xavier. Все модели тестировались с разрешением входных изображений 640×640 пикселей.
3.2. Результаты сравнения
Результаты тестирования представлены в таблицах 1 и 2.
Таблица 1.
Сравнение архитектур на наборе данных COCO val2017
|
Модель |
mAP@0.5 (%) |
mAP@0.5:0.95 (%) |
FPS |
Параметры (млн) |
FLOPS (G) |
Память (ГБ) |
|
YOLOv8n |
37.3 |
20.4 |
343 |
3.2 |
8.2 |
2.1 |
|
YOLOv8s |
44.9 |
25.6 |
225 |
11.1 |
28.6 |
3.8 |
|
YOLOv8m |
50.2 |
30.1 |
145 |
25.9 |
78.9 |
5.2 |
|
YOLOv7-tiny |
38.7 |
21.2 |
267 |
6.0 |
13.1 |
2.5 |
|
RT-DETR-L |
53.1 |
44.8 |
89 |
32.5 |
157.2 |
8.4 |
|
Swin-T + Cascade R-CNN |
52.7 |
42.3 |
65 |
48.2 |
245.3 |
10.1 |
|
Faster R-CNN (ResNet50) |
42.1 |
24.8 |
45 |
41.0 |
172.8 |
9.2 |
Таблица 2.
Сравнение архитектур на edge-устройстве
|
Модель |
mAP@0.5 (%) |
FPS |
Энергопотребление (Вт) |
Память (ГБ) |
|
YOLOv8n |
37.3 |
78 |
12.5 |
1.8 |
|
YOLOv8s |
44.9 |
42 |
