
В последние годы объём патентной информации стремительно растёт из-за активного развития науки и инноваций. Ежегодно национальные и международные ведомства публикуют множество документов с техническими решениями, что усложняет поиск аналогов и оценку новизны и требует применения автоматизированных и интеллектуальных методов. «Использование векторных представлений текста на основе моделей типа SBERT позволяет эффективно вычислять технологическое сходство между патентами и применять это для семантического поиска и автоматической классификации» [1, с. 1]. Традиционные системы поиска на основе ключевых слов и классификаций ограничены вариативностью формулировок и многоязычностью баз. «Классические методы поиска патентов всё чаще дополняются новыми техниками семантического поиска и искусственного интеллекта, что обеспечивает более точное выделение релевантных патентных документов» [2, с. 1]. Методы ИИ и обработки естественного языка позволяют выявлять семантическую близость документов, однако текстового поиска недостаточно для точного анализа, что делает важным учёт технических характеристик.
Первым этапом интеллектуального поиска является анализ текстового описания заявки для выявления семантически близких документов, что позволяет находить аналоги даже при различиях формулировок и использовании синонимов. Традиционные методы точного совпадения ключевых слов при этом малоэффективны при больших объёмах данных и многоязычных публикациях. Для формализации задачи текстовые описания преобразуются в числовые векторные представления с использованием BagofWords, TF-IDF или трансформерных моделей, таких как BERT. «Числовые представления, полученные с помощью адаптированных трансформерных моделей, могут применяться для классификации, отслеживания потоков знаний и семантического поиска похожих патентов» [3, с. 1]. Пусть заявка представлена вектором ![]() а документы базы — векторами
а документы базы — векторами ![]() . Семантическая близость определяется с помощью косинусной меры сходства:
. Семантическая близость определяется с помощью косинусной меры сходства:
|
|
(1) |
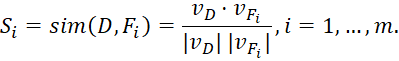
Для отбора релевантных документов используется пороговое значение t, формирующее множество результатов ![]() . Это позволяет регулировать точность и полноту поиска. Трансформеры и многоязычные модели учитывают контекст и смысл текста, создавая основу для анализа технических характеристик. После семантического отбора оцениваются технические признаки изобретения, определяющие его новизну. Каждый признак сравнивается с базой для определения уникальности, которая затем используется для вычисления взвешенной оценки:
. Это позволяет регулировать точность и полноту поиска. Трансформеры и многоязычные модели учитывают контекст и смысл текста, создавая основу для анализа технических характеристик. После семантического отбора оцениваются технические признаки изобретения, определяющие его новизну. Каждый признак сравнивается с базой для определения уникальности, которая затем используется для вычисления взвешенной оценки:
|
|
(6) |
где коэффициенты α и β определяют соотношение влияния уникальности и функциональной важности, а ui отражает редкость признака, а wi — его значимость для сущности изобретения. На основе полученных оценок формируется общий индекс инновационности заявки:
|
|
(2) |
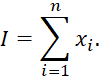
Задача интеллектуального поиска аналогов по техническим характеристикам формализуется как задача максимизации индекса инновационности при условии корректной оценки сходства признаков:
|
|
(3) |
Преимущество такого подхода заключается в выявлении ключевых элементов изобретения, обеспечивающих основной инновационный вклад, даже при частичном совпадении текстов заявок. В сочетании с предварительным текстовым поиском анализ технических характеристик повышает точность выявления патентных аналогов. Использование многоязычных моделей позволяет корректно сравнивать признаки в международных базах, делая метод универсальным. Патентные документы на разных языках требуют семантического многоязычного поиска, так как одно изобретение может описываться разными терминами, а простое совпадение ключевых слов оказывается недостаточным. Пусть входной документ на языке L1 представлен вектором
|
|
(4) |
а база патентов содержит документы на языках L1,L2,…,Lk с векторами
|
|
(5) |
Семантическая близость вычисляется с помощью косинусного сходства:
|
|
(6) |
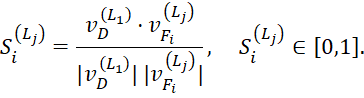
Документ считается релевантным при выполнении условия
|
|
(7) |
а итоговое множество результатов формируется как
|
|
(8) |
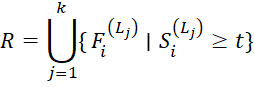
Для повышения точности используются языконезависимые векторные эмбеддинги, полученные с помощью многоязычных моделей, таких как mBERTи XLM-RoBERTa, что позволяет сопоставлять документы в едином семантическом пространстве. Итоговые результаты могут быть ранжированы по степени сходства:
|
|
(9) |
Представленный подход делает поиск независимым от языка документа и, вместе с анализом технических характеристик, повышает полноту и точность интеллектуального поиска в международных патентных базах. Несмотря на успехи, существуют ограничения, связанные с языком и форматом данных. Патенты публикуются в разных форматах (PDF, HTML, DOCX, XML) и на разных языках, что требует многоязычных моделей или машинного перевода. Различия стилей и многозначность терминов снижают точность оценки семантической близости признаков.Семантическая близость признаков:
|
|
(10) |
где zi — признак заявки, fj — признак базы, а sim отражает семантическую близость, что может некорректно оцениваться для редких или контекстно ограниченных терминов. Качество моделей, таких как BERT и RoBERTa, зависит от объёма и сбалансированности обучающих данных, а обработка больших баз требует значительных ресурсов (сложность O(n⋅m)). Модели хорошо выявляют общие признаки, но испытывают трудности с комплексными комбинациями характеристик, что влияет на расчёт индекса инновационности.
|
|
(11) |
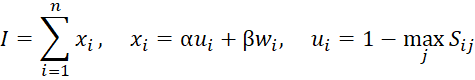
Ошибки на любом этапе могут искажать оценку, а интерпретация трансформеров остаётся сложной, что затрудняет проверку результатов. Преодоление этих ограничений требует расширения обучающих данных, применения многоязычных моделей и оптимизации алгоритмов. Интеллектуальный поиск патентов сочетает текстовый анализ, оценку технических характеристик и многоязычные методы, повышая точность и релевантность. Семантический поиск быстро выявляет документы, анализ признаков оценивает их уникальность, а многоязычные подходы позволяют работать с международными базами без потери смысла. Несмотря на ограничения — разнообразие форматов, языков, неоднозначность терминов и высокая вычислительная нагрузка — комплексный подход ускоряет поиск и анализ патентов, помогая исследователям, разработчикам и компаниям выявлять инновационные решения.
Список литературы
- Бекамири Х., Хайн Д.С., Юровецки Р. PatentSBERTa: гибридная модель на основе SBERT для измерения сходства патентов и их классификации / Х. Бекамири, Д.С. Хайн, Р. Юровецки // TechnologicalForecastingand Social Change. — 2024. — Т. 206. — Статья 123536. — DOI: 10.1016/j.techfore.2024.123536
- Бекамири Х., Хайн Д. С., Юровецки Р. Последовательный поиск патентов с использованием семантики и искусственного интеллекта / Х. Бекамири, Д. С. Хайн, Р. Юровецки. — ScienceDirect, 2022. – с. 9
- Гош, М., Эрхардт, С., Роуз, М. Е., Буунк, Е., Хархофф, Д. PaECTER: обучение представлениям на уровне патентов с использованием трансформеров, информированных цитированием / M. Ghosh, S. Erhardt, M. E. Rose, E. Buunk, D. Harhoff. , 2024. – с. 9