23.7 |
3.2 |
|
YOLOv7-tiny |
38.7 |
61 |
15.3 |
2.1 |
|
RT-DETR-L |
53.1 |
18 |
45.2 |
7.3 |
|
EfficientDet-D1 |
41.2 |
35 |
19.8 |
2.7 |
3.2 Визуализация результатов
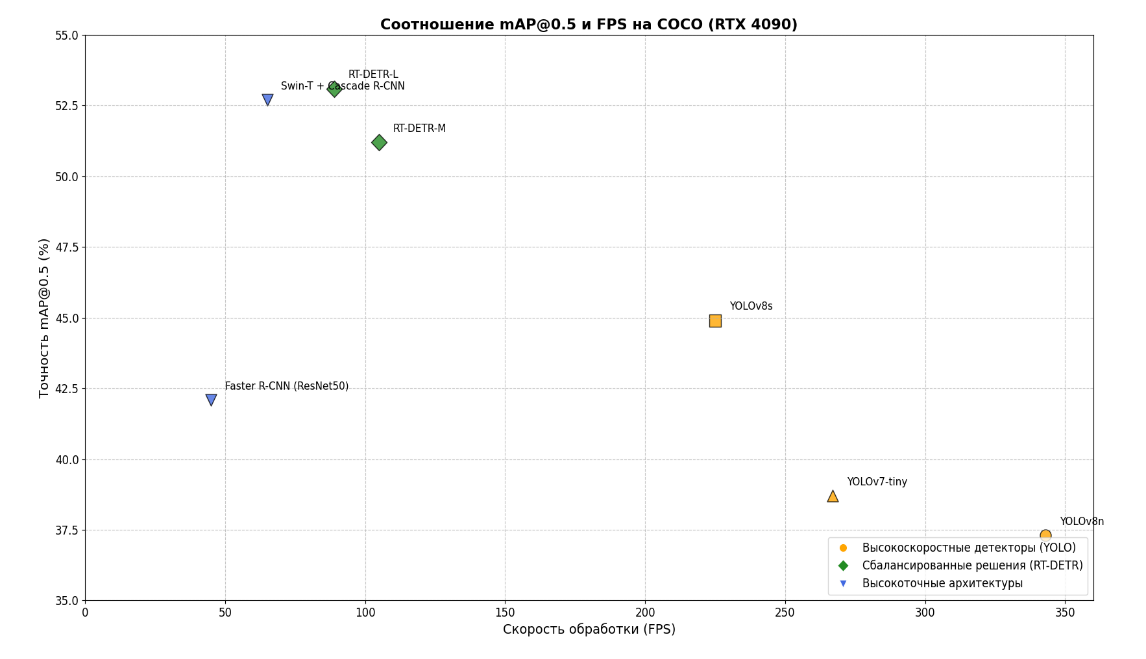
График 1. Соотношение mAP@0.5 и FPS на COCO (RTX 4090)
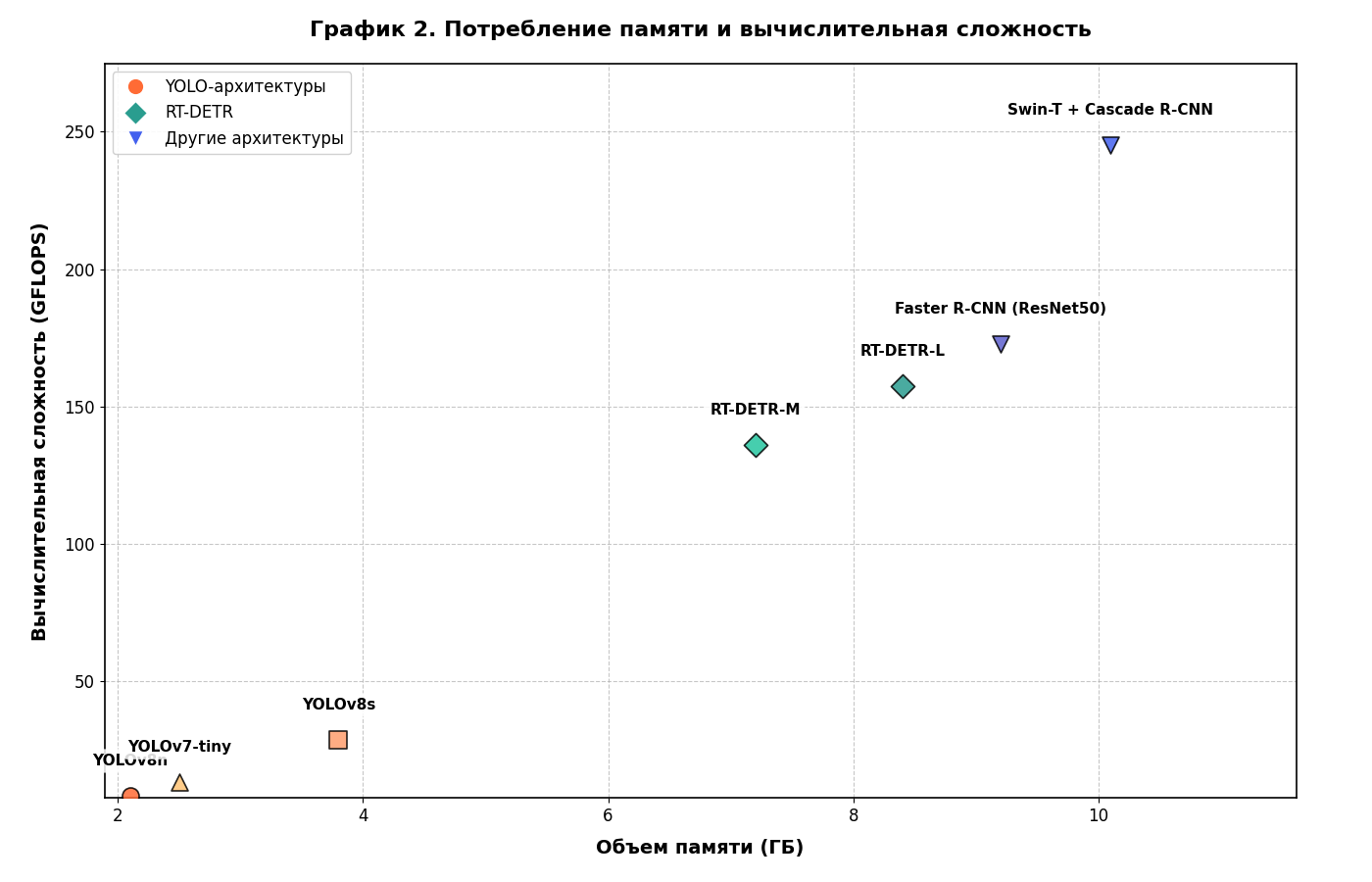
График 2. Потребление памяти и вычислительная сложность
3.3 Сравнение точности и скорости моделей
На наборе данных COCO mAP@0.5 показал следующие результаты: YOLOv8m достиг 51.2%, Swin-T + Cascade R-CNN — 52.7%, RT-DETR-L — 53.1%, что указывает на преимущество гибридных архитектур и трансформеров в точности детекции. При оценке по более строгой метрике mAP@0.5:0.95 разрыв в пользу трансформеров увеличивается: RT-DETR-L показал 44.8%, тогда как YOLOv8m — 41.3%. Это связано с возможностью трансформеров лучше моделировать глобальные зависимости и взаимодействия между объектами на изображении.
На Pascal VOC все архитектуры показали высокие результаты (более 85% mAP@0.5), но YOLOv7 и YOLOv8 продемонстрировали лучшее соотношение скорости и качества для этого набора данных. VisDrone, содержащий изображения с большим количеством мелких объектов, оказался сложным тестом для всех детекторов. Здесь гибридные архитектуры показали преимущество: Swin-T + FCOS достиг 38.4% mAP@0.5, что на 2-3% выше, чем у лучших одноэтапных детекторов.
По скорости обработки на NVIDIA RTX 4090 лидируют YOLOv8n (343 FPS) и YOLOv7-tiny (267 FPS), что делает их идеальными для задач, требующих обработки видеопотока в реальном времени. RT-DETR-L показал 89 FPS, что достаточно для многих практических применений при сохранении высокой точности. На edge-устройстве Jetson AGX Xavier разрыв в производительности увеличивается: YOLOv8n работает со скоростью 78 FPS, тогда как RT-DETR-L — всего 18 FPS.
По объему параметров YOLOv8s имеет 11.1 млн параметров, тогда как RT-DETR-L — 32.5 млн параметров. Это делает YOLO-архитектуры более подходящими для развертывания на устройствах с ограниченными ресурсами. FLOPS для YOLOv8m составляет 45.3G, для RT-DETR-L — 157.2G, что подтверждает более высокую вычислительную сложность трансформерных архитектур.
5. Практические рекомендации
5.1 Оптимальные архитектуры для различных сценариев
- Мобильные приложения и edge-устройства: YOLOv8n и YOLOv8s обеспечивают оптимальное соотношение скорости и качества.
- Системы безопасности: RT-DETR-M и Swin-T + Cascade R-CNN показывают лучший баланс точности и скорости.
- Автономные транспортные средства: YOLOv8l и RT-DETR-L обеспечивают высокую точность при достаточной скорости обработки.
5.2 Фреймворки для оптимизации
Для эффективного развертывания моделей рекомендуется использовать:
- TensorRT (NVIDIA): ускорение инференса до 4х для моделей YOLO с квантованием INT8
- OpenVINO (Intel): ускорение до 3х для моделей на CPU и VPUs
- ONNX Runtime: кроссплатформенное решение для различных ускорителей
Оптимизация под мобильные устройства включает квантование INT8/FP16 и методы прунинга. Для edge-устройств рекомендуется использование специализированных форматов моделей (TensorRT, OpenVINO).
6. Заключение
Проведенный анализ позволяет сделать следующие выводы:
- Нет универсального решения, оптимального для всех сценариев использования.
- Архитектуры серии YOLO остаются лидерами в области высокоскоростного детектирования, особенно для мобильных устройств.
- Трансформерные архитектуры демонстрируют преимущество в точности для сложных сцен.
- Гибридные подходы показывают наиболее перспективные результаты для балансировки скорости и качества.
Перспективные направления дальнейших исследований включают мультимодальные модели, нейросимволические подходы и использование диффузионных моделей для генерации обучающих данных.
Список литературы
- Ван Ч. И. YOLOv7: обучаемый набор бесплатных методов устанавливает новый стандарт для детекторов объектов в реальном времени [Электронный ресурс] / Ч. И. Ван, А. Бохковский, Х.-Ю. М. Ляо // arXiv preprint arXiv:2207.02696. – 2022. – URL: https://arxiv.org/abs/2207.02696 (дата обращения: 25.12.2025 г.)
- Досовицкий А. Изображение стоит 16×16 слов: трансформеры для масштабируемого распознавания изображений [Электронный ресурс] / А. Досовицкий, Л. Бейер, А. Колесников [и др.] // arXiv preprint arXiv:2010.11929. – 2020. – URL: https://arxiv.org/abs/2010.11929 (дата обращения: 25.12.2025 г.)
- Лю З. Иерархический трансформер для компьютерного зрения с использованием сдвинутых окон / З. Лю, И. Лин, Ю. Као [и др.] // Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). – 2021. – P. 10012–10022. – DOI: 10.1109/ICCV48437.2021.00971
- Руис Н. DreamBooth: тонкая настройка диффузионных моделей текст-в-изображение для генерации с учетом конкретного объекта / Н. Руис, Ю. Ли, В. Джампани [и др.] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). – 2023. – P. 13751–13761
- Хо Дж. Денойзинг-диффузионные вероятностные модели [Электронный ресурс] / Дж. Хо, А. Джейн, П. Эббил // arXiv preprint arXiv:2006.11239. – 2020. – URL: https://arxiv.org/abs/2006.11239 (дата обращения: 25.12.2025 г.)



